

 Operation and MaintenanceSafetyTo end this topic: Is it true that operation and maintenance jobs can no longer be done?
Operation and MaintenanceSafetyTo end this topic: Is it true that operation and maintenance jobs can no longer be done?

Last Friday, Ma Chi and Lai Wei had an online exchange. The topic was, are operation and maintenance positions really no longer available? As the host, I am both the igniter and the facilitator :) I benefited a lot from listening to the two veterans share some of their respective opinions. Make sure to record it today so as not to forget it. It is a review of the live broadcast.
About the tool platform
The tool platform will replace part of the labor force. This is actually obvious and needs no further explanation.
But who will build the tool platform? This is worth checking out. Monitoring systems, CI/CD platforms, chaos engineering platforms, middleware services, etc. are all Platforms and are built by Platform Engineer, referred to as PE. PE is obviously divided into many groups, and each PE group is responsible for a limited number of platforms. These scattered PE teams can be organized into a large team, such as the infrastructure team, or they can be split into multiple teams. For example, the PE team related to engineering performance can be placed in one department (such as the performance engineering department), database, and big data. The relevant PE teams are placed in one department (such as the data department), and the PE teams related to stability assurance are placed in one department (such as the operation and maintenance department).
The division of this organization may be different in different companies, but the relationship is not very important. The key is how the PE team should carry out its work? The core of the PE team must do the following:
- Build a useful platform and allow the business R&D team to provide self-service
- The platform must accumulate best practices. The platform needs to satisfy the business, but it must also have industry best practices. In theory, if business needs conflict with industry best practices, industry best practices should prevail as much as possible. If it is really impossible to do so in the short term, it should also formulate We must implement the plan step by step and strive to achieve it in the future. Otherwise, if there are more and more individual things and anti-pattern things, the Platform side will become more and more uncomfortable. In the end, it will be overwhelmed and it will be overthrown and started all over again. ##We must find ways to use the platform to implement specifications instead of using rules and regulations. Ma Chi gave a good example. They have a specification that requires business programs not to use local disks to store state data. They do not take this as a red line. The decree was promulgated, but it was clearly told to the business side that the container would be restarted regularly to allow the container to drift! In fact, people who have used AWS should know that AWS virtual machines sometimes restart inexplicably. It is the responsibility of application developers to provide highly available applications for unreliable infrastructure
- Requires COE ( Domain experts) to guide the evolution of the Platform, because architects who are good at databases may not be good at Hadoop, architects who are good at Hadoop may not be good at observability systems, and architects who are good at observability systems may not be good at chaos engineering.
- But not all Platforms are created overnight. What should we do if we don’t have these Platforms yet? The company should recruit a COE first, and let the COE serve as a business consultant while building the Platform's capabilities. The business is developing rapidly, and self-development of the Platform is too slow. It can also seek solutions from external suppliers. Even the COE itself can seek external solutions, depending on the situation.
About external suppliers
Everyone will intuitively feel that: European and American companies are more willing to purchase SaaS services, while domestic companies are more willing to build their own services based on open source. Is it because the domestic company philosophy is not good? Not really. The core problem is the lack of reliable ToB companies and products in many domestic fields. Imagine if a ToB company could provide Party A with:
Excellent, advanced methodology- Stable, easy-to-use products
- Excellent, A stable customer success team helps customers better implement best practices
- In terms of price, it is cheaper than Party A’s own recruitment of personnel and self-research
- As long as the CXO’s brain is not broken, it will definitely Will choose to bring in such external suppliers. But is there such a ToB company? This is a big question mark. We created Kuaimao Nebula to provide customers with observability products and strive to become such a supplier. I hope ToB colleagues in the industry will work together!
Expanding on the issue of career selection, although there may not be a good supplier in a certain segment now, what about three years from now? What about 5 years from now? Have foreign countries already taken the lead? Are there any suppliers with good potential in China? If you already have it, brother, do you still dare to continue to devote yourself to this niche field? Should we have made some plans in advance?
