
Home >Backend Development >Python Tutorial >How Python Vaex can quickly analyze 100G large data volume
How Python Vaex can quickly analyze 100G large data volume

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-05-13 08:34:051320browse
Limitations of pandas in processing big data
Nowadays, the amount of data provided by data science competitions is getting larger and larger, ranging from dozens of gigabytes to hundreds of gigabytes. This will test machine performance and data processing capabilities. .
Pandas in Python is a commonly used data processing tool. It can handle larger data sets (tens of millions of rows). However, when the data volume reaches billions of billions of rows, pandas is a bit unable to handle it. , it can be said to be very slow.
There will be performance factors such as computer memory, but pandas's own data processing mechanism (relying on memory) also limits its ability to process big data.
Of course pandas can read data in batches through chunks, but the disadvantage is that data processing is more complex, and each step of analysis consumes memory and time.
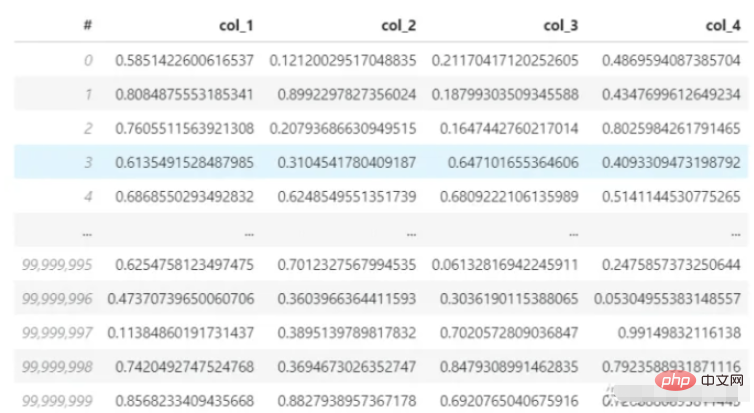
Next, use pandas to read a 3.7G data set (hdf5 format). The data set has 4 columns and 100 million rows, and calculate the average of the first row. My computer's CPU is i7-8550U and the memory is 8G. Let's see how long this loading and calculation process takes.
Dataset:
Read and calculate using pandas:
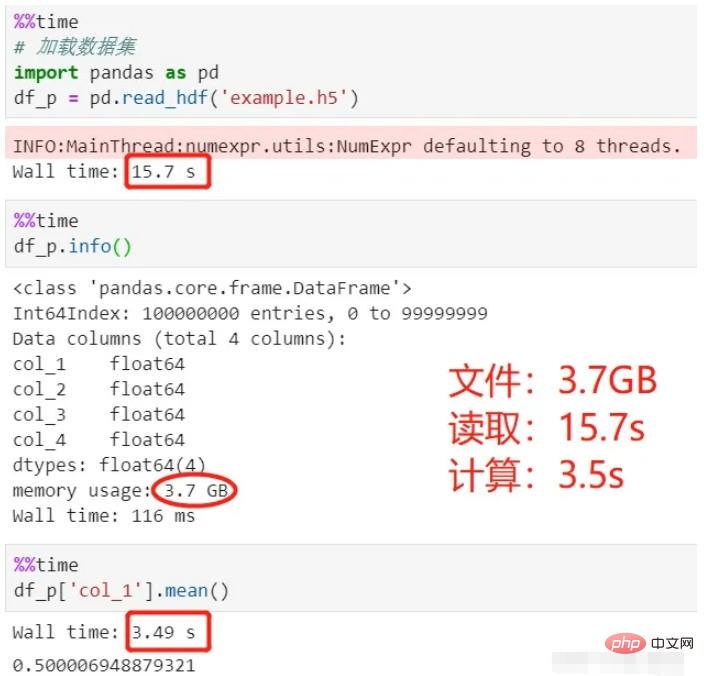
Look at the above process , it took 15 seconds to load the data, and 3.5 seconds to calculate the average, for a total of 18.5 seconds.
The hdf5 file used here is a file storage format. Compared with csv, it is more suitable for storing large amounts of data, has a high degree of compression, and is faster to read and write.
Change to today's protagonist vaex, read the same data, and do the same average calculation. How much time will it take?
Use vaex to read and calculate:
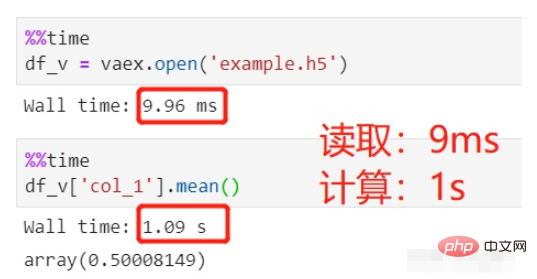
#The file reading took 9ms, which is negligible, and the average calculation took 1s, a total of 1s.
The same HDFS data set with 100 million rows is read. Why does pandas take more than ten seconds, while vaex takes close to 0?
This is mainly because pandas reads the data into memory and then uses it for processing and calculation. Vaex will only memory map the data instead of actually reading the data into the memory. This is the same as spark's lazy loading. It will be loaded when it is used and not when it is declared.
So no matter how big the data is loaded, 10GB, 100GB... it can be done instantly for vaex. The fly in the ointment is that vaex's lazy loading only supports HDF5, Apache Arrow, Parquet, FITS and other files, but does not support text files such as csv, because text files cannot be memory mapped.
Some friends may not understand memory mapping well. Here is an explanation. To find out the details, you have to explore by yourself:
Memory mapping refers to the location of files on the hard disk and the logical address of the process. A one-to-one correspondence between regions of the same size in space. This correspondence is purely a logical concept and does not exist physically. The reason is that the logical address space of the process itself does not exist. In the process of memory mapping, there is no actual data copy. The file is not loaded into the memory, but is logically put into the memory. Specifically, when it comes to the code, the relevant data structure (struct address_space) is established and initialized.
