
How to configure high availability and persistence in redis

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-06-01 17:38:54850browse

1. Redis High Availability
1. Overview of Redis High Availability
In web servers, high availability refers to the time during which the server can be accessed normally , the measurement standard is how long it can provide normal services (99.9%, 99.99%, 99.999%, etc.). [Related recommendation: Redis video tutorial]
However, in the context of Redis, the meaning of high availability seems to be broader. In addition to ensuring the provision of normal services (such as master-slave separation, fast disaster recovery technology), we also need to consider Expansion of data capacity, data security will not be lost, etc.
2. Redis high availability strategy
In Redis, the technologies to achieve high availability mainly include persistence, master-slave separation, sentinels and clusters.
| High availability strategy | Description |
|---|---|
| Persistence | Persistence is the simplest high-availability method (sometimes not even classified as a high-availability method). Its main function is data backup, that is, storing data on the hard disk to ensure that the data will not be lost due to process exit. |
| Master-slave replication | Master-slave replication is the basis of high-availability Redis. Both Sentinel and Cluster achieve high availability based on master-slave replication. Master-slave replication mainly implements multi-machine backup of data, as well as load balancing and simple fault recovery for read operations. Defects: Failure recovery cannot be automated, write operations cannot be load balanced, and storage capacity is limited by a single machine. |
| Sentinel | Based on master-slave replication, Sentinel implements automated fault recovery. Disadvantages: Write operations cannot be load balanced, and storage capacity is limited by a single machine. |
| Cluster | Through clustering, Redis solves the problem that write operations cannot be load-balanced and storage capacity is limited by a single machine, achieving a relatively complete high-availability solution. |
2. Redis persistence
1. Redis persistence function
Redis is an in-memory database, and the data is stored in the memory. In order to avoid the Redis process caused by server power outage and other reasons For permanent loss of data after an abnormal exit, the data in Redis needs to be regularly saved from memory to the hard disk in some form (data or commands); when Redis restarts next time, persistent files are used to achieve data recovery. In addition, in order to prepare for disaster backup, persistent files can be copied to a remote location.
2. Two ways of Redis persistence
RDB persistence
The principle is to regularly save the database records of Redis in memory to the disk.AOF persistence (append only file)
The principle is to write the Redis operation log to the file in an appending manner, similar to MySQL's binlog.
Since AOF persistence has better real-time performance, that is, less data is lost when the process exits unexpectedly, AOF is currently the mainstream persistence method, but RDB persistence still has its place.
3. RDB persistence
RDB persistence refers to generating a snapshot of the data in the current process in the memory and saving it to the hard disk within a specified time interval (therefore also Called snapshot persistence), it is stored using binary compression, and the saved file suffix is rdb; when Redis is restarted, the snapshot file can be read to restore the data.
3.1 Trigger conditions
The triggering of RDB persistence is divided into two types: manual triggering and automatic triggering.
3.1.1 Manual trigger
Both the save command and the bgsave command can generate RDB files.
The save command will block the Redis server process until the RDB file is created. During the period when the Redis server is blocked, the server cannot process any command requests.
The bgsave command will fork() a child process. The child process will be responsible for creating the RDB file, and the parent process (ie the Redis main process) will continue to process requests.
During the execution of the bgsave command, only the fork child process will block the server. For the save command, the entire process will block the server. Therefore, save has been basically abandoned and must be eliminated in the online environment. The use of save.
3.1.2 Automatic triggering
#When RDB persistence is automatically triggered, Redis will also choose bgsave instead of save for persistence.
3.2 Configuration method
Setting by modifying the configuration file: save m n
Automatically The most common trigger is to pass save m n in the configuration file, which specifies that bgsave will be triggered when n changes occur within m seconds.
[root@localhost ~]# vim /etc/redis/6379.conf ##219行,以下三个save条件满足任意一个时,都会引起bgsave的调用save 900 1 ##当时间到900秒时,如果redis数据发生了至少1次变化,则执行bgsavesave 300 10 ##当时间到300秒时,如果redis数据发生了至少10次变化,则执行bgsavesave 60 10000 ##当时间到60秒时,如果redis数据发生了至少10000次变化,则执行bgsave##254行,指定RDB文件名dbfilename dump.rdb##264行,指定RDB文件和AOF文件所在目录dir /var/lib/redis/6379##242行,是否开启RDB文件压缩rdbcompression yes
3.3 Other automatic triggering mechanisms
In addition to save m n, there are some other situations that will trigger bgsave:
In the master-slave replication scenario, if the slave node performs a full copy operation, the master node will execute the bgsave command and send the rdb file to the slave node.
