

 Technology peripheralsAIDoes word embedding represent too large a proportion of parameters? MorphTE method 20 times compression effect without loss
Technology peripheralsAIDoes word embedding represent too large a proportion of parameters? MorphTE method 20 times compression effect without lossDoes word embedding represent too large a proportion of parameters? MorphTE method 20 times compression effect without loss

Introduction
Word embedding representation is the basis for various natural language processing tasks such as machine translation, question answering, text classification, etc. It usually accounts for 20% to 90% of the total model parameters. Storing and accessing these embeddings requires a large amount of space, which is not conducive to model deployment and application on devices with limited resources. In response to this problem, this article proposes the MorphTE word embedding compression method. MorphTE combines the powerful compression capabilities of tensor product operations with prior knowledge of language morphology to achieve high compression of word embedding parameters (more than 20 times) while maintaining the accuracy of the model. performance.

- ## Paper link: https://arxiv.org/abs/2210.15379
- Open source code: https://github.com/bigganbing/Fairseq_MorphTE
This article proposes The MorphTE word embedding compression method first divides words into the smallest units with semantic meaning - morphemes, and trains a low-dimensional vector representation for each morpheme, and then uses tensor products to realize the mathematical representation of quantum entangled states of low-dimensional morpheme vectors. , thereby obtaining a high-dimensional word representation.
01 The morpheme composition of a wordIn linguistics, a morpheme is the smallest unit with specific semantic or grammatical functions. For languages such as English, a word can be split into smaller units of morphemes such as roots and affixes. For example, "unkindly" can be broken down into "un" for negation, "kind" for something like "friendly," and "ly" for an adverb. For Chinese, a Chinese character can also be split into smaller units such as radicals. For example, "MU" can be split into "氵" and "木" which represent water.

02 Compressed representation of word embeddings in the form of entangled tensors

 ##where
##where
, r is rank, n is order, represents tensor product. Word2ket only needs to store and use these low-dimensional vectors to build high-dimensional word vectors, thereby achieving effective parameter reduction. For example, when r = 2 and n = 3, a word vector with a dimension of 512 can be obtained by two groups of three low-dimensional vector tensor products with a dimension of 8 in each group. At this time, the required number of parameters is reduced from 512 to 48 . 03 Morphology-enhanced tensorized word embedding compression representation
Through tensor product, Word2ket can achieve obvious parameter compression. However, it suffers from high compression and machine translation problems. For more complex tasks, it is usually difficult to achieve the effect before compression. Since low-dimensional vectors are the basic units that make up entanglement tensors, and morphemes are the basic units that make up words. This study considers the introduction of linguistic knowledge and proposes MorphTE, which trains low-dimensional morpheme vectors and uses the tensor product of the morpheme vectors contained in the word to construct the corresponding word embedding representation.
Specifically, first use the morpheme segmentation tool to segment the words in the word list V. The morphemes of all words will form a morpheme list M, and the number of morphemes will be significantly lower than the number of words ().
For each word, construct its morpheme index vector, which points to the position of the morpheme contained in each word in the morpheme table. The morpheme index vectors of all words form a  morpheme index matrix, where n is the order of MorphTE.
morpheme index matrix, where n is the order of MorphTE.
For the j-th word  in the vocabulary, use its morpheme index vector
in the vocabulary, use its morpheme index vector  to parameterize it from the r group The corresponding morpheme vector is indexed into the morpheme embedding matrix, and the corresponding word embedding is obtained by entangled tensor representation through tensor product. The process is formalized as follows:
to parameterize it from the r group The corresponding morpheme vector is indexed into the morpheme embedding matrix, and the corresponding word embedding is obtained by entangled tensor representation through tensor product. The process is formalized as follows:

Through the above methods, MophTE can inject morpheme-based linguistic prior knowledge into the word embedding representation, and the sharing of morpheme vectors between different words can explicitly build inter-word connections. In addition, the number and vector dimensions of morphemes are much lower than the size and dimension of the vocabulary, and MophTE achieves compression of word embedding parameters from both perspectives. Therefore, MophTE is able to achieve high-quality compression of word embedding representations.
Experiments
This article mainly conducts experiments on translation, question and answer tasks in different languages, and compares it with related decomposition-based word embedding compression methods.
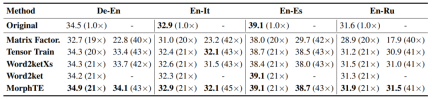
As you can see from the table, MorphTE can adapt to different languages such as English, German, and Italian. At a compression ratio of more than 20 times, MorphTE is able to maintain the effect of the original model, while almost all other compression methods show a decrease in effect. In addition, MorphTE performs better than other compression methods on different data sets at a compression ratio of more than 40 times.

