
 Technology peripheralsAIYou can play Genshin Impact just by moving your mouth! Use AI to switch characters and attack enemies. Netizen: 'Ayaka, use Kamiri-ryu Frost Destruction'
Technology peripheralsAIYou can play Genshin Impact just by moving your mouth! Use AI to switch characters and attack enemies. Netizen: 'Ayaka, use Kamiri-ryu Frost Destruction'
Speaking of domestic games that have become popular all over the world in the past two years, Genshin Impact definitely takes the cake.
According to this year’s Q1 quarter mobile game revenue survey report released in May, “Genshin Impact” firmly won the first place among card-drawing mobile games with an absolute advantage of 567 million U.S. dollars. This also announced that “Genshin Impact” 》In just 18 months after its launch, the total revenue on the mobile platform alone exceeded US$3 billion (approximately RM13 billion).

Now, the last 2.8 island version before the opening of Xumi is long overdue. After a long draft period, there are finally new plots and areas to play.
But I don’t know how many “Liver Emperors” there are. Now that the island has been fully explored, grass has begun to grow again.

There are 182 treasure chests in total and 1 Mora box (not included)
There is nothing to be afraid of during the long grass period, there is never a shortage in the Genshin Impact area Whole job.
No, during the long grass period, some players used XVLM wenet STARK to make a voice control project to play Genshin Impact.
For example, when he said "Use Tactic 3 to attack the fire slime in the middle", Zhongli first used a shield, Ling Hua did a step step and then said "Sorry", and the group destroyed 4 of them. Fire Slime.

Similarly, after saying "attack the Daqiuqiu people in the middle", Diona used E to set up a shield, Ling Hua followed up with an E and then 3A to clean up beautifully. Two large Qiuqiu people were lost.

As can be seen on the lower left, the entire process was done without any use of hands.
Digest Fungi said that he is an expert, he can save his hands when writing books in the future, and said that mom no longer has to worry about tenosynovitis from playing Genshin Impact!
The project is currently open source on GitHub:

GitHub link:
https://github.com/7eu7d7/genshin_voice_play
Good Genshin Impact, he was actually played as a Pokémon
Such a live-action project naturally attracted the attention of many Genshin Impact players.
For example, some players suggested that the design can be more neutral and directly use the character name plus the skill name. After all, the audience cannot know the instructions such as "Tactics 3" at the first time, and "Zhongli, Using "Centre of the Earth" makes it easy to substitute into the game experience.

Some netizens said that since they can give instructions to monsters, can they also give voice commands to characters, such as "Turtle, use Frost Destruction".
guiguidailyquestion.jpg
However, why do these instructions seem so familiar? 

In response to this, the up owner "Schrödinger's Rainbow Cat" said that the speed of shouting skills may not be kept up, and the attack speed will be slower. This is why he A set is preset.

However, the output methods of some classic teams, such as "Wanda International" and "Lei Jiuwan Ban" are relatively fixed, and the preset attack sequence and mode seem to be It works.
Of course, in addition to making jokes, netizens are also brainstorming and putting forward many optimization suggestions.
For example, directly use "1Q" to let the character in position 1 magnify his moves, use "heavy" to express heavy attacks, and "dodge" to dodge. In this way, it will be easier and faster to issue instructions, and it may also be used to fight the abyss. .

Some expert players also said that this AI seems to "do not understand the environment very well", "the next step can be to consider adding SLAM", "to achieve 360-degree all-round target detection" ".

# The owner of up said that the next step is to "completely automatically refresh the base, teleport, defeat monsters, and receive rewards in one package". It seems that an automatic strengthening saint can also be added. The relic function will format the AI if it is crooked.

The hard-core live-up master of Genshin Impact also published the "Tivat Fishing Guide"
As Digest Fungus said, Genshin Impact has never There is a lack of work, and this up owner "Schrödinger's Rainbow Cat" should be the most "hardcore" among them.
From "AI automatically places the maze" to "AI automatically plays", every mini-game produced by Genshin Impact can be said to be based on AI.
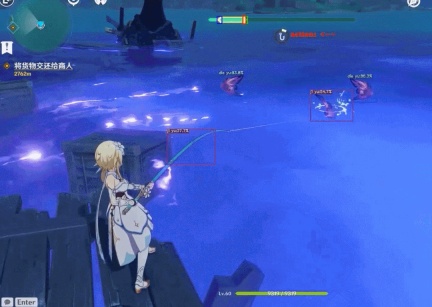
Among them, Wenzhijun also discovered the "AI automatic fishing" project (the good guy turns out to be you too). You only need to start the program, and all the fish in Teyvat can be bagged. thing.
Genshin Impact automatic fishing AI consists of two parts of the model: YOLOX and DQN:
YOLOX is used to locate and identify fish types and locate the landing point of the fishing rod;
DQN is used to adaptively control the click of the fishing process so that the intensity falls within the optimal area.
In addition, this project also uses transfer learning and semi-supervised learning for training. The model also contains some non-learnable parts that are implemented using traditional digital image processing methods such as opencv.
Project address:
https://github.com/7eu7d7/genshin_auto_fish
You still need to fish after the 3.0 update "Salted Fish Bow", I'll leave it to you! 
Those "artifacts" that turn Genshin Impact into Pokémon
As a serious person, Digest Fungus feels it is necessary to educate everyone about the use of Genshin Impact voice project Several "artifacts".
X-VLM is a multi-granularity model based on the visual language model (VLM). It consists of an image encoder, a text encoder and a cross-modal encoder. The cross-modal encoder combines visual features and language Cross-modal attention between features to learn visual language alignment.
The key to learning multi-granularity alignment is to optimize X-VLM: 1) by combining bounding box regression loss and IoU loss to locate visual concepts in images given associated text; 2) at the same time, by contrast loss, matching Loss and masked language modeling losses for multi-granular alignment of text with visual concepts.
In fine-tuning and inference, X-VLM can leverage the learned multi-granularity alignment to perform downstream V L tasks without adding bounding box annotations in the input image.

