


Java has always been one of the most widely used languages in the industry, and big data and distributed storage technology are new technologies that have emerged with the rapid growth of data scale. In this article, we will explore big data and distributed storage technologies in Java.
1. What is big data?
With the increasing popularity of the Internet and the continuous development of data collection technology, the scale of data in fields such as business data, social networks, and the Internet of Things has reached hundreds of billions, trillions, or even more. These Massive data is called big data.
Big data mainly has the following characteristics:
1. Huge amount of data: The amount of data processed is often at the PB level, which cannot be afforded by a single machine and requires the use of distributed storage technology.
2. Complex types of data: There are many types of data, including structured data, semi-structured data and unstructured data, such as text, images, audio, video, etc.
3. Fast data processing speed: A large amount of data needs to be processed quickly and valuable information extracted in a very short time.
2. Big Data and Distributed Storage Technology
Traditional data storage and processing technology has brought unbearable high costs and low efficiency when faced with the challenge of large data volumes. The application of distributed storage and computing technology can quickly build massive data storage and real-time processing and analysis systems, solving the bottleneck problem of traditional systems.
Distributed storage technology can not only solve data storage and expansion problems, but also meet the needs of high concurrent data access. In distributed storage, data is split into multiple copies and stored on different nodes, and data reliability and high availability are ensured through technologies such as data replication and data partitioning.
Distributed computing is built on the basis of distributed storage. Data is transmitted to various nodes through the network, different tasks are executed in parallel on different nodes, and finally the results are integrated together for completion. Distributed computing can greatly increase the speed of data processing and can also meet the needs of real-time computing of big data.
In Java, Hadoop and Spark are two widely used big data processing frameworks. Hadoop provides the distributed file system HDFS and the distributed computing framework MapReduce, which can efficiently store and process large-scale data. Spark is a high-performance computing framework based on Hadoop that supports multiple computing models and has efficient memory computing capabilities.
3. Commonly used big data technologies and related tools in Java
In Java, the ecosystem based on Hadoop and Spark covers many commonly used big data technologies and related tools. Let’s take a look at Introducing several commonly used technologies:
- Hadoop YARN: As one of the foundations of the Hadoop distributed computing framework, it manages and allocates computing resources and runs computing tasks through MapReduce.
- Apache Hive: A data warehouse tool built on Hadoop that can process structured data and supports SQL query language.
- Apache Pig: Another data warehouse tool based on Hadoop, which can support user-defined functions and scripts, and provides a rich operator and function library.
- Apache Kafka: A high-performance message queue system that supports real-time data processing and distributed data transmission, and can provide efficient message delivery capabilities for big data applications.
- Apache Cassandra: A distributed column-oriented NoSQL database with high availability, high scalability and massive data storage capabilities.
4. Summary
Big data and distributed storage technology are important areas that Java developers cannot ignore. By understanding the concepts, characteristics and related tools of big data and distributed storage technology, we can better understand their application scenarios and importance. I hope this article can provide you with some help.
The above is the detailed content of Big data and distributed storage technology in Java. For more information, please follow other related articles on the PHP Chinese website!

