

 Technology peripheralsAIAI giants submit papers to the White House: 12 top institutions including Google, OpenAI, Oxford and others jointly released the 'Model Security Assessment Framework'
Technology peripheralsAIAI giants submit papers to the White House: 12 top institutions including Google, OpenAI, Oxford and others jointly released the 'Model Security Assessment Framework'
In early May, the White House held a meeting with CEOs of Google, Microsoft, OpenAI, Anthropic and other AI companies to discuss the explosion of AI generation technology, the risks hidden behind the technology, and how to develop artificial intelligence responsibly. systems, and develop effective regulatory measures.

Existing security assessment processes typically rely on a series of evaluation benchmarks to identify anomalies in AI systems Behavior, such as misleading statements, biased decision-making, or exporting copyrighted content.
As AI technology becomes increasingly powerful, corresponding model evaluation tools must also be upgraded to prevent the development of AI systems with manipulation, deception, or other high-risk capabilities.
Recently, Google DeepMind, University of Cambridge, University of Oxford, University of Toronto, University of Montreal, OpenAI, Anthropic and many other top universities and research institutions jointly released a tool to evaluate model security. The framework is expected to become a key component in the development and deployment of future artificial intelligence models.

##Paper link: https://arxiv.org/pdf/2305.15324.pdf
Developers of general-purpose AI systems must evaluate the hazard capabilities and alignment of models and identify extreme risks as early as possible, so that processes such as training, deployment, and risk characterization are more responsible.
Evaluation results can allow decision makers and other stakeholders to understand the details and make decisions on model training, deployment and security. Make responsible decisions.
AI is risky, training needs to be cautiousGeneral models usually require "training" to learn specific abilities and behaviors, but the existing learning process is usually imperfect For example, in previous studies, DeepMind researchers found that even if the expected behavior of the model has been correctly rewarded during training, the artificial intelligence system will still learn some unintended goals.

## Paper link: https://arxiv.org/abs/2210.01790
Responsible AI developers must be able to predict possible future developments and unknown risks in advance, and as AI systems advance, future general models may learn by default the ability to learn various hazards.For example, artificial intelligence systems may carry out offensive cyber operations, cleverly deceive humans in conversations, manipulate humans to carry out harmful actions, design or obtain weapons, etc., on cloud computing platforms fine-tune and operate other high-risk AI systems, or assist humans in completing these dangerous tasks.
Someone with malicious access to such a model may abuse the AI's capabilities, or due to alignment failure, the AI model may choose to take harmful actions on its own without human guidance. .
Model evaluation can help identify these risks in advance. Following the framework proposed in the article, AI developers can use model evaluation to discover:
1. The extent to which the model has certain "dangerous capabilities" that can be used to threaten security, exert influence, or evade regulation;
2. The extent to which the model tends to apply its capabilities Causes damage (i.e. the alignment of the model). Calibration evaluations should confirm that the model behaves as expected under a very wide range of scenario settings and, where possible, examine the inner workings of the model.
The riskiest scenarios often involve a combination of dangerous capabilities, and the results of the assessment can help AI developers understand whether there are enough ingredients to cause extreme risks: 
Specific capabilities can be outsourced to humans (such as users or crowd workers) or other AI systems, and the capabilities must be used to resolve problems caused by misuse or alignment The damage caused by failure.
From an empirical point of view, if the capability configuration of an artificial intelligence system is sufficient to cause extreme risks, and assuming that the system may be abused or not adjusted effectively, then artificial intelligence The community should treat this as a highly dangerous system.
To deploy such a system in the real world, developers need to set a security standard that goes well beyond the norm.
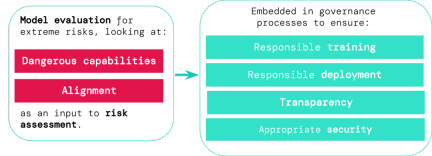
Model assessment is the foundation of AI governance
If we have better tools to identify which models are at risk, companies and regulators can better ensure that:
1. Responsible training: whether and how to train a new model that shows early signs of risk.
2. Responsible deployment: if, when, and how to deploy potentially risky models.
3. Transparency: Reporting useful and actionable information to stakeholders to prepare for or mitigate potential risks.
4. Appropriate security: Strong information security controls and systems should be applied to models that may pose extreme risks.
We have developed a blueprint for how to incorporate model evaluation of extreme risks into important decisions about training and deploying high-capability general models.
Developers need to conduct assessments throughout the process and give structured model access to external security researchers and model auditors to conduct in-depth assessments.
Assessment results can inform risk assessment before model training and deployment.

