



Microsoft has announced that the document translation feature built into Azure Translator can now scan and translate PDF documents. The company says users no longer need to pre-process documents through an OCR engine before trying to translate them.
The Document Translation feature, first launched a year ago, can translate multiple documents into more than 110 languages and dialects at once. Today's update means PDF files are now fully supported, as well as Word and PowerPoint files. According to the company, being able to scan PDFs with scanned image content is highly desirable.
Explaining some of the features, Microsoft has said:
The File Translation Service now has the intelligence to
- identify whether a PDF document contains scanned image content,
- Route PDFs containing scanned image content to the internal OCR engine to extract text,
- Reconstruct the translated content into regular text PDFs while preserving the original layout and structure.
While document translation is available in 110 languages and dialects, the new scanning feature is only available in 68 source languages and 87 target languages. Microsoft has promised to add support for more "in due course."
Microsoft says there are no code changes required to start using the new feature, and all PDFs can be submitted to Translator immediately. New features won’t cost customers more money. There are two pricing plans available for document translation through Azure; they include a pay-as-you-go plan and a D3 quantity discount plan for higher volumes.
The above is the detailed content of Azure Translator can now scan and translate PDF documents. For more information, please follow other related articles on the PHP Chinese website!

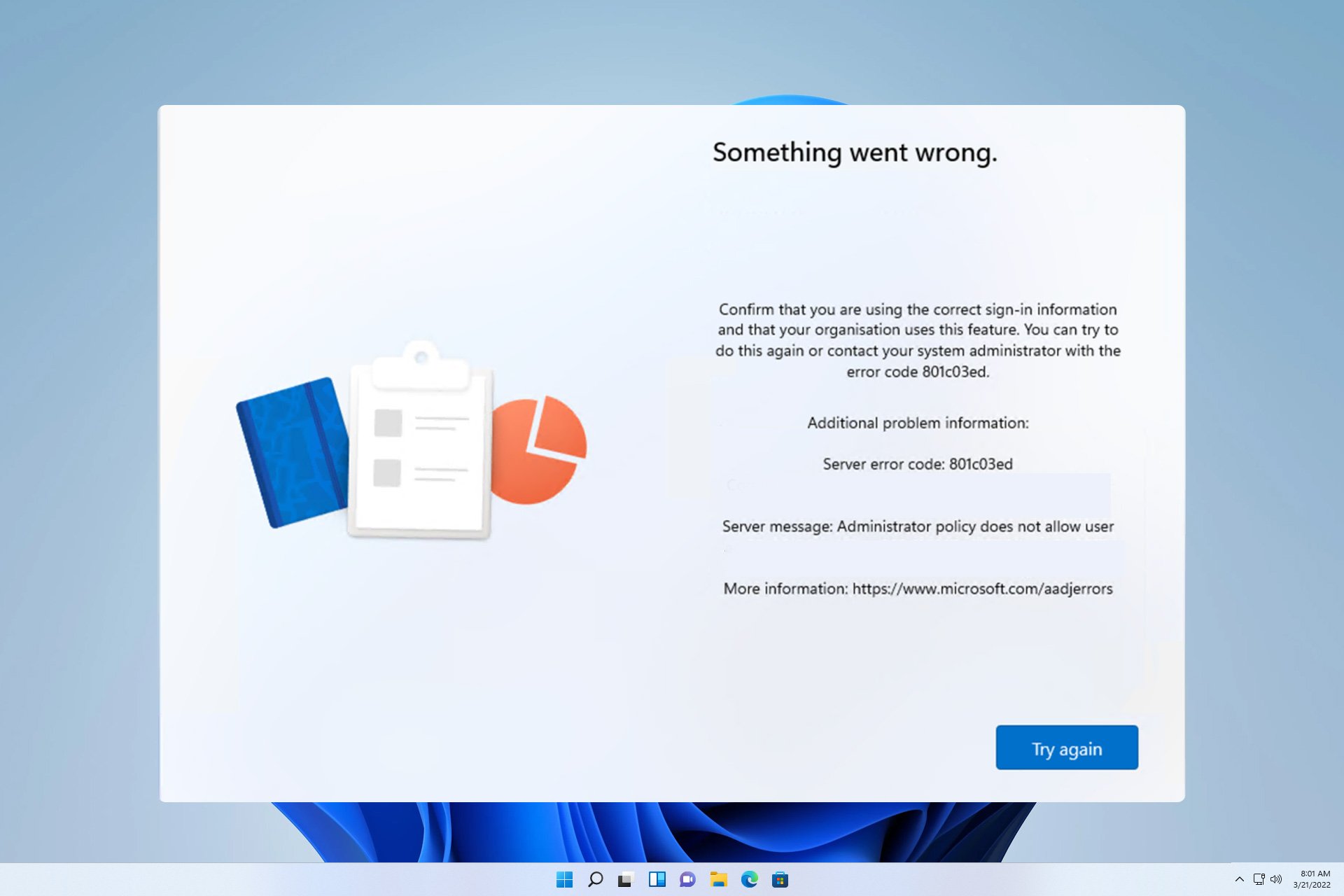 错误代码 801c03ed:如何在 Windows 11 上修复它Oct 04, 2023 pm 06:05 PM
错误代码 801c03ed:如何在 Windows 11 上修复它Oct 04, 2023 pm 06:05 PM错误801c03ed通常附带以下消息:管理员策略不允许此用户加入设备。此错误消息将阻止你安装Windows并加入网络,从而阻止你使用电脑,因此尽快解决此问题非常重要。什么是错误代码801c03ed?这是一个Windows安装错误,由于以下原因而发生:Azure设置不允许新用户加入。Azure上未启用设备对象。Azure面板中的硬件哈希出现故障。如何修复Windows801上的错误代码03c11ed?1.检查Intune设置登录到Azure门户。导航到“设备”,然后选择“设备设置”。将“用户可以将