Paper link:
https://arxiv.org/abs/2111.08276
WeNet is an end-to-end production-oriented Speech recognition toolkit, which introduces a unified two-pass (U2) framework and built-in runtime to handle streaming and non-streaming decoding modes in a single model.
Just at the beginning of July this year, WeNet launched version 2.0 and was updated in 4 aspects:
U2: Unified dual-channel framework with bidirectional attention decoder, including from Future context information of the right-to-left attention decoder to improve the representation ability of the shared encoder and the performance of the rescoring stage;
Introduces an n-gram-based language model and a WFST-based decoder to facilitate Understand the use of rich text data in production scenarios;
Designed a unified context bias framework that utilizes user-specific context to provide rapid adaptability for production and improve ASR accuracy in both "with LM" and "without LM" scenarios;
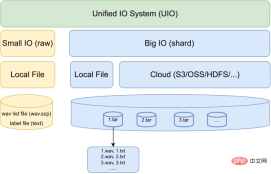
A unified IO is designed to support large-scale data for effective model training.
Judging from the results, WeNet 2.0 achieved a relative recognition performance improvement of up to 10% on various corpora compared with the original WeNet.
Paper link: https://arxiv.org/pdf/2203.15455.pdf
STARK is a spatio-temporal transformation network for visual tracking. Based on the baseline consisting of convolutional backbone, codec converter and bounding box prediction head, STARK has made 3 improvements:
Dynamic update template: use intermediate frames as dynamic templates to add to the input. Dynamic templates can capture appearance changes and provide additional time domain information;
score head: determine whether the dynamic template is currently updated;
Training strategy improvement: Divide training into two stages 1) In addition to score In addition to the head, use the baseline loss function to train. Ensure that all search images contain the target and allow the template to have positioning capabilities; 2) Use cross entropy to only optimize the score head and freeze other parameters at this time to allow the model to have positioning and classification capabilities.
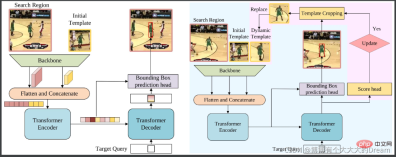
Paper link:
https://openaccess.thecvf.com/content/ICCV2021/papers/Yan_Learning_Spatio-Temporal_Transformer_for_Visual_Tracking_ICCV_2021_paper.pdf
The above is the detailed content of You can play Genshin Impact just by moving your mouth! Use AI to switch characters and attack enemies. Netizen: 'Ayaka, use Kamiri-ryu Frost Destruction'. For more information, please follow other related articles on the PHP Chinese website!