When executing the shutdown command, rdb persistence is automatically executed.
3.4 Execution process
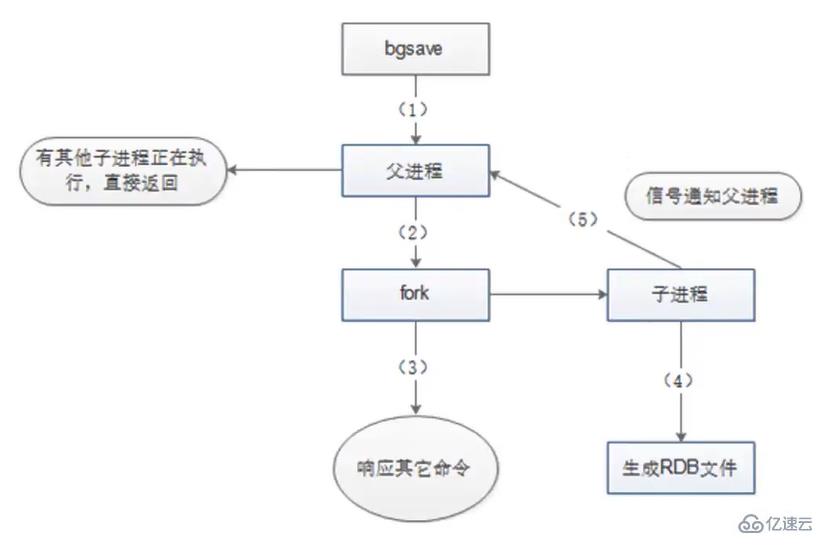
The Redis parent process first determines whether it is currently executing save or bgsave If the child process of /bgrewriteaof is executing, the bgsave command will return directly. The sub-processes of bgsave/bgrewriteaof cannot be executed at the same time, mainly due to performance considerations; two concurrent sub-processes perform a large number of disk write operations at the same time, which may cause serious performance problems.
When creating a child process, the parent process performed a fork operation, causing the parent process to be blocked. During this period, Redis was unable to execute any commands from the client.
After the parent process forks, the bgsave command returns the "Background saving started" message and no longer blocks the parent process, and can respond to other commands
The child process creates an RDB file and generates a temporary snapshot file based on the memory snapshot of the parent process. After completion, the original file is atomically replaced
The child process sends a signal to the parent process to indicate completion, and the parent process updates Statistical information
3.5 Loading at startup
The loading of RDB files is automatically executed when the server starts, and there is no special command. However, because AOF has a higher priority, when AOF is turned on, Redis will give priority to loading the AOF file to restore data; only when AOF is turned off, the RDB file will be detected when the Redis server starts and loaded automatically. The server is blocked while loading the RDB file until the loading is completed.
When Redis loads an RDB file, it will verify the RDB file. If the file is damaged, an error will be printed in the log and Redis will fail to start.
4. AOF persistence
RDB persistence writes process data to files, while AOF persistence records each write and delete command executed by Redis to a separate log file , the query operation will not be recorded; when Redis restarts, execute the command in the AOF file again to restore the data.
Compared with RDB, AOF has better real-time performance, so it has become a mainstream persistence solution.
4.1 开启 AOF
Redis服务器默认开启RDB,关闭AOF;要开启AOF,需要在配置文件中配置
[root@localhost ~]# vim /etc/redis/6379.conf ##700行,修改,开启AOFappendonly yes##704行,指定AOF文件名称appendfilename "appendonly.aof"##796行,是否忽略最后一条可能存在问题的指令aof-load-truncated yes[root@localhost ~]# /etc/init.d/redis_6379 restartStopping ... Redis stopped Starting Redis server...
