
 Technology peripheralsAIOpen-world understanding of 3D point clouds, classification, retrieval, subtitles and image generation
Technology peripheralsAIOpen-world understanding of 3D point clouds, classification, retrieval, subtitles and image generationOpen-world understanding of 3D point clouds, classification, retrieval, subtitles and image generation

Input the three-dimensional shapes of a rocking chair and a horse. What can you get?


##Wooden cart plus horse? Get a carriage and an electric horse; a banana and a sailboat? Get a banana sailboat; eggs plus deck chairs? Get the egg chair.

Researchers from UCSD, Shanghai Jiao Tong University, and Qualcomm teams have proposed the latest three-dimensional representation model OpenShape, making it possible to understand the open world of three-dimensional shapes.
- Paper address: https://arxiv.org/pdf/2305.10764.pdf
- Project homepage: https://colin97.github.io/OpenShape/
- Interactive demo: https://huggingface.co/spaces/OpenShape/openshape-demo
- Code address: https://github.com/Colin97/OpenShape_code
By learning a native encoder of 3D point clouds on multi-modal data (point cloud - text - image), OpenShape builds a representation space of 3D shapes and aligns it with CLIP's text and image spaces. Thanks to large-scale and diverse 3D pre-training, OpenShape achieves open-world understanding of 3D shapes for the first time, supporting zero-shot 3D shape classification, multi-modal 3D shape retrieval (text/image/point cloud input), and subtitles of 3D point clouds. Cross-modal tasks such as image generation and 3D point cloud-based image generation.
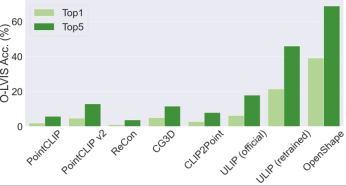
Three-dimensional shape zero-shot classification
OpenShape’s top3 and top5 accuracy on ModelNet40 reached 96.5% and 98.0% respectively.
Multimodal 3D shape retrieval
With OpenShape’s multimodal representation, users can perform 3D shape retrieval on image, text, or point cloud input. Study the retrieval of 3D shapes from integrated datasets by computing the cosine similarity between the input representation and the 3D shape representation and finding kNN.

The above figure shows the input image and two retrieved 3D shapes. Three-dimensional shape retrieval of text input The above image shows the input text and the retrieved three-dimensional shape. OpenShape learns a wide range of visual and semantic concepts, enabling fine-grained subcategory (first two lines) and attribute control (last two lines, such as color, shape, style, and their combinations). 3D shape retrieval of 3D point cloud input The above figure shows the input 3D point cloud and two retrieved 3D shapes. 


#Double input three-dimensional shape retrieval
The above figure takes two 3D shapes as input and uses their OpenShape representations to retrieve the 3D shape that is closest to both inputs at the same time. The retrieved shape cleverly combines semantic and geometric elements from both input shapes.
Three-dimensional shape-based text and image generationBecause OpenShape's three-dimensional shape representation is aligned with CLIP's image and text representation space, they can be used with many based on Derived models from CLIP are combined to support a variety of cross-modal applications.

Subtitle generation of three-dimensional point cloud
By combining with the ready-made image subtitle model (ClipCap), OpenShape implements subtitle generation for 3D point clouds.

Image generation based on three-dimensional point cloud
By combining with the ready-made text-to-image diffusion model (Stable unCLIP), OpenShape implements image generation based on 3D point clouds (supporting optional text hints).

##More examples of image generation based on three-dimensional point clouds Training details
Multimodal representation alignment based on contrastive learning: OpenShape trains a 3D native encoder that will The 3D point cloud is used as input to extract the representation of the 3D shape. Following previous work, we exploit multimodal contrastive learning to align with CLIP's image and text representation spaces. Unlike previous work, OpenShape aims to learn a more general and scalable joint representation space. The focus of the research is mainly to expand the scale of 3D representation learning and address the corresponding challenges, so as to truly realize 3D shape understanding in the open world.
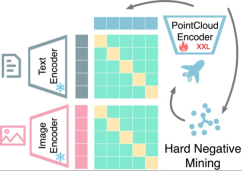
Integrating multiple 3D shape datasets: Since the scale and diversity of training data play a crucial role in learning large-scale 3D shape representations, the study integrated four Training on the currently largest publicly available 3D dataset. As shown in the figure below, the training data studied contains 876,000 training shapes. Among the four datasets, ShapeNetCore, 3D-FUTURE, and ABO contain high-quality human-verified 3D shapes, but only cover a limited number of shapes and dozens of categories. The Objaverse dataset is a recently released 3D dataset that contains significantly more 3D shapes and covers a more diverse object class. However, the shapes in the Objaverse are mainly uploaded by Internet users and have not been manually verified. Therefore, the quality is uneven and the distribution is extremely uneven, requiring further processing.

Text filtering and enrichment: Study found only between 3D shapes and 2D images Applying contrastive learning is insufficient to drive alignment of 3D shape and text spaces, even when trained on large-scale datasets. Research speculates that this is due to the inherent domain gap in CLIP's language and image representation spaces. Therefore, research needs to explicitly align 3D shapes with text. However, text annotations from original 3D data sets often face problems such as missing, wrong, or rough and single content. To this end, this paper proposes three strategies to filter and enrich text to improve the quality of text annotation: text filtering using GPT-4, subtitle generation and image retrieval of 2D renderings of 3D models.

