

 Technology peripheralsAIGPT acts as a brain, directing multiple models to collaborate to complete various tasks. The general system AutoML-GPT is here.
Technology peripheralsAIGPT acts as a brain, directing multiple models to collaborate to complete various tasks. The general system AutoML-GPT is here.GPT acts as a brain, directing multiple models to collaborate to complete various tasks. The general system AutoML-GPT is here.

Currently, although AI models have been involved in a very wide range of application fields, most AI models are designed for specific tasks, and they often require a lot of manpower to complete the correct model architecture, optimization algorithms and hyperparameters. . After ChatGPT and GPT-4 became popular, people saw the huge potential of large language models (LLM) in text understanding, generation, interaction, reasoning, etc. Some researchers try to use LLM to explore new paths towards artificial general intelligence (AGI).
Recently, researchers from the University of Texas at Austin proposed a new idea - to develop task-oriented prompts and use LLM to automate the training pipeline, and based on this Idea launches a new system AutoML-GPT.

Paper address:
https: //www.php.cn/link/39d4b545fb02556829aab1db805021c3
AutoML-GPT uses GPT as a bridge between various AI models and uses optimized hyperparameters to dynamically train the model. AutoML-GPT dynamically receives user requests from Model Card [Mitchell et al., 2019] and Data Card [Gebru et al., 2021] and composes corresponding prompt paragraphs. Finally, AutoML-GPT uses this prompt paragraph to automatically perform multiple experiments, including processing data, building model architecture, tuning hyperparameters, and predicting training logs.
AutoML-GPT solves complex AI tasks across a variety of tests and datasets by maximizing its powerful NLP capabilities and existing AI models. A large number of experiments and ablation studies have shown that AutoML-GPT is versatile and effective for many artificial intelligence tasks (including CV tasks and NLP tasks).
Introduction to AutoML-GPT
AutoML-GPT is a collaborative system that relies on data and model information to format prompt input paragraphs. Among them, LLM serves as the controller, and multiple expert models serve as collaborative executors. The workflow of AutoML-GPT includes four stages: data processing, model architecture design, hyperparameter adjustment and training log generation.
Specifically, the working mechanism of AutoML-GPT is as follows:

- Through Model Card and Data Card generate fixed-format prompt paragraphs
- Build a training pipeline to handle user needs on the selected data set and model architecture
- Generate performance training logs and adjust hyperparameters
- Adjust the model based on auto-suggested hyperparameters
Input Decomposition
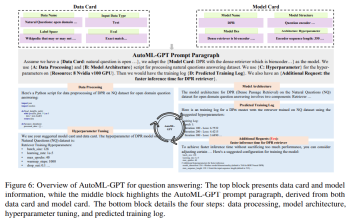
The first stage of AutoML-GPT is for LLM to accept user input. In order to improve the performance of LLM and generate effective prompts, this study adopts specific instructions for input prompts. These instructions include three parts: Data Card, Model Card, Evaluation Metrics and Additional Requirements.
As shown in Figure 2 below, the key parts of the Data Card consist of the data set name, input data set type (such as image data or text data), label space (such as category or resolution) and default evaluation indicators.
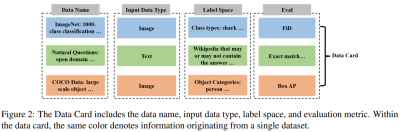
As shown in Figure 3 below, the Model Card consists of the model name, model structure, model description and architecture hyperparameters. By providing this information, the Model Card can tell LLM which models are used throughout the machine learning system, as well as the user's preferences for model architecture.
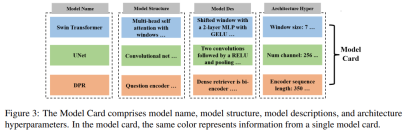
In addition to Data Card and Model Card, users can also choose to request more evaluation benchmarks, evaluation metrics, or any constraints. AutoML-GPT provides these task specifications as high-level instructions to LLM for analyzing user requirements accordingly.
When there is a series of tasks that need to be processed, AutoML-GPT needs to match the corresponding model for each task. In order to achieve this goal, the system first needs to obtain the model description from the Model Card and user input.
AutoML-GPT then uses the in-context task-model assignment mechanism to dynamically assign models to tasks. This approach enables incremental model access and provides greater openness and flexibility by combining model description with a better understanding of user needs.
Adjust hyperparameters using prediction training logs
AutoML-GPT sets hyperparameters based on Data Card and Model Card, And predict performance by generating training logs of hyperparameters. The system automatically performs training and returns training logs. Model performance training logs on the dataset record various metrics and information collected during the training process, which helps understand the model training progress, identify potential problems, and evaluate the effectiveness of the selected architecture, hyperparameters, and optimization methods .
Experiments
To evaluate the performance of AutoML-GPT, this study uses ChatGPT (OpenAI’s GPT-4 version) to implement it and conducts multiple experiments from multiple This perspective shows the effect of AutoML-GPT.
Figure 4 below shows the results of training on an unknown data set using AutoML-GPT:

