

 Backend DevelopmentPython TutorialHow to use tracemalloc in Python3 to track mmap memory changes
Backend DevelopmentPython TutorialHow to use tracemalloc in Python3 to track mmap memory changes
Technical Background
In the previous blog we introduced some methods of using python3 to process tabular data, focusing on large-scale data processing such as vaex Data processing plan. This data processing solution is based on memory map technology. By creating memory mapped files, we avoid large-scale memory usage problems caused by directly loading source data in memory. This allows us to use local computer memory size that is not Process large-scale data under very large conditions. In Python 3, there is a library called mmap that can be used to create memory mapped files directly.
Use tracemalloc to track python program memory usage
Here we hope to compare the actual memory usage of memory mapping technology, so we need to introduce a Python-based memory tracking tool: tracemalloc. Let's take a simple example first, that is, create a random array, and then observe the memory size occupied by the array
# tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
length=10000
test_array=np.random.randn(length) # 分配一个定长随机数组
snapshot=tracemalloc.take_snapshot() # 内存摄像
top_stats=snapshot.statistics('lineno') # 内存占用数据获取
print ('[Top 10]')
for stat in top_stats[:10]: # 打印占用内存最大的10个子进程
print (stat)The output result is as follows:
[dechin@dechin-manjaro mmap ]$ python3 tracem.py
[Top 10]
tracem.py:8: size=78.2 KiB, count=2, average=39.1 KiB
If we use the top command If you want to directly detect the memory, there is no doubt that Google Chrome has the highest proportion of memory:
top - 10:04:08 up 6 days, 15:18, 5 users, load average: 0.23 , 0.33, 0.27
tasks: 309 total, 1 running, 264 sleeping, 23 stopped, 21 zombie
%Cpu(s): 0.6 us, 0.2 sy, 0.0 ni, 99.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem: 39913.6 total, 25450.8 free, 1875.7 used, 12587.1 buff/cache
MiB Swap: 16384.0 total, 16384.0 free, 0.0 used. 36775.8 avail Mem
Process number USER PR NI VIRT RES SHR %CPU %MEM TIME COMMAND
286734 dechin 20 0 36.6g 175832 117544 S 4.0 0.4 1:02.32 chromium
So track the memory usage of the child process based on the process number This is the key point of using tracemalloc. Here we find that the memory footprint of a numpy vector of size 10,000 is about 39.1 KiB, which is actually in line with our expectations:
In [3]: 39.1* 1024/4
Out[3]: 10009.6
Because this is almost the memory footprint of 10,000 float32 floating point numbers, which indicates that all elements have been stored in memory.
Use tracemalloc to track memory changes
In the above chapter we introduced the use of snapshot memory snapshots, then we can easily think of "taking" two memory snapshots and then comparing them. Can’t we get the size of memory changes by looking at the changes in the snapshot? Next, make a simple attempt:
# comp_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
snapshot0=tracemalloc.take_snapshot() # 第一张快照
length=10000
test_array=np.random.randn(length)
snapshot1=tracemalloc.take_snapshot() # 第二张快照
top_stats=snapshot1.compare_to(snapshot0,'lineno') # 快照对比
print ('[Top 10 differences]')
for stat in top_stats[:10]:
print (stat)The execution results are as follows:
[dechin@dechin-manjaro mmap]$ python3 comp_tracem.py
[Top 10 differences]
comp_tracem.py:9: size=78.2 KiB (78.2 KiB), count=2 (2), average=39.1 KiB
You can see that the average memory size difference before and after this snapshot is 39.1 KiB, if we change the dimension of the vector to 1000000:
length=1000000
Execute it again to see the effect:
[dechin@dechin-manjaro mmap]$ python3 comp_tracem.py
[Top 10 differences]
comp_tracem.py:9: size=7813 KiB (7813 KiB), count=2 (2), average=3906 KiB
We found that the result is 3906, It is equivalent to being magnified 100 times, which is more in line with expectations. Of course, if we calculate it carefully:
In [4]: 3906*1024/4
Out[4]: 999936.0
We find that there is no It is not completely a float32 type. Compared with the complete float32 type, part of the memory size is missing. I wonder if some 0s are generated in the middle and the size is automatically compressed? However, this issue is not what we want to focus on. We continue to test the memory change curve downward.
Memory usage curve
Continuing the content of the previous two chapters, we mainly test the memory space required by random arrays of different dimensions. Based on the above code module, a for Loop:
# comp_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
np.random.seed(1)
