
Home >Java >javaTutorial >How to use Java to crawl comics
How to use Java to crawl comics

- 王林forward
- 2023-05-13 23:10:191560browse
Crawling results
Program running effect
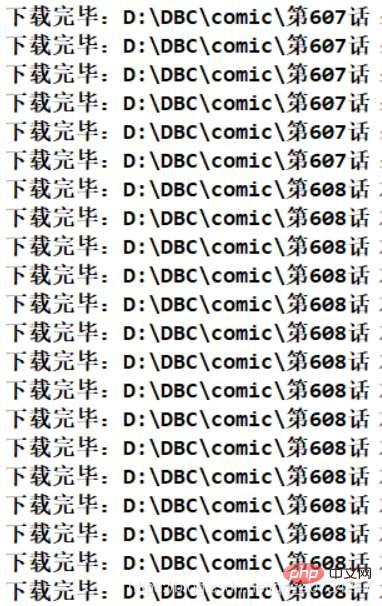
Obtained file directory information
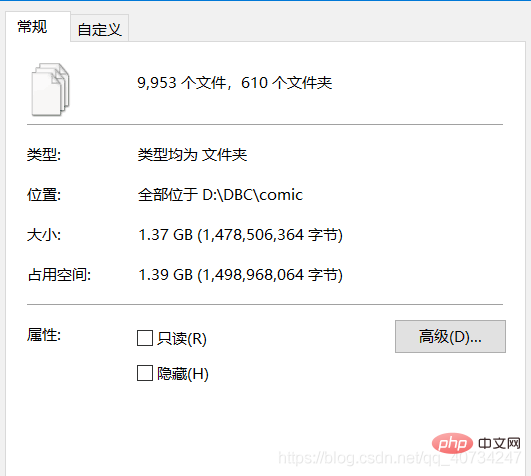
Total information of the file

##Note : There is a small problem here. Some of the obtained files may not have suffix names, but they can be opened and viewed as pictures. I don’t know the specific reason. Since it does not affect it, I will ignore it. (Or use your own code to rename the file.)
Website structure analysis Let’s take a comic as an example. First, look at the number above. That number represents the catalog page of the comic. It is very important that on this page there isComic Table of Contents. Then click on the chapters in the directory one by one to see the comic information of each chapter.


I found it with my eyes), I found that all comics are indeed loaded in advance. Page link. It is not loaded asynchronously.
Here I click on the comic picture to get the address of the picture, then compare it with the link I found, and then I can see it. Then I splice the url and get all the links.

Content page–>Chapter page–>Comic page
For this, get this script as a string, then use "[" and "]" to get the string, and then use fastjson to convert it into a List collection.// 获取的script 无法直接解析,必须先将 page url 取出来,
// 这里以 [ ] 为界限,分割字符串。
String pageUrls = script.data();
int start = pageUrls.indexOf("[");
int end = pageUrls.indexOf("]") + 1;
String urls = pageUrls.substring(start, end);
//json 转 集合,这个可以总结一下,不熟悉。
List<String> urlList = JSONArray.parseArray(urls, String.class);I emphasize one point here: the text method of the Element object is to obtain visible information, while the data method is to obtain invisible information. The script information is not directly visible, so I use the data method to get it. The so-called visible and invisible refers to the information that can be displayed on the web page and can be obtained by viewing the source. For example, escape characters become escaped characters when obtained through text ext. Code partHttpClientUtil classUse HttpClient connection pool to manage connections, but I did not use multi-threading because I only have one IP address. In case it is blocked, Very troublesome. The thread time is still acceptable. After all, a comic only lasts about ten minutes. (Take Chapter 600 as an example) package com.comic;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;
public class HttpClientUtil {
private static final int TIME_OUT = 10 * 1000;
private static PoolingHttpClientConnectionManager pcm; //HttpClient 连接池管理类
private static RequestConfig requestConfig;
static {
requestConfig = RequestConfig.custom()
.setConnectionRequestTimeout(TIME_OUT)
.setConnectTimeout(TIME_OUT)
.setSocketTimeout(TIME_OUT).build();
pcm = new PoolingHttpClientConnectionManager();
pcm.setMaxTotal(50);
pcm.setDefaultMaxPerRoute(10); //这里可能用不到这个东西。
}
public static CloseableHttpClient getHttpClient() {
return HttpClients.custom()
.setConnectionManager(pcm)
.setDefaultRequestConfig(requestConfig)
.build();
}
}ComicSpider classThe most important class is used to parse HTML pages to obtain link data. Note: The DIR_PATH here is a hard-coded path, so if you want to test, please create the relevant directory yourself. package com.comic;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.stream.Collectors;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.config.CookieSpecs;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.alibaba.fastjson.JSONArray;
public class ComicSpider {
private static final String DIR_PATH = "D:/DBC/comic/";
private String url;
private String root;
private CloseableHttpClient httpClient;
public ComicSpider(String url, String root) {
this.url = url;
// 这里不做非空校验,或者使用下面这个。
// Objects.requireNonNull(root);