4.2 执行流程
由于需要记录Redis的每条写命令,因此AOF不需要触发,下面介绍AOF的执行流程。
AOF的执行流程包括:
命令追加(append):将Redis的写命令追加到缓冲区aof_buf;
根据不同的同步策略,把aof_buf中的内容写入硬盘,并实现文件同步
文件重写(rewrite):定期重写AOF文件,达到压缩的目的。
4.2.1 命令追加(append)
Redis先将命令追加到缓冲区,而不是直接写入文件,主要是为了避免每次有写命令都直接写入硬盘,导致硬盘IO称为Redis负载的瓶颈。
命令追加的格式是Redis命令请求的协议格式,它是一种纯文本格式,具有兼容性好、可读性强、容易处理、操作简单、避免二次开销等优点。在AOF文件中,除了用于指定数据库的select命令(如select 0为选中0号数据库)是由Redis添加的,其他都是客户端发送来的写命令。
4.2.2 文件写入(write)和文件同步(sync)
Redis提供了多种AOF缓存区的同步文件策略,策略涉及到操作系统的write和fsync函数,说明如下:
为了提高文件写入效率,在现代操作系统中,当用户调用write函数将数据写入文件时,操作系统通常会将数据暂存到一个内存缓冲区里,当缓冲区被填满或超过了指定时限后,才真正将缓冲区的数据写入到硬盘里。这样的操作虽然提高了效率,但也带来了安全问题:如果计算机停机,内存缓冲区中的数据会丢失;因此系统同时提供了fsync、fdatasync等同步函数,可以强制操作系统立刻将缓冲区中的数据写入到硬盘里,从而确保数据的安全性。
4.2.3 三种同步方式
AOF缓存区的同步文件策略存在三种同步方式,通过对/etc/redis/6379.conf的729行的修改进行配置。
4.2.3.1 appendfsync always
将命令写入aof_buf后,立即进行系统fsync操作,将其同步到AOF文件,当fsync操作完成后,线程便会返回。这种情况下,每次有写命令都要同步到AOF文件,硬盘IO成为性能瓶颈,Redis只能支持大约几百TPS写入,严重降低了Redis的性能;即便是使用固态硬盘(SSD),每秒大约也就只能处理几万个命令,而且会大大降低SSD的寿命。
4.2.3.2 appendfsync no
命令写入aof_buf后调用系统write操作,不对AOF文件做fsync同步;同步由操作系统负载,通常同步周期为30秒。文件同步时间不可预测,并且缓冲区中的数据会堆积很多,导致数据安全性无法保障。
4.2.3.3 appendfsync everysec(推荐)
命令写入aof_buf后调用系统write操作,write完成后线程返回:fsync同步文件操作由专门的线程每秒调用一次。everysec是前述两种策略的折中,是性能和数据安全性的平衡,一次是Redis的默认配置,也是我们推荐的配置。
4.2.4 文件重写(rewrite)
随着时间流逝,Redis服务器执行的写命令越来越多,AOF文件也会越来越大;过大的AOF文件不仅会影响服务器的正常运行,也会导致数据恢复需要的时间过长。
文件重写是指定期重写AOF文件,减小AOF文件的体积。需要注意的是,AOF重写是把Redis进程内的数据转化为写命令,同步到新的AOF文件;不会对旧的AOF文件进行任何读取、写入操作。
关于文件重写需要注意的另一点是:对于AOF持久化来说,文件重写虽然是强烈推荐的,但并不是必须的;即使没有文件重写,数据也可以被持久化并在Redis启动的时候导入;因此在一些现实中,会关闭自动的文件重写,然后定时任务在每天的某一时刻定时执行。
4.2.4.1 具有压缩功能的原因
文件重写之所以能够压缩AOF文件,原因在于:
过期的数据不再写入文件。
无效的命令不再写入文件:如有些数据被重复设置(set mykey v1,set mykey v2)、有些数据被删除了(set myset v1,del myset)等。
多条命令可以合并为一个:如sadd myset v1,sadd myset v2,sadd myset v3可以合并为sadd myset v1 v2 v3。
通过上述原因可以看出,由于重写后AOF执行的命令减少了,文件重写既可以减少文件占用的空间,也可以加快恢复速度。
4.2.4.2 文件重写的触发
文件重写分为手动触发和自动触发:
Manual triggering: Directly call the bfrewriteaof command. The execution of this command is somewhat similar to bgsave. Both fork processes perform specific work, and they are only blocked when forking.