test_array=np.random.randn(length)
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
if 'comp_tracem.py' in str(stat): # 判断是否属于当前文件所产生的内存占用
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(m曲线em[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.plot(x,np.dot(x,4),color='red',label='Expect') # float32的预期占用空间
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('comp_mem.png')The drawn rendering is as follows:
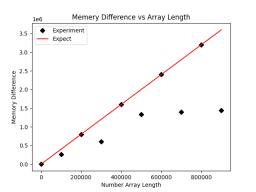
Here we find that although in most cases it meets the memory usage expectations, However, there are many points that occupy less than expected. We suspect that it is because there are 0 elements, so we slightly modified the code and added an operation to the original code to avoid the occurrence of 0 as much as possible:
# comp_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
np.random.seed(1)
test_array=np.random.randn(length)
test_array+=np.ones(length)*np.pi # 在原数组基础上加一个圆周率,内存不变
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
if 'comp_tracem.py' in str(stat):
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(mem[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.plot(x,np.dot(x,4),color='red',label='Expect')
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('comp_mem.png')After updating, the resulting graph is as follows:
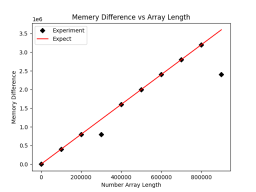
虽然不符合预期的点数少了,但是这里还是有两个点不符合预期的内存占用大小,疑似数据被压缩了。
mmap内存占用测试
在上面几个章节之后,我们已经基本掌握了内存追踪技术的使用,这里我们将其应用在mmap内存映射技术上,看看有什么样的效果。
将numpy数组写入txt文件
因为内存映射本质上是一个对系统文件的读写操作,因此这里我们首先将前面用到的numpy数组存储到txt文件中:
# write_array.py
import numpy as np
x=[]
y=[]
for length in range(1,1000000,100000):
np.random.seed(1)
test_array=np.random.randn(length)
test_array+=np.ones(length)*np.pi
np.savetxt('numpy_array_length_'+str(length)+'.txt',test_array)写入完成后,在当前目录下会生成一系列的txt文件:
-rw-r--r-- 1 dechin dechin 2500119 4月 12 10:09 numpy_array_length_100001.txt
-rw-r--r-- 1 dechin dechin 25 4月 12 10:09 numpy_array_length_1.txt
-rw-r--r-- 1 dechin dechin 5000203 4月 12 10:09 numpy_array_length_200001.txt
-rw-r--r-- 1 dechin dechin 7500290 4月 12 10:09 numpy_array_length_300001.txt
-rw-r--r-- 1 dechin dechin 10000356 4月 12 10:09 numpy_array_length_400001.txt
-rw-r--r-- 1 dechin dechin 12500443 4月 12 10:09 numpy_array_length_500001.txt
-rw-r--r-- 1 dechin dechin 15000526 4月 12 10:09 numpy_array_length_600001.txt
-rw-r--r-- 1 dechin dechin 17500606 4月 12 10:09 numpy_array_length_700001.txt
-rw-r--r-- 1 dechin dechin 20000685 4月 12 10:09 numpy_array_length_800001.txt
-rw-r--r-- 1 dechin dechin 22500788 4月 12 10:09 numpy_array_length_900001.txt
我们可以用head或者tail查看前n个或者后n个的元素:
[dechin@dechin-manjaro mmap]$ head -n 5 numpy_array_length_100001.txt
4.765938017253034786e+00
2.529836239939717846e+00
2.613420901326337642e+00
2.068624031433622612e+00
4.007000282914471967e+00
numpy文件读取测试
前面几个测试我们是直接在内存中生成的numpy的数组并进行内存监测,这里我们为了严格对比,统一采用文件读取的方式,首先我们需要看一下numpy的文件读取的内存曲线如何:
# npopen_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
test_array=np.loadtxt('numpy_array_length_'+str(length)+'.txt',delimiter=',')
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
if '/home/dechin/anaconda3/lib/python3.8/site-packages/numpy/lib/npyio.py:1153' in str(stat):
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(mem[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.plot(x,np.dot(x,8),color='red',label='Expect')
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('open_mem.png')需要注意的一点是,这里虽然还是使用numpy对文件进行读取,但是内存占用已经不是名为npopen_tracem.py的源文件了,而是被保存在了npyio.py:1153这个文件中,因此我们在进行内存跟踪的时候,需要调整一下对应的统计位置。最后的输出结果如下:
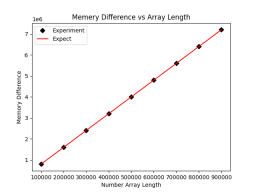
由于读入之后是默认以float64来读取的,因此预期的内存占用大小是元素数量×8,这里读入的数据内存占用是几乎完全符合预期的。
mmap内存占用测试
伏笔了一大篇幅的文章,最后终于到了内存映射技术的测试,其实内存映射模块mmap的使用方式倒也不难,就是配合os模块进行文件读取,基本上就是一行的代码:
# mmap_tracem.py
import tracemalloc
import numpy as np
import mmap
import os
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
test_array=mmap.mmap(os.open('numpy_array_length_'+str(length)+'.txt',os.O_RDWR),0) # 创建内存映射文件
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
print (stat)
if 'mmap_tracem.py' in str(stat):
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(mem[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('mmap.png')运行结果如下:
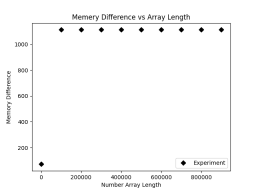
我们可以看到内存上是几乎没有波动的,因为我们并未把整个数组加载到内存中,而是在内存中加载了其内存映射的文件。我们能够以较小的内存开销读取文件中的任意字节位置。当我们去修改写入文件的时候需要额外的小心,因为对于内存映射技术来说,byte数量是需要保持不变的,否则内存映射就会发生错误。
The above is the detailed content of How to use tracemalloc in Python3 to track mmap memory changes. For more information, please follow other related articles on the PHP Chinese website!