Of course, we are usually too optimistic or too pessimistic about our future estimates. Our estimates of time are usually either too advanced or too late. That's right, brother, it depends on how you judge.
About emergency fault handling
Should OnCall fault response be handled by R&D? Or operation and maintenance? This question is very interesting. Ma Chi believes that 80% of online faults are related to changes. Changes are made by R&D, and R&D is obviously more familiar with them. Let R&D respond to OnCall faults, which means that R&D can respond faster to 80% of the problems.
Business development is like this. Database changes, basic network changes, and access layer changes are all the same. It seems more reasonable for the person who makes the change to respond to the fault alarm of his own service.
Actually, this depends on two premises:
- Monitoring and observability are done well enough, and problems caused by changes can be discovered in time through this platform. Come on, everyone, I hope every company has a complete observability system
- Problems introduced by changes are reflected immediately. If some problems introduced by changes only appear after a week, it will be difficult for the person who made the change to doubt themselves.
In fact, we can treat it in two situations. The service stability monitoring after the change is the responsibility of the person who made the change. Daily OnCall is another scenario and should be treated separately. So who should do the daily OnCall? It should be those who can directly participate in fault location and stop loss. The reason is obvious. If the OnCall person receives an alarm and needs to contact others, then the timeliness of the fault stop loss will be too poor.
So first of all, the alarms should be processed in different categories, and different people will OnCall different alarms. It is unreasonable to give all alarms to R&D or to operation and maintenance. This absolute approach is unreasonable.
About change release
There is a consensus on the ultimate goal, which is to allow business research and development to release versions freely, but we also hope to control it, hope to release safely, and hope to protect the business while releasing. Continuity. This puts extremely high requirements on the CI/CD system.
If you don't care, changing the bottom layer of the system is just a matter of running a script in batches on a batch of machines. But after adding the above requirements, it becomes much more difficult and becomes a systematic project.
On the business research and development side, it is necessary to make observable points and monitor the system to detect problems in time, and even automatically block the release process after an alarm. There needs to be some means of blue-green release and canary release, and some automatic code scanning and security scanning capabilities are needed. The tool system is incomplete. It is inappropriate to blindly require R&D to ensure that changes can be rolled back and that changes are safe. The level of CI/CD capabilities can basically tell the technical strength of the company.
If your company still provides R&D with bills of lading for operation and maintenance, and operation and maintenance operates online, you should consider whether this is reasonable. Of course, the above approach is more Internet-oriented and may not be suitable for all companies. This live broadcast only provides an idea, and you have to consider it yourself.
Of course, how to achieve this ideal situation? How should we go about it step by step before this ideal situation is achieved? The issue of time was not discussed in the live broadcast. If the company's business is suitable for running on Kubernetes, it is relatively easy to build such a system using Kubernetes, and you can take action as soon as possible. If the company's business must run in a physical machine or virtual machine environment, then first create a unified change release platform, and then fill in the gaps and gradually improve them.
About cost optimization
The two guests didn’t talk much, but everyone was very cautious about this matter. Remind everyone:
- People are more expensive than hardware. Never do something that costs 50 million in manpower and saves 40 million in hardware costs.
- Leave enough redundancy for the business Spare computing power, if the resources are too tight and the budget for the batch is not approved, if the capacity causes a failure, the customer experience will be damaged, the public opinion will be negative, and the gain will outweigh the loss.
- The ridiculous example is, buying with 30 million , in order to save the hardware cost of 3 million yuan, I can’t resist the volume, so I really lost it
Summary
At this stage, the platform system is not so complete yet, use the self-service Platform COE The architecture of BP (Business Partner) to build an operation and maintenance system seems to be reliable and implementable. In the future, when the Platform is good enough, BP manpower can be reduced (BP has gradually gained the ability to do COE). If the Platform continues to be complete, COE can continue to be reduced. After that, well, operation and maintenance and R&D may not be needed.
The above is the detailed content of To end this topic: Is it true that operation and maintenance jobs can no longer be done?. For more information, please follow other related articles on the PHP Chinese website!

