

 Technology peripheralsAIDistillation can also be Step-by-Step: the new method allows small models to be comparable to large models 2000 times the size
Technology peripheralsAIDistillation can also be Step-by-Step: the new method allows small models to be comparable to large models 2000 times the sizeDistillation can also be Step-by-Step: the new method allows small models to be comparable to large models 2000 times the size

Although large-scale language models have amazing capabilities, due to their large scale, the costs required for their deployment are often huge. The University of Washington, together with the Google Cloud Computing Artificial Intelligence Research Institute and Google Research, further solved this problem and proposed the Distilling Step-by-Step paradigm to help model training. Compared with LLM, this method is more effective in training small models and applying them to specific tasks, and requires less training data than traditional fine-tuning and distillation. On a benchmark task, their 770M T5 model outperformed the 540B PaLM model. Impressively, their model only used 80% of the available data.

While large language models (LLMs) have demonstrated impressive Few-shot learning capability, but it is difficult to deploy such a large-scale model in real applications. Dedicated infrastructure serving a 175 billion parameter scale LLM requires at least 350GB of GPU memory. What's more, today's state-of-the-art LLM is composed of more than 500 billion parameters, which means it requires more memory and computing resources. Such computing requirements are out of reach for most manufacturers, let alone applications that require low latency.
In order to solve this problem of large models, deployers often use smaller specific models instead. These smaller models are trained using common paradigms - fine-tuning or distillation. Fine-tuning upgrades a small pre-trained model using downstream human annotated data. Distillation trains an equally smaller model using the labels produced by the larger LLM. Unfortunately, these paradigms come at a cost while reducing model size: to achieve comparable performance to LLM, fine-tuning requires expensive human labels, while distillation requires large amounts of unlabeled data that is difficult to obtain.
In a paper titled "Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes", researchers from the University of Washington and Google A new simple mechanism, Distilling step-bystep, is introduced for training smaller models using less training data. This mechanism reduces the amount of training data required to fine-tune and distill the LLM, resulting in a smaller model size.

Paper link: https://arxiv.org/pdf/2305.02301 v1.pdf
#The core of this mechanism is to change the perspective and regard LLM as an agent that can reason, rather than as a source of noise labels. LLM can generate natural language rationales that can be used to explain and support the labels predicted by the model. For example, when asked "A gentleman carries golf equipment, what might he have? (a) clubs, (b) auditorium, (c) meditation center, (d) conference, (e) church" , LLM can answer "(a) club" through chain of thought (CoT) reasoning, and rationalize this label by explaining that "the answer must be something used to play golf." Of the above choices, only clubs are used for golf. We use these justifications as additional, richer information to train smaller models in a multi-task training setting and perform label prediction and justification prediction.
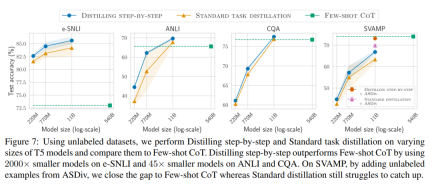
As shown in Figure 1, stepwise distillation can learn task-specific small models with less than 1/500 the number of parameters of LLM. Stepwise distillation also uses far fewer training examples than traditional fine-tuning or distillation.