if (root.charAt(root.length()-1) == '/') {
root = root.substring(0, root.length()-1);
}
this.root = root;
this.httpClient = HttpClients.createDefault();
}
public void start() {
try {
String html = this.getHtml(url); //获取漫画主页数据
List<Chapter> chapterList = this.mapChapters(html); //解析数据,得到各话的地址
this.download(chapterList); //依次下载各话。
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 从url中获取原始的网页数据
* @throws IOException
* @throws ClientProtocolException
* */
private String getHtml(String url) throws ClientProtocolException, IOException {
HttpGet get = new HttpGet(url);
//下面这两句,是因为总是报一个 Invalid cookie header,然后我在网上找到的解决方法。(去掉的话,不影响使用)。
RequestConfig defaultConfig = RequestConfig.custom().setCookieSpec(CookieSpecs.STANDARD).build();
get.setConfig(defaultConfig);
//因为是初学,而且我这里只是请求一次数据即可,这里就简单设置一下 UA
get.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3100.0 Safari/537.36");
HttpEntity entity = null;
String html = null;
try (CloseableHttpResponse response = httpClient.execute(get)) {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode == 200) {
entity = response.getEntity();
if (entity != null) {
html = EntityUtils.toString(entity, "UTF-8");
}
}
}
return html;
}
//获取章节名 链接地址
private List<Chapter> mapChapters(String html) {
Document doc = Jsoup.parse(html, "UTF-8");
Elements name_urls = doc.select("#chapter-list-1 > li > a");
/* 不采用直接返回map的方式,封装一下。
return name_urls.stream()
.collect(Collectors.toMap(Element::text,
name_url->root+name_url.attr("href")));
*/
return name_urls.stream()
.map(name_url->new Chapter(name_url.text(),
root+name_url.attr("href")))
.collect(Collectors.toList());
}
/**
* 依次下载对应的章节
* 我使用当线程来下载,这种网站,多线程一般容易引起一些问题。
* 方法说明:
* 使用循环迭代的方法,以 name 创建文件夹,然后依次下载漫画。
* */
public void download(List<Chapter> chapterList) {
chapterList.forEach(chapter->{
//按照章节创建文件夹,每一个章节一个文件夹存放。
File dir = new File(DIR_PATH, chapter.getName());
if (!dir.exists()) {
if (!dir.mkdir()) {
try {
throw new FileNotFoundException("无法创建指定文件夹"+dir);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
//开始按照章节下载
try {
List<ComicPage> urlList = this.getPageUrl(chapter);
urlList.forEach(page->{
SinglePictureDownloader downloader = new SinglePictureDownloader(page, dir.getAbsolutePath());
downloader.download();
});
} catch (IOException e) {
e.printStackTrace();
}
}
});
}
//获取每一个页漫画的位置
private List<ComicPage> getPageUrl(Chapter chapter) throws IOException {
String html = this.getHtml(chapter.getUrl());
Document doc = Jsoup.parse(html, "UTF-8");
Element script = doc.getElementsByTag("script").get(2); //获取第三个脚本的数据
// 获取的script 无法直接解析,必须先将 page url 取出来,
// 这里以 [ ] 为界限,分割字符串。
String pageUrls = script.data();
int start = pageUrls.indexOf("[");
int end = pageUrls.indexOf("]") + 1;
String urls = pageUrls.substring(start, end);
//json 转 集合,这个可以总结一下,不熟悉。
List<String> urlList = JSONArray.parseArray(urls, String.class);
AtomicInteger index=new AtomicInteger(0); //我无法使用索引,这是别人推荐的方式
return urlList.stream() //注意这里拼接的不是 root 路径,而是一个新的路径
.map(url->new ComicPage(index.getAndIncrement(),"https://restp.dongqiniqin.com//"+url))
.collect(Collectors.toList());
}
}
Note: My idea here is that all comics are stored in the DIR_PATH directory. Then each chapter is a subdirectory (named after the chapter name), and then the comics of each chapter are placed in a directory, but there is a problem here. Because the comics are actually read page by page, there is a problem with the order of the comics (after all, a pile of comics out of order looks very laborious, although I am not here to read comics). So I gave each comic page a number and numbered it according to the order in the script above. But since I'm using Java8's Lambda expressions, I can't use the index. (This involves another issue). The solution here is what I saw recommended by others: you can increase the value of index every time you call the getAndIncrement method of index, which is very convenient.