 详细讲解Python之Seaborn(数据可视化)Apr 21, 2022 pm 06:08 PM
详细讲解Python之Seaborn(数据可视化)Apr 21, 2022 pm 06:08 PM本篇文章给大家带来了关于Python的相关知识,其中主要介绍了关于Seaborn的相关问题,包括了数据可视化处理的散点图、折线图、条形图等等内容,下面一起来看一下,希望对大家有帮助。
 详细了解Python进程池与进程锁May 10, 2022 pm 06:11 PM
详细了解Python进程池与进程锁May 10, 2022 pm 06:11 PM本篇文章给大家带来了关于Python的相关知识,其中主要介绍了关于进程池与进程锁的相关问题,包括进程池的创建模块,进程池函数等等内容,下面一起来看一下,希望对大家有帮助。
 Python自动化实践之筛选简历Jun 07, 2022 pm 06:59 PM
Python自动化实践之筛选简历Jun 07, 2022 pm 06:59 PM本篇文章给大家带来了关于Python的相关知识,其中主要介绍了关于简历筛选的相关问题,包括了定义 ReadDoc 类用以读取 word 文件以及定义 search_word 函数用以筛选的相关内容,下面一起来看一下,希望对大家有帮助。

 分享10款高效的VSCode插件,总有一款能够惊艳到你!!Mar 09, 2021 am 10:15 AM
分享10款高效的VSCode插件,总有一款能够惊艳到你!!Mar 09, 2021 am 10:15 AMVS Code的确是一款非常热门、有强大用户基础的一款开发工具。本文给大家介绍一下10款高效、好用的插件,能够让原本单薄的VS Code如虎添翼,开发效率顿时提升到一个新的阶段。
 Python数据类型详解之字符串、数字Apr 27, 2022 pm 07:27 PM
Python数据类型详解之字符串、数字Apr 27, 2022 pm 07:27 PM本篇文章给大家带来了关于Python的相关知识,其中主要介绍了关于数据类型之字符串、数字的相关问题,下面一起来看一下,希望对大家有帮助。
 详细介绍python的numpy模块May 19, 2022 am 11:43 AM
详细介绍python的numpy模块May 19, 2022 am 11:43 AM本篇文章给大家带来了关于Python的相关知识,其中主要介绍了关于numpy模块的相关问题,Numpy是Numerical Python extensions的缩写,字面意思是Python数值计算扩展,下面一起来看一下,希望对大家有帮助。
 python中文是什么意思Jun 24, 2019 pm 02:22 PM
python中文是什么意思Jun 24, 2019 pm 02:22 PMpythn的中文意思是巨蟒、蟒蛇。1989年圣诞节期间,Guido van Rossum在家闲的没事干,为了跟朋友庆祝圣诞节,决定发明一种全新的脚本语言。他很喜欢一个肥皂剧叫Monty Python,所以便把这门语言叫做python。


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

SublimeText3 Mac version
God-level code editing software (SublimeText3)

Zend Studio 13.0.1
Powerful PHP integrated development environment

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