 如何在 Google Drive 中临时/永久旋转 PDFApr 13, 2023 pm 10:46 PM
如何在 Google Drive 中临时/永久旋转 PDFApr 13, 2023 pm 10:46 PM当您扫描 PDF 文档并将其上传到您的 Google Drive 时,该 PDF 处于颠倒方向或处于从右到左方向的可能性非常高。当然,阅读不在直立位置的文档是一件痛苦的事情。有时,您只需要暂时查看文档,将其关闭并离开。有时,您需要永久更正 PDF 的方向,这样您就可以省去将来再次更正其方向的麻烦。好吧,您终于可以笑到最后了,我们已经为您的需求提供了完美的解决方案。在本文中,我们详细解释了如何轻松地临时和永久更正 Google Drive 中 PDF 的方向。希望你喜欢!Bonus Cookie:
 Python 处理 PDF:PyMuPDF 的安装与使用!Apr 14, 2023 pm 05:46 PM
Python 处理 PDF:PyMuPDF 的安装与使用!Apr 14, 2023 pm 05:46 PM大家好,我是Python人工智能技术一、PyMuPDF简介1.介绍在介绍PyMuPDF之前,先来了解一下MuPDF,从命名形式中就可以看出,PyMuPDF是MuPDF的Python接口形式。MuPDFMuPDF是一个轻量级的PDF、XPS和电子书查看器。MuPDF由软件库、命令行工具和各种平台的查看器组成。MuPDF中的渲染器专为高质量抗锯齿图形量身定制。它以精确到像素的几分之一内的度量和间距呈现文本,以在屏幕上再现打印页面的外观时获得最高保真度。这个观察器很小,速度很快,但是很完整。它支持多种
 PHP怎么在创建PDF文件时设置文件标题Mar 24, 2023 am 09:44 AM
PHP怎么在创建PDF文件时设置文件标题Mar 24, 2023 am 09:44 AMPDF文件标题是一个非常重要的元素,其实就是PDF文件的名称。PDF文件标题可以为用户提供方便,使其能够更好地识别文件,并且能够方便用户进行存储和检索。为了设置PDF文件标题,需要通过PHP程序以下面的方式来操作。
 超简单!用 Python 为图片和 PDF 去掉水印Apr 12, 2023 pm 11:43 PM
超简单!用 Python 为图片和 PDF 去掉水印Apr 12, 2023 pm 11:43 PM网上下载的 pdf 学习资料有一些会带有水印,非常影响阅读。比如下面的图片就是在 pdf 文件上截取出来的,今天我们就来用Python解决这个问题。安装模块PIL:Python Imaging Library 是 python 上非常强大的图像处理标准库,但是只能支持 python 2.7,于是就有志愿者在 PIL 的基础上创建了支持 python 3的 pillow,并加入了一些新的特性。pip install pillow pymupdf 可以用 python 访问扩展名为*.pdf、
 pdf打印不显示红色电子章怎么办Mar 22, 2023 pm 12:02 PM
pdf打印不显示红色电子章怎么办Mar 22, 2023 pm 12:02 PMpdf打印不显示红色电子章是因为章被加了PDF限制,其解决办法:1、打开Word文档,单击Office按钮;2、查找并单击Word选项按钮;3、找到并单击“显示”选项;4、勾选“打印在Word中创建的图形”和“打印隐藏文字”选项,然后单击确定按钮即可。
 利用Azure语义搜索与OpenAI,打造认知搜索系统Oct 12, 2023 am 10:18 AM
利用Azure语义搜索与OpenAI,打造认知搜索系统Oct 12, 2023 am 10:18 AM旨在简化文档搜索,多种服务和平台的结合都是获得无与伦比性能的关键。在本文中,我们将探索一种将 Azure 认知服务的强大功能与 OpenAI 的功能相结合的整体方法。通过深入研究意图识别、文档过滤、特定领域的算法和文本摘要,您将学习创建一个不仅可以理解用户意图而且可以有效处理和呈现信息的系统。
 一页很长的pdf怎么打印Dec 30, 2020 pm 03:02 PM
一页很长的pdf怎么打印Dec 30, 2020 pm 03:02 PM一页很长的pdf的打印方法:1、用pdf软件打开PDF文件;2、点击“打印”;3、点击缩放类型,并选择“每张纸多页面”;4、设置好页数并点击“打印”即可。

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

Atom editor mac version download
The most popular open source editor

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

Dreamweaver CS6
Visual web development tools