 在 Microsoft Excel 中如何创建数据透视表Apr 22, 2023 pm 12:10 PM
在 Microsoft Excel 中如何创建数据透视表Apr 22, 2023 pm 12:10 PM当您拥有大量数据时,分析数据通常会变得越来越困难。但真的必须如此吗?MicrosoftExcel提供了一个令人惊叹的内置功能,称为数据透视表,可用于轻松分析庞大的数据块。它们可用于通过创建您自己的自定义报告来有效地汇总您的数据。它们可用于自动计算列的总和,可以对其应用过滤器,可以对其中的数据进行排序等。可以对数据透视表执行的操作以及如何使用数据透视表为了缓解您的日常excel障碍是无止境的。继续阅读,了解如何轻松创建数据透视表并了解如何有效组织它。希望你喜欢阅读这篇文章。第1节:什么是数据透视
 如何阻止 Apple 在 iPhone 上收集诊断和使用数据Apr 16, 2023 pm 09:25 PM
如何阻止 Apple 在 iPhone 上收集诊断和使用数据Apr 16, 2023 pm 09:25 PM苹果以其对用户隐私的承诺而闻名。当您购买iPhone或Mac时,您知道您正在投资一家承诺保护您的数据的公司的产品。这在我们这个时代非常重要——因为我们越来越多地将更多的个人信息存储在这些设备上。我们使用的大多数设备都会收集使用数据以改进相应的产品和服务。例如,当应用程序在您的手机上崩溃时,可以通知开发人员以帮助他们查明此错误的原因。虽然这些数据通常是匿名的,但一些用户不喜欢让公司收集他们的日志。此外,通过共享这些诊断信息,您的设备会将它们上传到公司的服务器。这可能会耗尽您的(有限)数据计划和部分
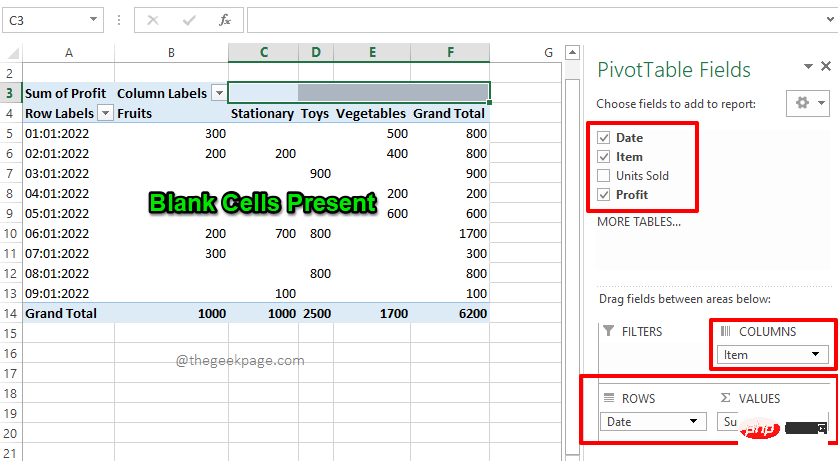 如何用零替换 Excel 数据透视表中的空白单元格Apr 15, 2023 am 11:52 AM
如何用零替换 Excel 数据透视表中的空白单元格Apr 15, 2023 am 11:52 AM了COLUMNS部分下的字段Item、ROWS部分下的字段Date和VALUES部分下的Profit字段。注意:如果您需要有关数据透视表如何工作以及如何有效地创建数据透视表的更多信息,请参阅我们的文章如何在MicrosoftExcel中创建数据透视表。因此,根据我的选择,我的数据透视表生成如下面的屏幕截图所示,使其成为我想要的完美摘要报告。但是,如果您查看数据透视表,您会发现我的数据透视表中有一些空白单元格。现在,让我们在接下来的步骤中将它们替换为零。第6步:要用零替换空白单元格,首先右键单击数
 AI 算法在大数据治理中的应用Apr 12, 2023 pm 01:37 PM
AI 算法在大数据治理中的应用Apr 12, 2023 pm 01:37 PM本文主要分享 Datacake 在大数据治理中,AI 算法的应用经验。本次分享分为五大部分:第一部分阐明大数据与 AI 的关系,大数据不仅可以服务于 AI,也可以使用 AI 来优化自身服务,两者是互相支撑、依赖的关系;第二部分介绍利用 AI 模型综合评估大数据任务健康度的应用实践,为后续开展数据治理提供量化依据;第三部分介绍利用 AI 模型智能推荐 Spark 任务运行参数配置的应用实践,实现了提高云资源利用率的目标;第四部分介绍在 SQL 查询场景中,由模型智能推荐任务执行引擎的实践;第五部分

 如何在 Microsoft Excel 图表中添加和自定义数据标签?May 07, 2023 pm 04:22 PM
如何在 Microsoft Excel 图表中添加和自定义数据标签?May 07, 2023 pm 04:22 PMMicrosoft Excel有许多至今令人们惊叹的功能。人们每天都会学到一些新东西。今天,我们将了解如何在Excel图表中添加和自定义数据标签。Excel图表包含大量数据,一眼看懂图表可能具有挑战性。使用数据标签是指出重要信息的好方法。数据标签可以用作柱形图或条形图的一部分。当您创建饼图时,它甚至可以用作标注。添加数据标签为了展示如何添加数据标签,我们将以饼图为例。虽然大多数人使用图例来显示饼图中的内容,但数据标签的效率要高得多。要添加数据标签,请创建饼图。打开它,然后单击显示图表设计
 腾讯广告模型基于"太极"的训练成本优化实践Apr 14, 2023 pm 06:46 PM
腾讯广告模型基于"太极"的训练成本优化实践Apr 14, 2023 pm 06:46 PM近年来,大数据加大模型成为了AI领域建模的标准范式。在广告场景,大模型由于使用了更多的模型参数,利用更多的训练数据,模型具备了更强的记忆能力和泛化能力,为广告效果向上提升打开了更大的空间。但是大模型在训练过程中所需要的资源也是成倍的增长,存储以及计算上的压力对机器学习平台都是巨大的挑战。腾讯太极机器学习平台持续探索降本增效方案,在广告离线训练场景利用混合部署资源大大降低了资源成本,每天为腾讯广告提供50W核心廉价混合部署资源,帮助腾讯广告离线模型训练资源成本降低30%,同时通过一系列优化手段使得
 如何使用 Go 语言进行大数据分析?Jun 11, 2023 am 11:11 AM
如何使用 Go 语言进行大数据分析?Jun 11, 2023 am 11:11 AM随着数据规模逐渐增大,大数据分析变得越来越重要。而Go语言作为一门快速、轻量级的编程语言,也成为了越来越多数据科学家和工程师的选择。本文将介绍如何使用Go语言进行大数据分析。数据采集在开始大数据分析之前,我们需要先采集数据。Go语言有很多包可以用于数据采集,例如“net/http”、“io/ioutil”等。通过这些包,我们可以从网站、API、日志


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

SublimeText3 English version
Recommended: Win version, supports code prompts!

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)