Experimental results show that among the 4 NLP benchmarks, there are three promising experiments in conclusion.
- First, compared to fine-tuning and distillation, the stepwise distillation model achieves better performance on each data set, reducing the number of training instances by more than 50% on average (up to more than 85%) .
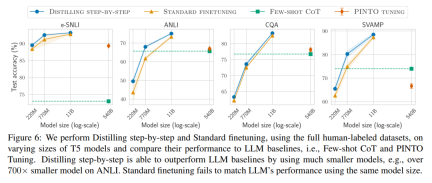
- Second, our model outperforms LLM when the model size is smaller (up to 2000 times smaller), greatly reducing the computational cost required for model deployment .
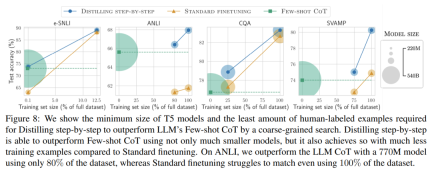
- Third, this research reduces the size of the model while also reducing the amount of data required to go beyond LLM. The researchers surpassed the performance of LLM with 540B parameters using a 770M T5 model. This smaller model uses only 80% of the labeled data set of existing fine-tuning methods.
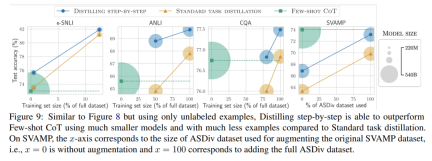
When there is only unlabeled data, the performance of the small model is still better than that of LLM - only using a 11B T5 model exceeds The performance of PaLM of 540B has been improved.
The study further shows that when a smaller model performs worse than LLM, stepwise distillation can more effectively utilize additional unlabeled data than standard distillation methods. Make smaller models comparable to the performance of LLM.
Stepwise Distillation
The researchers proposed a new paradigm of stepwise distillation, which uses the reasoning ability of LLM to predict its predictions to train smaller models in a data-efficient manner. Model. The overall framework is shown in Figure 2.
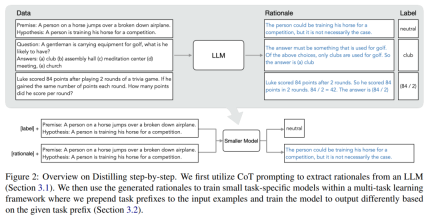
The paradigm has two simple steps: first, given an LLM and an An unlabeled data set prompts LLM to generate an output label and a justification for the label. The rationale is explained in natural language and provides support for the label predicted by the model (see Figure 2). Justification is an emergent behavioral property of current self-supervised LLMs.
Then, in addition to task labels, use these reasons to train smaller downstream models. To put it bluntly, reasons can provide richer and more detailed information to explain why an input is mapped to a specific output label.
Experimental results
The researchers verified the effectiveness of stepwise distillation in the experiment. First, compared to standard fine-tuning and task distillation methods, stepwise distillation helps achieve better performance with a much smaller number of training examples, significantly improving the data efficiency of learning small task-specific models.
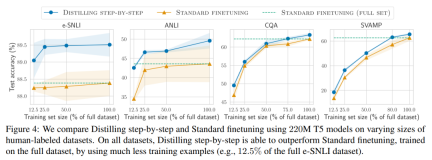
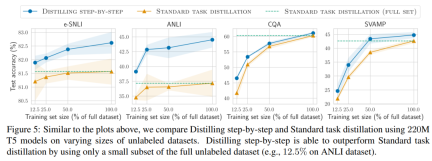
#Secondly, Studies show that the stepwise distillation method surpasses the performance of LLM with smaller model sizes, significantly reducing deployment costs compared to llm.
The above is the detailed content of Distillation can also be Step-by-Step: the new method allows small models to be comparable to large models 2000 times the size. For more information, please follow other related articles on the PHP Chinese website!