Automatic triggering: Automatically execute bgrewriteaof by setting the auto-aof-rewrite-min-size option and the auto-aof-rewrite-percentage option. Only when the two options auto-aof-rewrite-min-size and auto-aof-rewrite-percentage are satisfied at the same time, AOF rewriting, that is, the bgrewriteaof operation will be automatically triggered.
The automatically triggered configuration is located at lines 771 and 772 of /etc/redis/6379.conf
- ##auto -aof-rewrite-percentage 100
When the current AOF file size (i.e. aof_current_size) is twice the AOF file size (aof_base_size) during the last log rewrite, the bgrewriteaof operation occurs
- auto-aof-rewrite-min-size 64mb
The minimum value for executing the bgrewriteaof command on the current AOF file to avoid frequent bgrewriteaof
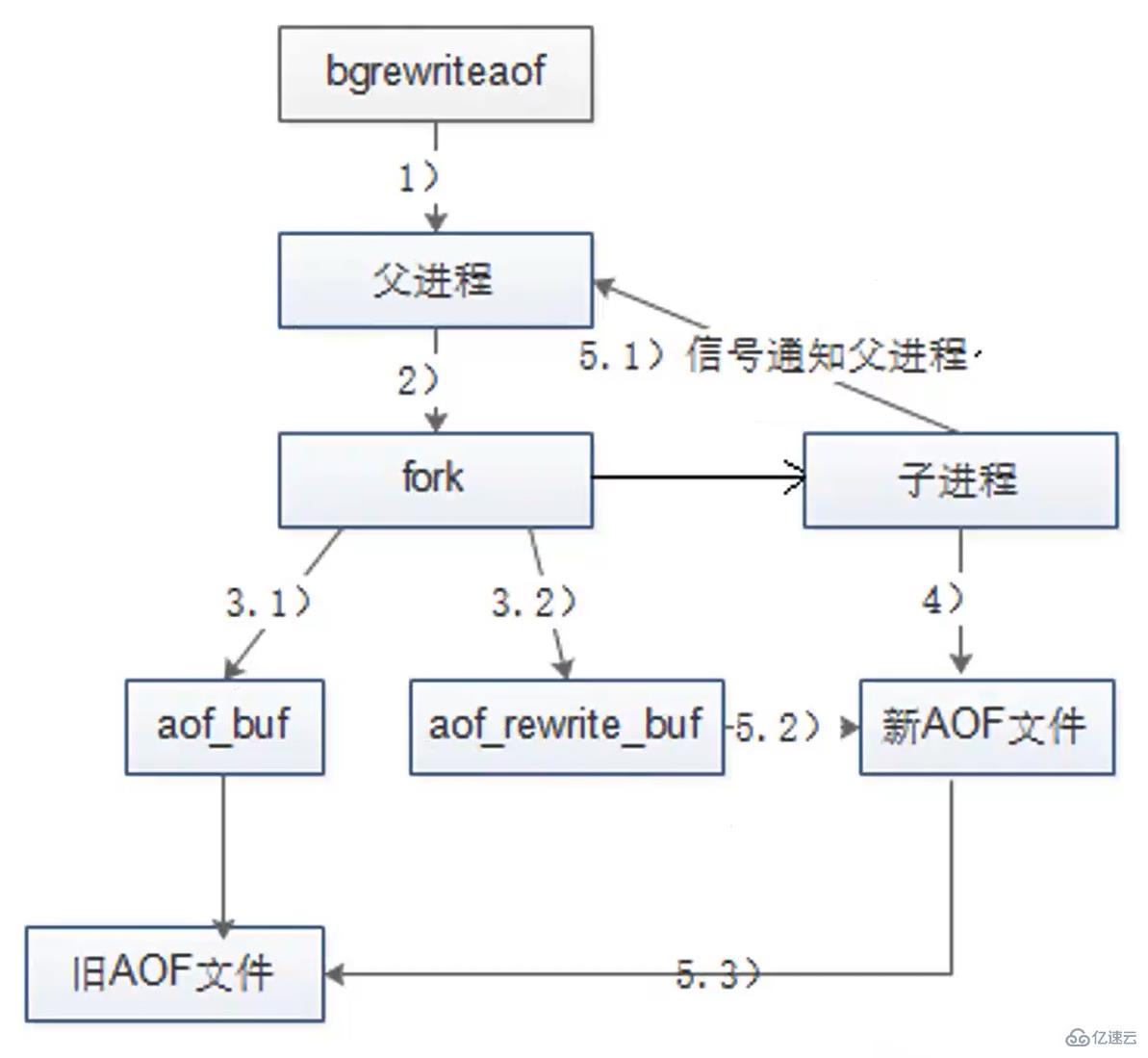 The file rewriting process is as follows:
The file rewriting process is as follows:
- The Redis parent process first determines whether it is currently executing The child process of bgsave/bgrewriteaof; if it exists, the bgrewriteaof command will return directly. If the bgsave command exists, it will wait until the bgsave execution is completed before executing it.