Figure 5 below shows the process of AutoML-GPT completing the target detection task on the COCO data set:

Figure 6 below shows AutoML-GPT Experimental results on the NQ Open Dataset (Natural Questions Open dataset, [Kwiatkowski et al., 2019]):
This study also used XGBoost evaluated AutoML-GPT on the UCI Adult data set [Dua and Graff, 2017] to explore its performance on classification tasks. The experimental results are shown in Figure 7 below:

Interested readers can read the original text of the paper to learn more research details.
The above is the detailed content of GPT acts as a brain, directing multiple models to collaborate to complete various tasks. The general system AutoML-GPT is here.. For more information, please follow other related articles on the PHP Chinese website!

 Newest Annual Compilation Of The Best Prompt Engineering TechniquesApr 10, 2025 am 11:22 AM
Newest Annual Compilation Of The Best Prompt Engineering TechniquesApr 10, 2025 am 11:22 AMFor those of you who might be new to my column, I broadly explore the latest advances in AI across the board, including topics such as embodied AI, AI reasoning, high-tech breakthroughs in AI, prompt engineering, training of AI, fielding of AI, AI re
 Europe's AI Continent Action Plan: Gigafactories, Data Labs, And Green AIApr 10, 2025 am 11:21 AM
Europe's AI Continent Action Plan: Gigafactories, Data Labs, And Green AIApr 10, 2025 am 11:21 AMEurope's ambitious AI Continent Action Plan aims to establish the EU as a global leader in artificial intelligence. A key element is the creation of a network of AI gigafactories, each housing around 100,000 advanced AI chips – four times the capaci
 Is Microsoft's Straightforward Agent Story Enough To Create More Fans?Apr 10, 2025 am 11:20 AM
Is Microsoft's Straightforward Agent Story Enough To Create More Fans?Apr 10, 2025 am 11:20 AMMicrosoft's Unified Approach to AI Agent Applications: A Clear Win for Businesses Microsoft's recent announcement regarding new AI agent capabilities impressed with its clear and unified presentation. Unlike many tech announcements bogged down in te
 Selling AI Strategy To Employees: Shopify CEO's ManifestoApr 10, 2025 am 11:19 AM
Selling AI Strategy To Employees: Shopify CEO's ManifestoApr 10, 2025 am 11:19 AMShopify CEO Tobi Lütke's recent memo boldly declares AI proficiency a fundamental expectation for every employee, marking a significant cultural shift within the company. This isn't a fleeting trend; it's a new operational paradigm integrated into p
 IBM Launches Z17 Mainframe With Full AI IntegrationApr 10, 2025 am 11:18 AM
IBM Launches Z17 Mainframe With Full AI IntegrationApr 10, 2025 am 11:18 AMIBM's z17 Mainframe: Integrating AI for Enhanced Business Operations Last month, at IBM's New York headquarters, I received a preview of the z17's capabilities. Building on the z16's success (launched in 2022 and demonstrating sustained revenue grow
 5 ChatGPT Prompts To Stop Depending On Others And Trust Yourself FullyApr 10, 2025 am 11:17 AM
5 ChatGPT Prompts To Stop Depending On Others And Trust Yourself FullyApr 10, 2025 am 11:17 AMUnlock unshakeable confidence and eliminate the need for external validation! These five ChatGPT prompts will guide you towards complete self-reliance and a transformative shift in self-perception. Simply copy, paste, and customize the bracketed in
 AI Is Dangerously Similar To Your MindApr 10, 2025 am 11:16 AM
AI Is Dangerously Similar To Your MindApr 10, 2025 am 11:16 AMA recent [study] by Anthropic, an artificial intelligence security and research company, begins to reveal the truth about these complex processes, showing a complexity that is disturbingly similar to our own cognitive domain. Natural intelligence and artificial intelligence may be more similar than we think. Snooping inside: Anthropic Interpretability Study The new findings from the research conducted by Anthropic represent significant advances in the field of mechanistic interpretability, which aims to reverse engineer internal computing of AI—not just observe what AI does, but understand how it does it at the artificial neuron level. Imagine trying to understand the brain by drawing which neurons fire when someone sees a specific object or thinks about a specific idea. A
 Dragonwing Showcases Qualcomm's Edge MomentumApr 10, 2025 am 11:14 AM
Dragonwing Showcases Qualcomm's Edge MomentumApr 10, 2025 am 11:14 AMQualcomm's Dragonwing: A Strategic Leap into Enterprise and Infrastructure Qualcomm is aggressively expanding its reach beyond mobile, targeting enterprise and infrastructure markets globally with its new Dragonwing brand. This isn't merely a rebran


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Atom editor mac version download
The most popular open source editor

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

Zend Studio 13.0.1
Powerful PHP integrated development environment

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

SublimeText3 Chinese version
Chinese version, very easy to use