Similarly, MorphTE achieved a compression ratio of 81 times and 38 times respectively on WikiQA's question and answer task and SNLI's natural language reasoning task. , while maintaining the effect of the model.
Conclusion
MorphTE combines a priori morphological language knowledge and the powerful compression capability of tensor products to achieve high-quality compression of word embeddings. Experiments on different languages and tasks show that MorphTE can achieve 20 to 80 times compression of word embedding parameters without damaging the effect of the model. This verifies that the introduction of morpheme-based linguistic knowledge can improve the learning of compressed representations of word embeddings. Although MorphTE currently only models morphemes, it can actually be extended into a general word embedding compression enhancement framework that explicitly models more a priori linguistic knowledge such as prototypes, parts of speech, capitalization, etc., to further improve word embedding compression. express.
The above is the detailed content of Does word embedding represent too large a proportion of parameters? MorphTE method 20 times compression effect without loss. For more information, please follow other related articles on the PHP Chinese website!

 Most Used 10 Power BI Charts - Analytics VidhyaApr 16, 2025 pm 12:05 PM
Most Used 10 Power BI Charts - Analytics VidhyaApr 16, 2025 pm 12:05 PMHarnessing the Power of Data Visualization with Microsoft Power BI Charts In today's data-driven world, effectively communicating complex information to non-technical audiences is crucial. Data visualization bridges this gap, transforming raw data i
 Expert Systems in AIApr 16, 2025 pm 12:00 PM
Expert Systems in AIApr 16, 2025 pm 12:00 PMExpert Systems: A Deep Dive into AI's Decision-Making Power Imagine having access to expert advice on anything, from medical diagnoses to financial planning. That's the power of expert systems in artificial intelligence. These systems mimic the pro
 Three Of The Best Vibe Coders Break Down This AI Revolution In CodeApr 16, 2025 am 11:58 AM
Three Of The Best Vibe Coders Break Down This AI Revolution In CodeApr 16, 2025 am 11:58 AMFirst of all, it’s apparent that this is happening quickly. Various companies are talking about the proportions of their code that are currently written by AI, and these are increasing at a rapid clip. There’s a lot of job displacement already around
 Runway AI's Gen-4: How Can AI Montage Go Beyond AbsurdityApr 16, 2025 am 11:45 AM
Runway AI's Gen-4: How Can AI Montage Go Beyond AbsurdityApr 16, 2025 am 11:45 AMThe film industry, alongside all creative sectors, from digital marketing to social media, stands at a technological crossroad. As artificial intelligence begins to reshape every aspect of visual storytelling and change the landscape of entertainment
 How to Enroll for 5 Days ISRO AI Free Courses? - Analytics VidhyaApr 16, 2025 am 11:43 AM
How to Enroll for 5 Days ISRO AI Free Courses? - Analytics VidhyaApr 16, 2025 am 11:43 AMISRO's Free AI/ML Online Course: A Gateway to Geospatial Technology Innovation The Indian Space Research Organisation (ISRO), through its Indian Institute of Remote Sensing (IIRS), is offering a fantastic opportunity for students and professionals to
 Local Search Algorithms in AIApr 16, 2025 am 11:40 AM
Local Search Algorithms in AIApr 16, 2025 am 11:40 AMLocal Search Algorithms: A Comprehensive Guide Planning a large-scale event requires efficient workload distribution. When traditional approaches fail, local search algorithms offer a powerful solution. This article explores hill climbing and simul
 OpenAI Shifts Focus With GPT-4.1, Prioritizes Coding And Cost EfficiencyApr 16, 2025 am 11:37 AM
OpenAI Shifts Focus With GPT-4.1, Prioritizes Coding And Cost EfficiencyApr 16, 2025 am 11:37 AMThe release includes three distinct models, GPT-4.1, GPT-4.1 mini and GPT-4.1 nano, signaling a move toward task-specific optimizations within the large language model landscape. These models are not immediately replacing user-facing interfaces like
 The Prompt: ChatGPT Generates Fake PassportsApr 16, 2025 am 11:35 AM
The Prompt: ChatGPT Generates Fake PassportsApr 16, 2025 am 11:35 AMChip giant Nvidia said on Monday it will start manufacturing AI supercomputers— machines that can process copious amounts of data and run complex algorithms— entirely within the U.S. for the first time. The announcement comes after President Trump si


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Atom editor mac version download
The most popular open source editor

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

Dreamweaver Mac version
Visual web development tools

Notepad++7.3.1
Easy-to-use and free code editor