- The parent process performs a fork operation to create a child process. During this process, the parent process is blocked.
- After the parent process forks, the bgrewriteaof command returns the "Background append only file rewrite started" message and no longer blocks the parent process, and can respond to other commands. All Redis write commands are still written to the AOF buffer and synchronized to the hard disk according to the appendfsync policy to ensure the correctness of the original AOF mechanism.
- The child process can only share the memory data during the fork operation. This is because the fork operation uses copy-on-write technology. Since the parent process is still responding to the command, Redis uses the AOF rewrite buffer (aof_rewrite_buf) to save this part of the data to prevent this part of the data from being lost during the generation of the new AOF file. In other words, during the execution of bgrewriteaof, Redis's write command is appended to both aof_buf and aof_rewrite_buf buffers at the same time.
- The child process writes to the new AOF file according to the memory snapshot and the command merging rules.
- After the child process finishes writing the new AOF file, it sends a signal to the parent process, and the parent process updates the statistical information, which can be viewed through info persistence.
- The parent process writes the data in the AOF rewrite buffer to the new AOF file, thus ensuring that the database state saved in the new AOF file is consistent with the current state of the server.
- Use the new AOF file to replace the old file and rewrite it into AOF.
Regarding the file rewriting process, there are two points that need special attention:
- Rewriting is forked by the parent process The write commands executed by Redis during the rewriting of the child process need to be appended to the new AOF file. For this reason, Redis introduces aof_rewrite_buf cache for example
- 4.3 Loading at startup
- When AOF is turned on but the AOF file does not exist, the RDB file will not be loaded even if it exists.
- When Redis loads an AOF file, it will verify the AOF file. If the file is damaged, an error will be printed in the log and Redis will fail to start. However, if the end of the AOF file is incomplete (a sudden machine downtime can easily cause the end of the file to be incomplete), and the aof_load_truncated parameter is turned on, a warning will be output in the log, and Redis will ignore the end of the AOF file and start successfully. The aof_load_truncated parameter is enabled by default.
- 5. Advantages and disadvantages of RDB and AOF RDB persistence
Disadvantages: The well-known disadvantage of RDB files is that the persistence method of data snapshots determines that real-time persistence cannot be achieved. Today, when data is becoming more and more important, a large amount of data loss is often unacceptable. Therefore, AOF persistence has become mainstream. In addition, RDB files need to meet a specific format and have poor compatibility (for example, the old version of Redis is not compatible with the new version of RDB files).For RDB persistence, on the one hand, the Redis main process will be blocked when bgsave performs a fork operation. On the other hand, the sub-process writing data to the hard disk will also bring IO pressure.
AOF persistence
For AOF persistence, the frequency of writing data to the hard disk is greatly increased (second level under the everysec policy), the IO pressure is greater, and there may even be additional blocking problems in the AOF.
Similar to RDB's bgsave, rewriting AOF files will also face the problems of fork blocking and child process IO load. AOF writes data to the hard disk more frequently, which will have a greater impact on the performance of the Redis main process.
Generally speaking, it is recommended to turn off the automatic rewriting function of AOF, and set a scheduled task during the rewriting operation, and perform it in the early morning when the business volume is low, so as to reduce the impact of AOF on the performance of the main process and the impact of IO Literacy stress.
The above is the detailed content of How to configure high availability and persistence in redis. For more information, please follow other related articles on the PHP Chinese website!