

 Technology peripheralsAIOne article to understand lidar and visual fusion perception of autonomous driving
Technology peripheralsAIOne article to understand lidar and visual fusion perception of autonomous drivingOne article to understand lidar and visual fusion perception of autonomous driving

2022 is the window period for intelligent driving to move from L2 to L3/L4. More and more automobile manufacturers have begun to deploy higher-level intelligent driving mass production, and the era of automobile intelligence has quietly arrived.
With the technical improvement of lidar hardware, car-grade mass production and cost reduction, high-level intelligent driving functions have promoted the mass production of lidar in the field of passenger cars. A number of models equipped with lidar will be delivered this year, and 2022 is also known as "the first year of lidar on the road."
01 Lidar sensor vs image sensor
Lidar is a sensor used to accurately obtain the three-dimensional position of an object. It is essentially a laser Detection and ranging. With its excellent performance in target contour measurement and universal obstacle detection, it is becoming the core configuration of L4 autonomous driving.
However, the range measurement range of lidar (generally around 200 meters, and the mass production models of different manufacturers have different indicators) results in a perception range that is much smaller than that of image sensors.
And because its angular resolution (generally 0.1° or 0.2°) is relatively small, the resolution of the point cloud is much smaller than that of the image sensor. When sensing at a long distance, it is projected to the target object. The points on the image may be so sparse that they cannot even be imaged. For point cloud target detection, the effective point cloud distance that the algorithm can really use is only about 100 meters.
Image sensors can acquire complex surrounding information at high frame rates and high resolutions, and are cheap. Multiple sensors with different FOV and resolutions can be deployed for different distances and ranges. visual perception, the resolution can reach 2K-4K.
However, the image sensor is a passive sensor with insufficient depth perception and poor ranging accuracy. Especially in harsh environments, the difficulty of completing sensing tasks will increase significantly.
In the face of strong light, low illumination at night, rain, snow, fog and other weather and light environments, intelligent driving has high requirements on sensor algorithms. Although lidar is not sensitive to the influence of ambient light, the distance measurement will be greatly affected by waterlogged roads, glass walls, etc.
It can be seen that lidar and image sensors each have their own advantages and disadvantages. Most high-level intelligent driving passenger cars choose to integrate different sensors to complement each other's advantages and integrate redundancy.
Such a fused sensing solution has also become one of the key technologies for high-level autonomous driving.
02 Point cloud and image fusion perception based on deep learning
The fusion of point cloud and image belongs to Multi-Sensor Fusion ,MSF) technology field, there are traditional random methods and deep learning methods, which are mainly divided into three levels according to the abstraction level of information processing in the fusion system:
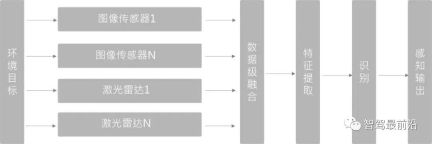
Data layer fusion (Early Fusion)
First fuse the sensor observation data, and then extract features from the fused data for identification. In 3D target detection, PointPainting (CVPR20) adopts this method. The PointPainting method first performs semantic segmentation on the image, maps the segmented features to the point cloud through a point-to-image pixel matrix, and then "draws the point" The point cloud is sent to the 3D point cloud detector to perform regression on the target Box.
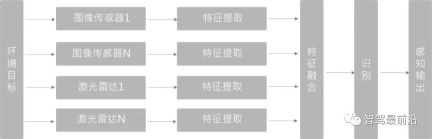
##Feature layer fusion (Deep Fusion)
First extract the natural data features from the observation data provided by each sensor, and then fuse these features for identification. In the fusion method based on deep learning, this method uses feature extractors for both the point cloud and the image branch. The networks of the image branch and the point cloud branch are fused semantically level by level in the forward feedback level to achieve multi-scale information. semantic fusion.
The feature layer fusion method based on deep learning has high requirements for spatiotemporal synchronization between multiple sensors. Once the synchronization is not good, it will directly affect the effect of feature fusion. At the same time, due to differences in scale and viewing angle, it is difficult for the feature fusion of LiDAR and images to achieve the effect of 1 1>2.
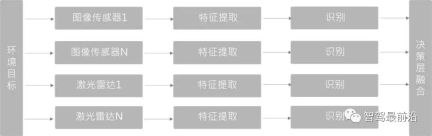
Decision-making layer fusion (Late Fusion)
Compared with the first two, it is the least complex fusion method. It does not fuse at the data layer or feature layer, but is a target-level fusion. Different sensor network structures do not affect each other and can be trained and combined independently.
Since the two types of sensors and detectors fused at the decision-making layer are independent of each other, once a sensor fails, sensor redundancy processing can still be performed, and the engineering robustness is better.
With the continuous iteration of lidar and visual fusion perception technology, as well as the continuous accumulation of knowledge scenarios and cases, it will More and more full-stack converged computing solutions are emerging to bring a safer and more reliable future for autonomous driving.
The above is the detailed content of One article to understand lidar and visual fusion perception of autonomous driving. For more information, please follow other related articles on the PHP Chinese website!

 Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AM
Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AMScientists have extensively studied human and simpler neural networks (like those in C. elegans) to understand their functionality. However, a crucial question arises: how do we adapt our own neural networks to work effectively alongside novel AI s
 New Google Leak Reveals Subscription Changes For Gemini AIApr 27, 2025 am 11:08 AM
New Google Leak Reveals Subscription Changes For Gemini AIApr 27, 2025 am 11:08 AMGoogle's Gemini Advanced: New Subscription Tiers on the Horizon Currently, accessing Gemini Advanced requires a $19.99/month Google One AI Premium plan. However, an Android Authority report hints at upcoming changes. Code within the latest Google P
 How Data Analytics Acceleration Is Solving AI's Hidden BottleneckApr 27, 2025 am 11:07 AM
How Data Analytics Acceleration Is Solving AI's Hidden BottleneckApr 27, 2025 am 11:07 AMDespite the hype surrounding advanced AI capabilities, a significant challenge lurks within enterprise AI deployments: data processing bottlenecks. While CEOs celebrate AI advancements, engineers grapple with slow query times, overloaded pipelines, a
 MarkItDown MCP Can Convert Any Document into Markdowns!Apr 27, 2025 am 09:47 AM
MarkItDown MCP Can Convert Any Document into Markdowns!Apr 27, 2025 am 09:47 AMHandling documents is no longer just about opening files in your AI projects, it’s about transforming chaos into clarity. Docs such as PDFs, PowerPoints, and Word flood our workflows in every shape and size. Retrieving structured
 How to Use Google ADK for Building Agents? - Analytics VidhyaApr 27, 2025 am 09:42 AM
How to Use Google ADK for Building Agents? - Analytics VidhyaApr 27, 2025 am 09:42 AMHarness the power of Google's Agent Development Kit (ADK) to create intelligent agents with real-world capabilities! This tutorial guides you through building conversational agents using ADK, supporting various language models like Gemini and GPT. W
 Use of SLM over LLM for Effective Problem Solving - Analytics VidhyaApr 27, 2025 am 09:27 AM
Use of SLM over LLM for Effective Problem Solving - Analytics VidhyaApr 27, 2025 am 09:27 AMsummary: Small Language Model (SLM) is designed for efficiency. They are better than the Large Language Model (LLM) in resource-deficient, real-time and privacy-sensitive environments. Best for focus-based tasks, especially where domain specificity, controllability, and interpretability are more important than general knowledge or creativity. SLMs are not a replacement for LLMs, but they are ideal when precision, speed and cost-effectiveness are critical. Technology helps us achieve more with fewer resources. It has always been a promoter, not a driver. From the steam engine era to the Internet bubble era, the power of technology lies in the extent to which it helps us solve problems. Artificial intelligence (AI) and more recently generative AI are no exception
 How to Use Google Gemini Models for Computer Vision Tasks? - Analytics VidhyaApr 27, 2025 am 09:26 AM
How to Use Google Gemini Models for Computer Vision Tasks? - Analytics VidhyaApr 27, 2025 am 09:26 AMHarness the Power of Google Gemini for Computer Vision: A Comprehensive Guide Google Gemini, a leading AI chatbot, extends its capabilities beyond conversation to encompass powerful computer vision functionalities. This guide details how to utilize
 Gemini 2.0 Flash vs o4-mini: Can Google Do Better Than OpenAI?Apr 27, 2025 am 09:20 AM
Gemini 2.0 Flash vs o4-mini: Can Google Do Better Than OpenAI?Apr 27, 2025 am 09:20 AMThe AI landscape of 2025 is electrifying with the arrival of Google's Gemini 2.0 Flash and OpenAI's o4-mini. These cutting-edge models, launched weeks apart, boast comparable advanced features and impressive benchmark scores. This in-depth compariso


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Atom editor mac version download
The most popular open source editor

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

Dreamweaver CS6
Visual web development tools

SublimeText3 Chinese version
Chinese version, very easy to use

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

