



1. Brief description of the process
Understanding the persistence process of MySQL data can help us deepen our understanding of the underlying MySQL. In this article, we will sort out this process in a popular way. Help everyone establish a preliminary understanding. If you are interested, you can study and research this process in depth.
The storage of MySQL data can generally be divided into two parts, the stored procedure in the memory and the persistent storage on the hard disk. Here, it involves the buffer poll and redo in the memory. log and the transaction log and table structure on the disk. In this article, we do not explain the specific design of each part in detail, but just give you a conceptual understanding:
buffer pollis part of the InnoDB engine cache pool. We can simply understand it here as the cache of memory blocks that the database reads from disk into memory;redo logis a logical log in memory, recording transaction change operationsTransaction logis a disk Food logical log onTable structureis the structure that actually stores data
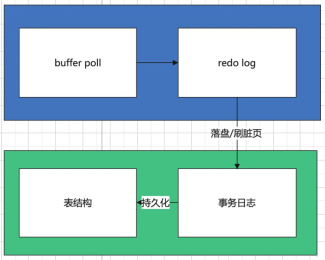
2. Operations in memory
buffer poll has a cache for the data read into the memory. When the query command is executed, it will first check whether there is a hit in the cache. If there is a miss, The required data will be read from the disk. The cache management uses an improved LRU algorithm, which will not be introduced in depth here.
When a modification instruction is run, the first thing to do is to modify the cache in buffer poll. The modified data will be marked as dirty page, At the same time, the modified operations will also be recorded in redo log. The version chain in MVCC that we often say is implemented with the help of redo log.
It should be noted that dirty pages are not dropped to the disk immediately, but there is a flush control mechanism that can be set. For example, a transaction is dropped to the disk immediately after settlement, regularly dropped to the disk according to a certain time, etc. .
The operations in memory are non-persistent. If an unexpected problem occurs and the system crashes, the data has not been persisted, so in theory, it will not cause damage to the database. sexual influence.
3. Disk persistence
3.1 The role of transaction log
InnoDB’s persistence on disk is divided into two steps. The first step is the storage of logical logs, and then Then flush the data in the log into disk space.
Before discussing why we should use logical logs, we need to briefly understand the difference between random IO and sequential IO:
The addressing process is an important bottleneck in disk IO because it requires moving the probe to the location where it needs to be read to read disk data.
Sequential IO means that the addressed space is continuous and the moving distance is very short. Random IO means that the addresses we need to find are distributed everywhere. Move long distances.
So, we can clearly draw the conclusion: replacing random IO with sequential IO can effectively improve the efficiency of disk IO, and the role of logical logs is correct. In this case, because the log files are continuous on the disk, the IO efficiency can be much higher compared to data table information distributed everywhere.
As long as we completely update the operation in the transaction log, then the transaction has been successfully persisted, and a dedicated thread will store the log information into the table structure.
3.2 Two-step storage of table structure
The process of storing log information into the table structure is divided into two steps. First, the data will be updated in the cache area of the table header. After completion, it will be refreshed in the corresponding table structure.
The purpose of two-step storage is to ensure strong consistency of data storage and prevent data from being incomplete due to database downtime during the process of flashing to disk.
The cache area of the table header and the storage block of the table structure have check codes to verify the integrity of the data. If the former is complete and the latter is incomplete, directly re-flash the former data in the latter. It can be solved. If the former is incomplete, it means that the process of flushing from the log failed, just flush again.
The above is the detailed content of MySQL data persistence process example analysis. For more information, please follow other related articles on the PHP Chinese website!

 图文详解mysql架构原理May 17, 2022 pm 05:54 PM
图文详解mysql架构原理May 17, 2022 pm 05:54 PM本篇文章给大家带来了关于mysql的相关知识,其中主要介绍了关于架构原理的相关内容,MySQL Server架构自顶向下大致可以分网络连接层、服务层、存储引擎层和系统文件层,下面一起来看一下,希望对大家有帮助。
 mysql怎么去掉第一个字符May 19, 2022 am 10:21 AM
mysql怎么去掉第一个字符May 19, 2022 am 10:21 AM方法:1、利用right函数,语法为“update 表名 set 指定字段 = right(指定字段, length(指定字段)-1)...”;2、利用substring函数,语法为“select substring(指定字段,2)..”。
 mysql的msi与zip版本有什么区别May 16, 2022 pm 04:33 PM
mysql的msi与zip版本有什么区别May 16, 2022 pm 04:33 PMmysql的msi与zip版本的区别:1、zip包含的安装程序是一种主动安装,而msi包含的是被installer所用的安装文件以提交请求的方式安装;2、zip是一种数据压缩和文档存储的文件格式,msi是微软格式的安装包。
 mysql怎么替换换行符Apr 18, 2022 pm 03:14 PM
mysql怎么替换换行符Apr 18, 2022 pm 03:14 PM在mysql中,可以利用char()和REPLACE()函数来替换换行符;REPLACE()函数可以用新字符串替换列中的换行符,而换行符可使用“char(13)”来表示,语法为“replace(字段名,char(13),'新字符串') ”。
 mysql怎么将varchar转换为int类型May 12, 2022 pm 04:51 PM
mysql怎么将varchar转换为int类型May 12, 2022 pm 04:51 PM转换方法:1、利用cast函数,语法“select * from 表名 order by cast(字段名 as SIGNED)”;2、利用“select * from 表名 order by CONVERT(字段名,SIGNED)”语句。
 MySQL复制技术之异步复制和半同步复制Apr 25, 2022 pm 07:21 PM
MySQL复制技术之异步复制和半同步复制Apr 25, 2022 pm 07:21 PM本篇文章给大家带来了关于mysql的相关知识,其中主要介绍了关于MySQL复制技术的相关问题,包括了异步复制、半同步复制等等内容,下面一起来看一下,希望对大家有帮助。
 带你把MySQL索引吃透了Apr 22, 2022 am 11:48 AM
带你把MySQL索引吃透了Apr 22, 2022 am 11:48 AM本篇文章给大家带来了关于mysql的相关知识,其中主要介绍了mysql高级篇的一些问题,包括了索引是什么、索引底层实现等等问题,下面一起来看一下,希望对大家有帮助。
 mysql怎么判断是否是数字类型May 16, 2022 am 10:09 AM
mysql怎么判断是否是数字类型May 16, 2022 am 10:09 AM在mysql中,可以利用REGEXP运算符判断数据是否是数字类型,语法为“String REGEXP '[^0-9.]'”;该运算符是正则表达式的缩写,若数据字符中含有数字时,返回的结果是true,反之返回的结果是false。


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

Atom editor mac version download
The most popular open source editor

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