 Spring Boot Actuator端点大揭秘:轻松监控你的应用程序Jun 09, 2023 pm 10:56 PM
Spring Boot Actuator端点大揭秘:轻松监控你的应用程序Jun 09, 2023 pm 10:56 PM一、SpringBootActuator端点简介1.1什么是Actuator端点SpringBootActuator是一个用于监控和管理SpringBoot应用程序的子项目。它提供了一系列内置的端点(Endpoints),这些端点可以用于查看应用程序的状态、运行情况和运行指标。Actuator端点可以以HTTP、JMX或其他形式暴露给外部系统,便于运维人员对应用程序进行监控、诊断和管理。1.2端点的作用和功能Actuator端点主要用于实现以下功能:提供应用程序的健康检查,包括数据库连接、缓存、
 运维工作十多年,无数个瞬间、我觉得自己还是个小白...Jun 09, 2023 pm 09:53 PM
运维工作十多年,无数个瞬间、我觉得自己还是个小白...Jun 09, 2023 pm 09:53 PM曾几何时,当我还是一名初出茅庐的计算机专业应届生的时候,在招聘网站上浏览了很多招聘贴,眼花缭乱的技术岗位让我摸不着头脑:研发工程师、运维工程师、测试工程师...大学期间专业课马马虎虎,更谈不上有什么技术视野,对于具体从事那个技术方向并没有什么明确的想法。直到一位学长对我说:“做运维吧,做运维不用天天写代码,会玩Liunx就行!比做开发轻松多了!”我选择了相信......入行十多年,吃过很多苦,背了很多锅,弄死过服务器,经历过部门裁员,如果有人现在跟我说做运维比开发简单,那我会
 Spring Cloud微服务架构部署与运维Jun 23, 2023 am 08:19 AM
Spring Cloud微服务架构部署与运维Jun 23, 2023 am 08:19 AM随着互联网的快速发展,企业级应用的复杂度日益增加。针对这种情况,微服务架构应运而生。它以模块化、独立部署、可扩展性高等特点,成为当今企业级应用开发的首选。作为一种优秀的微服务架构,SpringCloud在实际应用中展现出了极大的优势。本文将介绍SpringCloud微服务架构的部署与运维。一、部署SpringCloud微服务架构SpringCloud
 运维要不要学golang吗Jul 17, 2023 pm 01:27 PM
运维要不要学golang吗Jul 17, 2023 pm 01:27 PM运维不要学golang,其原因是:1、golang主要被用于开发高性能和并发性能要求较高的应用程序;2、运维工程师通常使用的工具和脚本语言已经能够满足大部分的管理和维护需求;3、学习golang需要一定的编程基础和经验;4、运维工程师的主要目标是确保系统的稳定和高可用性,而不是开发应用程序。
 途游邹轶:中小公司的运维怎么做?Jun 09, 2023 pm 01:56 PM
途游邹轶:中小公司的运维怎么做?Jun 09, 2023 pm 01:56 PM通过采访和约稿的方式,请运维领域老炮输出深刻洞见,共同碰撞,以期形成一些先进的共识,推动行业更好得前进。这一期我们邀请到的是邹轶,途游游戏运维总监,邹总经常戏称自己是世界500万强企业的运维代表,可见内心中是觉得中小公司的运维建设思路和大型企业是有差别的,今天我们带着几个问题,来请邹总分享一下他的中小公司研运一体化之路。这里是接地气、有高度的《运维百家讲坛》第6期,开讲!问题预览途游是游戏公司,您觉得游戏运维有哪些独特性?面临的最大运维挑战是什么?您又是如何解决这些挑战的?游戏运维的人