#The study proposed three strategies to automatically Filter and enrich noisy text in raw datasets.

##Text filtering and enrichment examples
In each example, the left section shows the thumbnail, original shape name, and GPT-4 filtered results. The upper right part shows the image captions from the two captioning models, while the lower right part shows the retrieved image and its corresponding text.
Expand the three-dimensional backbone network. Since previous work on 3D point cloud learning mainly targeted small-scale 3D data sets like ShapeNet, these backbone networks may not be directly applicable to our large-scale 3D training, and the scale of the backbone network needs to be expanded accordingly. The study found that different 3D backbone networks exhibited different behaviors and scalability when trained on data sets of different sizes. Among them, PointBERT based on Transformer and SparseConv based on three-dimensional convolution show more powerful performance and scalability, so they were selected as the three-dimensional backbone network.
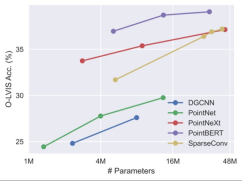
When scaling up the size of the 3D backbone model on the integrated dataset, the Performance and scalability comparison.
Difficult Negative Example Mining: The ensemble dataset of this study exhibits a high degree of class imbalance. Some common categories, like architecture, may occupy tens of thousands of shapes, while many other categories, like walruses and wallets, are underrepresented with only a few dozen or even fewer shapes. Therefore, when batches are randomly constructed for contrastive learning, shapes from two easily confused categories (e.g., apples and cherries) are unlikely to appear in the same batch to be contrasted. To this end, this paper proposes an offline difficult negative example mining strategy to improve training efficiency and performance.
Welcome to try the interactive demo on HuggingFace.The above is the detailed content of Open-world understanding of 3D point clouds, classification, retrieval, subtitles and image generation. For more information, please follow other related articles on the PHP Chinese website!

 A Business Leader's Guide To Generative Engine Optimization (GEO)May 03, 2025 am 11:14 AM
A Business Leader's Guide To Generative Engine Optimization (GEO)May 03, 2025 am 11:14 AMGoogle is leading this shift. Its "AI Overviews" feature already serves more than one billion users, providing complete answers before anyone clicks a link.[^2] Other players are also gaining ground fast. ChatGPT, Microsoft Copilot, and Pe
 This Startup Is Using AI Agents To Fight Malicious Ads And Impersonator AccountsMay 03, 2025 am 11:13 AM
This Startup Is Using AI Agents To Fight Malicious Ads And Impersonator AccountsMay 03, 2025 am 11:13 AMIn 2022, he founded social engineering defense startup Doppel to do just that. And as cybercriminals harness ever more advanced AI models to turbocharge their attacks, Doppel’s AI systems have helped businesses combat them at scale— more quickly and
 How World Models Are Radically Reshaping The Future Of Generative AI And LLMsMay 03, 2025 am 11:12 AM
How World Models Are Radically Reshaping The Future Of Generative AI And LLMsMay 03, 2025 am 11:12 AMVoila, via interacting with suitable world models, generative AI and LLMs can be substantively boosted. Let’s talk about it. This analysis of an innovative AI breakthrough is part of my ongoing Forbes column coverage on the latest in AI, including
 May Day 2050: What Have We Left To Celebrate?May 03, 2025 am 11:11 AM
May Day 2050: What Have We Left To Celebrate?May 03, 2025 am 11:11 AMLabor Day 2050. Parks across the nation fill with families enjoying traditional barbecues while nostalgic parades wind through city streets. Yet the celebration now carries a museum-like quality — historical reenactment rather than commemoration of c
 The Deepfake Detector You've Never Heard Of That's 98% AccurateMay 03, 2025 am 11:10 AM
The Deepfake Detector You've Never Heard Of That's 98% AccurateMay 03, 2025 am 11:10 AMTo help address this urgent and unsettling trend, a peer-reviewed article in the February 2025 edition of TEM Journal provides one of the clearest, data-driven assessments as to where that technological deepfake face off currently stands. Researcher
 Quantum Talent Wars: The Hidden Crisis Threatening Tech's Next FrontierMay 03, 2025 am 11:09 AM
Quantum Talent Wars: The Hidden Crisis Threatening Tech's Next FrontierMay 03, 2025 am 11:09 AMFrom vastly decreasing the time it takes to formulate new drugs to creating greener energy, there will be huge opportunities for businesses to break new ground. There’s a big problem, though: there’s a severe shortage of people with the skills busi
 The Prototype: These Bacteria Can Generate ElectricityMay 03, 2025 am 11:08 AM
The Prototype: These Bacteria Can Generate ElectricityMay 03, 2025 am 11:08 AMYears ago, scientists found that certain kinds of bacteria appear to breathe by generating electricity, rather than taking in oxygen, but how they did so was a mystery. A new study published in the journal Cell identifies how this happens: the microb
 AI And Cybersecurity: The New Administration's 100-Day ReckoningMay 03, 2025 am 11:07 AM
AI And Cybersecurity: The New Administration's 100-Day ReckoningMay 03, 2025 am 11:07 AMAt the RSAC 2025 conference this week, Snyk hosted a timely panel titled “The First 100 Days: How AI, Policy & Cybersecurity Collide,” featuring an all-star lineup: Jen Easterly, former CISA Director; Nicole Perlroth, former journalist and partne


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

Dreamweaver Mac version
Visual web development tools

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

SublimeText3 Mac version
God-level code editing software (SublimeText3)