![Can't use ChatGPT! Explaining the causes and solutions that can be tested immediately [Latest 2025]](https://img.php.cn/upload/article/001/242/473/174717025174979.jpg?x-oss-process=image/resize,p_40) Can't use ChatGPT! Explaining the causes and solutions that can be tested immediately [Latest 2025]May 14, 2025 am 05:04 AM
Can't use ChatGPT! Explaining the causes and solutions that can be tested immediately [Latest 2025]May 14, 2025 am 05:04 AMChatGPT is not accessible? This article provides a variety of practical solutions! Many users may encounter problems such as inaccessibility or slow response when using ChatGPT on a daily basis. This article will guide you to solve these problems step by step based on different situations. Causes of ChatGPT's inaccessibility and preliminary troubleshooting First, we need to determine whether the problem lies in the OpenAI server side, or the user's own network or device problems. Please follow the steps below to troubleshoot: Step 1: Check the official status of OpenAI Visit the OpenAI Status page (status.openai.com) to see if the ChatGPT service is running normally. If a red or yellow alarm is displayed, it means Open
 Calculating The Risk Of ASI Starts With Human MindsMay 14, 2025 am 05:02 AM
Calculating The Risk Of ASI Starts With Human MindsMay 14, 2025 am 05:02 AMOn 10 May 2025, MIT physicist Max Tegmark told The Guardian that AI labs should emulate Oppenheimer’s Trinity-test calculus before releasing Artificial Super-Intelligence. “My assessment is that the 'Compton constant', the probability that a race to
 An easy-to-understand explanation of how to write and compose lyrics and recommended tools in ChatGPTMay 14, 2025 am 05:01 AM
An easy-to-understand explanation of how to write and compose lyrics and recommended tools in ChatGPTMay 14, 2025 am 05:01 AMAI music creation technology is changing with each passing day. This article will use AI models such as ChatGPT as an example to explain in detail how to use AI to assist music creation, and explain it with actual cases. We will introduce how to create music through SunoAI, AI jukebox on Hugging Face, and Python's Music21 library. Through these technologies, everyone can easily create original music. However, it should be noted that the copyright issue of AI-generated content cannot be ignored, and you must be cautious when using it. Let’s explore the infinite possibilities of AI in the music field together! OpenAI's latest AI agent "OpenAI Deep Research" introduces: [ChatGPT]Ope
 What is ChatGPT-4? A thorough explanation of what you can do, the pricing, and the differences from GPT-3.5!May 14, 2025 am 05:00 AM
What is ChatGPT-4? A thorough explanation of what you can do, the pricing, and the differences from GPT-3.5!May 14, 2025 am 05:00 AMThe emergence of ChatGPT-4 has greatly expanded the possibility of AI applications. Compared with GPT-3.5, ChatGPT-4 has significantly improved. It has powerful context comprehension capabilities and can also recognize and generate images. It is a universal AI assistant. It has shown great potential in many fields such as improving business efficiency and assisting creation. However, at the same time, we must also pay attention to the precautions in its use. This article will explain the characteristics of ChatGPT-4 in detail and introduce effective usage methods for different scenarios. The article contains skills to make full use of the latest AI technologies, please refer to it. OpenAI's latest AI agent, please click the link below for details of "OpenAI Deep Research"
 Explaining how to use the ChatGPT app! Japanese support and voice conversation functionMay 14, 2025 am 04:59 AM
Explaining how to use the ChatGPT app! Japanese support and voice conversation functionMay 14, 2025 am 04:59 AMChatGPT App: Unleash your creativity with the AI assistant! Beginner's Guide The ChatGPT app is an innovative AI assistant that handles a wide range of tasks, including writing, translation, and question answering. It is a tool with endless possibilities that is useful for creative activities and information gathering. In this article, we will explain in an easy-to-understand way for beginners, from how to install the ChatGPT smartphone app, to the features unique to apps such as voice input functions and plugins, as well as the points to keep in mind when using the app. We'll also be taking a closer look at plugin restrictions and device-to-device configuration synchronization
 How do I use the Chinese version of ChatGPT? Explanation of registration procedures and feesMay 14, 2025 am 04:56 AM
How do I use the Chinese version of ChatGPT? Explanation of registration procedures and feesMay 14, 2025 am 04:56 AMChatGPT Chinese version: Unlock new experience of Chinese AI dialogue ChatGPT is popular all over the world, did you know it also offers a Chinese version? This powerful AI tool not only supports daily conversations, but also handles professional content and is compatible with Simplified and Traditional Chinese. Whether it is a user in China or a friend who is learning Chinese, you can benefit from it. This article will introduce in detail how to use ChatGPT Chinese version, including account settings, Chinese prompt word input, filter use, and selection of different packages, and analyze potential risks and response strategies. In addition, we will also compare ChatGPT Chinese version with other Chinese AI tools to help you better understand its advantages and application scenarios. OpenAI's latest AI intelligence
 5 AI Agent Myths You Need To Stop Believing NowMay 14, 2025 am 04:54 AM
5 AI Agent Myths You Need To Stop Believing NowMay 14, 2025 am 04:54 AMThese can be thought of as the next leap forward in the field of generative AI, which gave us ChatGPT and other large-language-model chatbots. Rather than simply answering questions or generating information, they can take action on our behalf, inter
 An easy-to-understand explanation of the illegality of creating and managing multiple accounts using ChatGPTMay 14, 2025 am 04:50 AM
An easy-to-understand explanation of the illegality of creating and managing multiple accounts using ChatGPTMay 14, 2025 am 04:50 AMEfficient multiple account management techniques using ChatGPT | A thorough explanation of how to use business and private life! ChatGPT is used in a variety of situations, but some people may be worried about managing multiple accounts. This article will explain in detail how to create multiple accounts for ChatGPT, what to do when using it, and how to operate it safely and efficiently. We also cover important points such as the difference in business and private use, and complying with OpenAI's terms of use, and provide a guide to help you safely utilize multiple accounts. OpenAI


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Atom editor mac version download
The most popular open source editor

WebStorm Mac version
Useful JavaScript development tools

SublimeText3 English version
Recommended: Win version, supports code prompts!

Dreamweaver Mac version
Visual web development tools

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