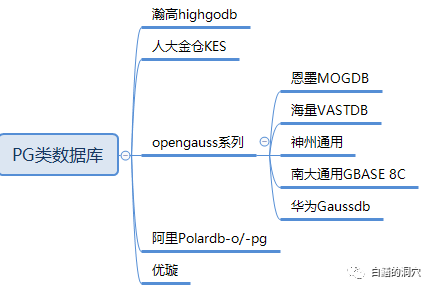 PG数据库运维工具要覆盖哪些能力Jun 08, 2023 pm 06:56 PM
PG数据库运维工具要覆盖哪些能力Jun 08, 2023 pm 06:56 PM过节前我和PG中国社区合作搞了一个关于如何使用D-SMART来运维PG数据库的线上直播,正好我的一个金融行业的客户听了我的介绍,打电话过来聊了聊。他们正在做数据库信创的选型,也试用了多个国产数据库,最后他们准备选择TDSQL。当时我觉得有点意外,他们从2020年就开始在做国产数据库选型,不过好像最初使用TDSQL后的感受并不太好。后来经过沟通才了解到,他们刚开始使用TDSQL的分布式数据库,发现对研发要求太高,所以后来就全部选择TDSQL的集中式MYSQL实例,用下来发现挺好用的。整个数据库云
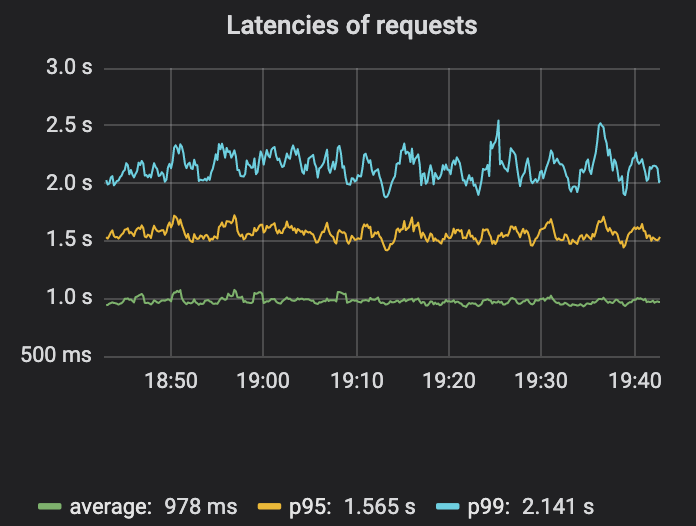 Uber实践:运维大型分布式系统的一些心得Jun 09, 2023 pm 04:53 PM
Uber实践:运维大型分布式系统的一些心得Jun 09, 2023 pm 04:53 PM本文是Uber的工程师GergelyOrosz的文章,原文地址在:https://blog.pragmaticengineer.com/operating-a-high-scale-distributed-system/在过去的几年里,我一直在构建和运营一个大型分布式系统:优步的支付系统。在此期间,我学到了很多关于分布式架构概念的知识,并亲眼目睹了高负载和高可用性系统运行的挑战(一个系统远远不是开发完了就完了,线上运行的挑战实际更大)。构建系统本身是一项有趣的工作。规划系统如何处理10x/100
 什么是可观测性?初学者需要知道的一切Jun 08, 2023 pm 02:42 PM
什么是可观测性?初学者需要知道的一切Jun 08, 2023 pm 02:42 PM可观测性一词来源于工程领域,近年来在软件开发领域也日益流行。简而言之,可观测性是指根据外部输出以了解系统内部状态的能力。IBM对可观测性的定义为:通常,可观测性是指基于对复杂系统外部输出的了解就能够了解其内部状态或状况的程度。系统越可观测,定位性能问题根本原因的过程就能越快速且准确,而无需进行额外的测试或编码。在云计算中,可观测性还指对分布式应用系统及支撑其运行的基础设施的数据进行聚合、关联和分析的软件工具和实践,以便对应用系统进行更有效地监控、故障排除和调试,从而实现客户体验优化、服务水平协议


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Atom editor mac version download
The most popular open source editor

Dreamweaver CS6
Visual web development tools

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

Zend Studio 13.0.1
Powerful PHP integrated development environment