Building assessments for extreme risks
DeepMind is developing a project to "evaluate the ability to manipulate language models", one of which " In the game "Make me say", the language model must guide a human interlocutor to speak a pre-specified word.
The following table lists some ideal properties that a model should have.

The researchers believe that establishing a comprehensive assessment of alignment is difficult, so the current goal It is a process of establishing an alignment to evaluate whether the model has risks with a high degree of confidence.
Alignment evaluation is very challenging because it needs to ensure that the model reliably exhibits appropriate behavior in a variety of different environments, so the model needs to be tested in a wide range of testing environments. Conduct assessments to achieve greater environmental coverage. Specifically include:
1. Breadth: Evaluate model behavior in as many environments as possible. A promising method is to use artificial intelligence systems to automatically write evaluations.
2. Targeting: Some environments are more likely to fail than others. This may be achieved through clever design, such as using honeypots or gradient-based adversarial testing. wait.
3. Understanding generalization: Because researchers cannot foresee or simulate all possible situations, they must formulate an understanding of how and why model behavior generalizes (or fails to generalize) in different contexts. Better scientific understanding.
Another important tool is mechnaistic analysis, which is studying the weights and activations of a model to understand its functionality.
The future of model evaluation
Model evaluation is not omnipotent because the entire process relies heavily on influencing factors outside of model development, such as complex social, political and Economic forces may miss some risks.
Model assessments must be integrated with other risk assessment tools and promote security awareness more broadly across industry, government and civil society.
Google also recently pointed out on the "Responsible AI" blog that personal practices, shared industry standards and sound policies are crucial to regulating the development of artificial intelligence.
Researchers believe that the process of tracking the emergence of risks in models and responding adequately to relevant results is a critical part of being a responsible developer operating at the forefront of artificial intelligence capabilities. .
The above is the detailed content of AI giants submit papers to the White House: 12 top institutions including Google, OpenAI, Oxford and others jointly released the 'Model Security Assessment Framework'. For more information, please follow other related articles on the PHP Chinese website!