 从VAE到扩散模型:一文解读以文生图新范式Apr 08, 2023 pm 08:41 PM
从VAE到扩散模型:一文解读以文生图新范式Apr 08, 2023 pm 08:41 PM1 前言在发布DALL·E的15个月后,OpenAI在今年春天带了续作DALL·E 2,以其更加惊艳的效果和丰富的可玩性迅速占领了各大AI社区的头条。近年来,随着生成对抗网络(GAN)、变分自编码器(VAE)、扩散模型(Diffusion models)的出现,深度学习已向世人展现其强大的图像生成能力;加上GPT-3、BERT等NLP模型的成功,人类正逐步打破文本和图像的信息界限。在DALL·E 2中,只需输入简单的文本(prompt),它就可以生成多张1024*1024的高清图像。这些图像甚至
 找不到中文语音预训练模型?中文版 Wav2vec 2.0和HuBERT来了Apr 08, 2023 pm 06:21 PM
找不到中文语音预训练模型?中文版 Wav2vec 2.0和HuBERT来了Apr 08, 2023 pm 06:21 PMWav2vec 2.0 [1],HuBERT [2] 和 WavLM [3] 等语音预训练模型,通过在多达上万小时的无标注语音数据(如 Libri-light )上的自监督学习,显著提升了自动语音识别(Automatic Speech Recognition, ASR),语音合成(Text-to-speech, TTS)和语音转换(Voice Conversation,VC)等语音下游任务的性能。然而这些模型都没有公开的中文版本,不便于应用在中文语音研究场景。 WenetSpeech [4] 是
 普林斯顿陈丹琦:如何让「大模型」变小Apr 08, 2023 pm 04:01 PM
普林斯顿陈丹琦:如何让「大模型」变小Apr 08, 2023 pm 04:01 PM“Making large models smaller”这是很多语言模型研究人员的学术追求,针对大模型昂贵的环境和训练成本,陈丹琦在智源大会青源学术年会上做了题为“Making large models smaller”的特邀报告。报告中重点提及了基于记忆增强的TRIME算法和基于粗细粒度联合剪枝和逐层蒸馏的CofiPruning算法。前者能够在不改变模型结构的基础上兼顾语言模型困惑度和检索速度方面的优势;而后者可以在保证下游任务准确度的同时实现更快的处理速度,具有更小的模型结构。陈丹琦 普
 解锁CNN和Transformer正确结合方法,字节跳动提出有效的下一代视觉TransformerApr 09, 2023 pm 02:01 PM
解锁CNN和Transformer正确结合方法,字节跳动提出有效的下一代视觉TransformerApr 09, 2023 pm 02:01 PM由于复杂的注意力机制和模型设计,大多数现有的视觉 Transformer(ViT)在现实的工业部署场景中不能像卷积神经网络(CNN)那样高效地执行。这就带来了一个问题:视觉神经网络能否像 CNN 一样快速推断并像 ViT 一样强大?近期一些工作试图设计 CNN-Transformer 混合架构来解决这个问题,但这些工作的整体性能远不能令人满意。基于此,来自字节跳动的研究者提出了一种能在现实工业场景中有效部署的下一代视觉 Transformer——Next-ViT。从延迟 / 准确性权衡的角度看,
 Stable Diffusion XL 现已推出—有什么新功能,你知道吗?Apr 07, 2023 pm 11:21 PM
Stable Diffusion XL 现已推出—有什么新功能,你知道吗?Apr 07, 2023 pm 11:21 PM3月27号,Stability AI的创始人兼首席执行官Emad Mostaque在一条推文中宣布,Stable Diffusion XL 现已可用于公开测试。以下是一些事项:“XL”不是这个新的AI模型的官方名称。一旦发布稳定性AI公司的官方公告,名称将会更改。与先前版本相比,图像质量有所提高与先前版本相比,图像生成速度大大加快。示例图像让我们看看新旧AI模型在结果上的差异。Prompt: Luxury sports car with aerodynamic curves, shot in a
 五年后AI所需算力超100万倍!十二家机构联合发表88页长文:「智能计算」是解药Apr 09, 2023 pm 07:01 PM
五年后AI所需算力超100万倍!十二家机构联合发表88页长文:「智能计算」是解药Apr 09, 2023 pm 07:01 PM人工智能就是一个「拼财力」的行业,如果没有高性能计算设备,别说开发基础模型,就连微调模型都做不到。但如果只靠拼硬件,单靠当前计算性能的发展速度,迟早有一天无法满足日益膨胀的需求,所以还需要配套的软件来协调统筹计算能力,这时候就需要用到「智能计算」技术。最近,来自之江实验室、中国工程院、国防科技大学、浙江大学等多达十二个国内外研究机构共同发表了一篇论文,首次对智能计算领域进行了全面的调研,涵盖了理论基础、智能与计算的技术融合、重要应用、挑战和未来前景。论文链接:https://spj.scien
 什么是Transformer机器学习模型?Apr 08, 2023 pm 06:31 PM
什么是Transformer机器学习模型?Apr 08, 2023 pm 06:31 PM译者 | 李睿审校 | 孙淑娟近年来, Transformer 机器学习模型已经成为深度学习和深度神经网络技术进步的主要亮点之一。它主要用于自然语言处理中的高级应用。谷歌正在使用它来增强其搜索引擎结果。OpenAI 使用 Transformer 创建了著名的 GPT-2和 GPT-3模型。自从2017年首次亮相以来,Transformer 架构不断发展并扩展到多种不同的变体,从语言任务扩展到其他领域。它们已被用于时间序列预测。它们是 DeepMind 的蛋白质结构预测模型 AlphaFold
 AI模型告诉你,为啥巴西最可能在今年夺冠!曾精准预测前两届冠军Apr 09, 2023 pm 01:51 PM
AI模型告诉你,为啥巴西最可能在今年夺冠!曾精准预测前两届冠军Apr 09, 2023 pm 01:51 PM说起2010年南非世界杯的最大网红,一定非「章鱼保罗」莫属!这只位于德国海洋生物中心的神奇章鱼,不仅成功预测了德国队全部七场比赛的结果,还顺利地选出了最终的总冠军西班牙队。不幸的是,保罗已经永远地离开了我们,但它的「遗产」却在人们预测足球比赛结果的尝试中持续存在。在艾伦图灵研究所(The Alan Turing Institute),随着2022年卡塔尔世界杯的持续进行,三位研究员Nick Barlow、Jack Roberts和Ryan Chan决定用一种AI算法预测今年的冠军归属。预测模型图


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SublimeText3 Linux new version
SublimeText3 Linux latest version

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

SublimeText3 Chinese version
Chinese version, very easy to use

Notepad++7.3.1
Easy-to-use and free code editor

Dreamweaver Mac version
Visual web development tools