AtomicInteger index=new AtomicInteger(0); //我无法使用索引,这是别人推荐的方式 return urlList.stream() //注意这里拼接的不是 root 路径,而是一个新的路径 .map(url->new ComicPage(index.getAndIncrement(),"https://restp.dongqiniqin.com//"+url)) .collect(Collectors.toList());Chapter and ComicPage classesTwo entity classes, because they are object-oriented, I designed two simple entity classes to encapsulate the information, so that the operation is more convenient. The Chapter class represents the information of each chapter in the directory, the name of the chapter and the link to the chapter. The ComicPage class represents each page of comic information in each chapter, the number and link address of each page.
package com.comic;
public class Chapter {
private String name; //章节名
private String url; //对应章节的链接
public Chapter(String name, String url) {
this.name = name;
this.url = url;
}
public String getName() {
return name;
}
public String getUrl() {
return url;
}
@Override
public String toString() {
return "Chapter [name=" + name + ", url=" + url + "]";
}
}package com.comic;
public class ComicPage {
private int number; //每一页的序号
private String url; //每一页的链接
public ComicPage(int number, String url) {
this.number = number;
this.url = url;
}
public int getNumber() {
return number;
}
public String getUrl() {
return url;
}
}
SinglePictureDownloader 类
因为前几天使用多线程下载类爬取图片,发现速度太快了,ip 好像被封了,所以就又写了一个当线程的下载类。 它的逻辑很简单,主要是获取对应的漫画页链接,然后使用get请求,将它保存到对应的文件夹中。(它的功能大概和获取网络中的一张图片类似,既然你可以获取一张,那么成千上百也没有问题了。)
package com.comic;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.util.Random;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.util.EntityUtils;
import com.m3u8.HttpClientUtil;
public class SinglePictureDownloader {
private CloseableHttpClient httpClient;
private ComicPage page;
private String filePath;
private String[] headers = {
"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14",
"Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11",
"Opera/9.25 (Windows NT 5.1; U; en)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12",
"Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9",
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 "
};
public SinglePictureDownloader(ComicPage page, String filePath) {
this.httpClient = HttpClientUtil.getHttpClient();
this.page = page;
this.filePath = filePath;
}
public void download() {
HttpGet get = new HttpGet(page.getUrl());
String url = page.getUrl();
//取文件的扩展名
String prefix = url.substring(url.lastIndexOf("."));
Random rand = new Random();
//设置请求头
get.setHeader("User-Agent", headers[rand.nextInt(headers.length)]);
HttpEntity entity = null;
try (CloseableHttpResponse response = httpClient.execute(get)) {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode == 200) {
entity = response.getEntity();
if (entity != null) {
File picFile = new File(filePath, page.getNumber()+prefix);
try (OutputStream out = new BufferedOutputStream(new FileOutputStream(picFile))) {
entity.writeTo(out);
System.out.println("下载完毕:" + picFile.getAbsolutePath());
}
}
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
//关闭实体,关于 httpClient 的关闭资源,有点不太了解。
EntityUtils.consume(entity);
} catch (IOException e) {
e.printStackTrace();
}
}
}
}Main 类
package com.comic;
public class Main {
public static void main(String[] args) {
String root = "https://www.manhuaniu.com/"; //网站根路径,用于拼接字符串
String url = "https://www.manhuaniu.com/manhua/5830/"; //第一张第一页的url
ComicSpider spider = new ComicSpider(url, root);
spider.start();
}
}The above is the detailed content of How to use Java to crawl comics. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- How to set margins for buttons inside a LinearLayout programmatically?
- Why and How Should You Synchronize on String Objects in Java?
- How Can I Customize Input Tokenization in Java Using `Scanner.useDelimiter()`?
- How Can I Dynamically Find All Subclasses of a Base Class in Java at Runtime?
- How Can I Format Java 8's LocalDate with Jackson Without Annotations?