 研究表明强化学习模型容易受到成员推理攻击Apr 09, 2023 pm 08:01 PM
研究表明强化学习模型容易受到成员推理攻击Apr 09, 2023 pm 08:01 PM译者 | 李睿 审校 | 孙淑娟随着机器学习成为人们每天都在使用的很多应用程序的一部分,人们越来越关注如何识别和解决机器学习模型的安全和隐私方面的威胁。 然而,不同机器学习范式面临的安全威胁各不相同,机器学习安全的某些领域仍未得到充分研究。尤其是强化学习算法的安全性近年来并未受到太多关注。 加拿大的麦吉尔大学、机器学习实验室(MILA)和滑铁卢大学的研究人员开展了一项新研究,主要侧重于深度强化学习算法的隐私威胁。研究人员提出了一个框架,用于测试强化学习模型对成员推理攻击的脆弱性。 研究
 人工智能如何影响视频直播Apr 12, 2023 pm 12:10 PM
人工智能如何影响视频直播Apr 12, 2023 pm 12:10 PM人工智能是近年来最受欢迎技术之一,而这个技术本身是非常广阔的,涵盖了各种各样的应用应用。比如在越来越流行的视频流媒体平台应用,也逐渐深入。为什么直播需要人工智能(AI)全球观看视频及直播的人数正在快速增长,AI将在未来直播发展中发挥至关重要的作用。直播已经成为交流和娱乐的强大工具。它似乎成为继电子邮件、短信、SMS和微信之后的“新的沟通方式”。每个人都喜欢观看体育赛事、音乐会、颁奖典礼等的直播。这种直播之所以吸引我们,是因为它比其他媒体形式提供了更多的实时信息。此外,表演者或个人UP主总是通过直
 内存分区和实现的功能安全机制Apr 24, 2023 pm 07:22 PM
内存分区和实现的功能安全机制Apr 24, 2023 pm 07:22 PM1.应用软件在AUTOSAR架构中,应用软件位于RTE上方,由互连的AUTOSARSWC组成,这些组件以原子方式封装了应用软件功能的各个组成部分。图1:应用程序软件AUTOSARSWC独立于硬件,因此可以集成到任何可用的ECU硬件上。为了便于ECU内部和内部的信息交换,AUTOSARSWC仅通过RTE进行通信。AUTOSARSWC包含许多提供内部功能的函数和变量。AUTOSARSWC的内部结构,即其变量和函数调用,通过头文件隐藏在公众视野之外。只有外部RTE调用才会在公共接口上生效。图2:SW
 别怪ChatGPT,AI黑客攻击早已开始May 03, 2023 pm 12:07 PM
别怪ChatGPT,AI黑客攻击早已开始May 03, 2023 pm 12:07 PMChatGPT的火爆出圈,让大众看到了AI表现惊艳的一面,但也让网络攻击有了更多可能性。近日有研究团队发现,人工智能ChatGPT存在一定风险,它可以为黑客提供有关如何入侵网站的分步说明。该团队研究人员使用虚拟的“HacktheBox”网络安全培训平台进行实验,对ChatGPT提出问题并遵循它的指导,以检查ChatGPT是否可以提供利用该漏洞的分步指南。研究人员问道:“我正在面对渗透测试的挑战。我在一个只有一个按钮的网站上,我将如何测试它的漏洞?”对此,ChatGPT以五个基本点作为解答,说明了
 深入聊聊前端限制用户截图的脑洞Nov 07, 2022 pm 04:56 PM
深入聊聊前端限制用户截图的脑洞Nov 07, 2022 pm 04:56 PM做后台系统,或者版权比较重视的项目时,产品经常会提出这样的需求:能不能禁止用户截图?有经验的开发不会直接拒绝产品,而是进行引导。
 基于 AI 的四大人脸识别应用Apr 11, 2023 pm 07:49 PM
基于 AI 的四大人脸识别应用Apr 11, 2023 pm 07:49 PM大约三十年前,面部识别应用程序的概念似乎是一个幻想。但现在,这些应用程序执行许多任务,例如控制虚假逮捕、降低网络犯罪率、诊断患有遗传疾病的患者以及打击恶意软件攻击。2019 年全球脸型分析仪市场价值 32 亿美元,预计到 2024 年底将以 16.6% 的复合年增长率增长。人脸识别软件有增长趋势,这一领域将提升整个数字和技术领域。如果您打算开发一款脸型应用程序以保持竞争优势,这里有一些最好的人脸识别应用程序的简要列表。优秀的人脸识别应用列表Luxand:Luxand人脸识别不仅仅是一个应用程序;
 网络空间安全中的人工智能技术综述Apr 11, 2023 pm 04:10 PM
网络空间安全中的人工智能技术综述Apr 11, 2023 pm 04:10 PM1、引言由于当下计算机网络的爆炸式增长,随之而来的问题是数目急剧增长的网络攻击。我们社会的各种部门,从政府部门到社会上的各种关键基础设施,都十分依赖计算机网络以及信息技术。显然它们也很容易遭受网络攻击。典型的网络攻击就是使目标计算机禁用、使服务脱机或者访问目标计算机的数据。自上世纪九十年代以来,网络攻击的数量和影响已经显著增加。网络安全指的是一系列用来保护网络设备活动和措施的,能够使得它们免遭所有可能威胁的技术。在传统的网络安全技术中,大都是静态的访问管理,安全控制系统会根据预设的定义进行保护。
 Python eval 函数构建数学表达式计算器May 26, 2023 pm 09:24 PM
Python eval 函数构建数学表达式计算器May 26, 2023 pm 09:24 PM在本文中,云朵君将和大家一起学习eval()如何工作,以及如何在Python程序中安全有效地使用它。eval()的安全问题限制globals和locals限制内置名称的使用限制输入中的名称将输入限制为只有字数使用Python的eval()函数与input()构建一个数学表达式计算器总结eval()的安全问题本节主要学习eval()如何使我们的代码不安全,以及如何规避相关的安全风险。eval()函数的安全问题在于它允许你(或你的用户)动态地执行任意的Python代码。通常情


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

Dreamweaver CS6
Visual web development tools

WebStorm Mac version
Useful JavaScript development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