What is vaex
We compared the speed of processing big data between vaex and pandas earlier, and vaex has obvious advantages. Although his abilities are outstanding and he is not as well-known as pandas, vaex is still a newcomer who has just emerged from the industry.
vaex is also a third-party library for data processing based on python, which can be installed using pip.
The introduction of vaex on the official website can be summarized in three points:
vaex is a data table tool for processing and displaying data, similar to pandas;
vaex adopts memory mapping and lazy calculation, does not occupy memory, and is suitable for processing big data;
vaex can perform second-level statistics on tens of billions of data sets Analysis and visual display;
The advantages of vaex are:
Performance: processing massive data, 109 rows/second;
Lazy: fast calculation, does not occupy memory;
Zero memory copy: when filtering/transforming/calculating, do not copy memory, stream when needed transmission;
Visualization: Contains visual components;
API: similar to pandas, with rich data processing and calculation functions;
Interactive: used with Jupyter notebook, flexible interactive visualization;
Install vaex
Use pip or conda to install:

Reading data
vaex supports reading hdf5, csv, parquet and other files, using the read method. hdf5 can be read lazily, while csv can only be read into memory.
vaex data reading function:
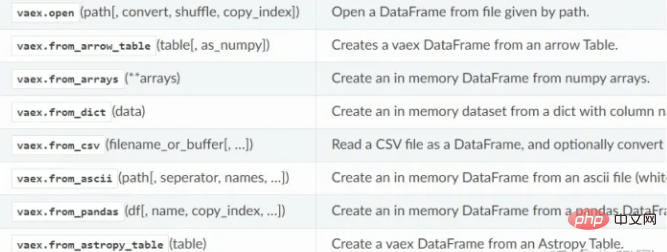
Data processing
Sometimes we need to perform various conversions, screening, calculations, etc. on the data. Each step of pandas processing consumes memory and takes time. high cost. Unless you use chain processing, the process is very unclear.
vaex has zero memory throughout the process. Because its processing only generates expression, which is a logical representation and will not be executed. It will only be executed in the final result generation stage. Moreover, the data in the entire process is streamed, and there will be no memory backlog.
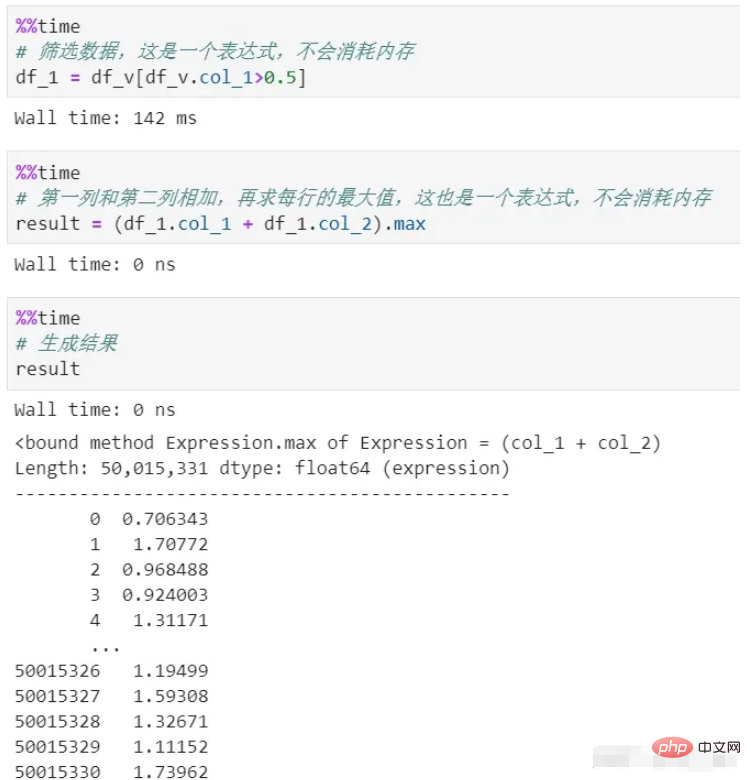
You can see that there are two processes of filtering and calculation above, neither of which copies the memory. Delayed calculation is used here, which is a lazy mechanism. If each process is actually calculated, not to mention the memory consumption, the time cost alone will be huge.
vaex’s statistical calculation function:
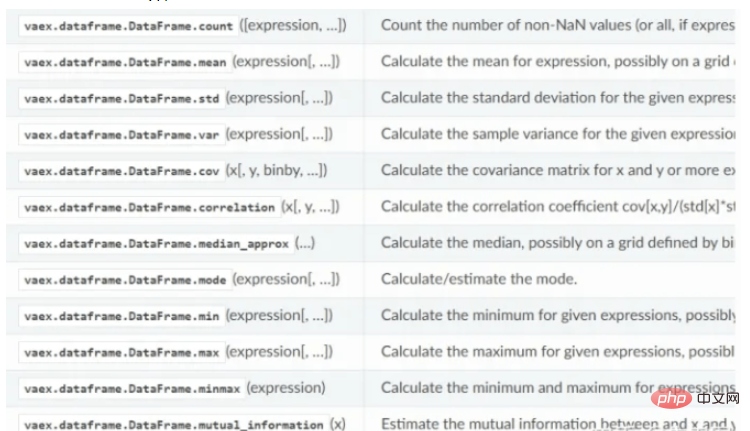
Visual display
vaex can also perform rapid visual display, even for tens of billions of data Collect and still be able to produce pictures in seconds.
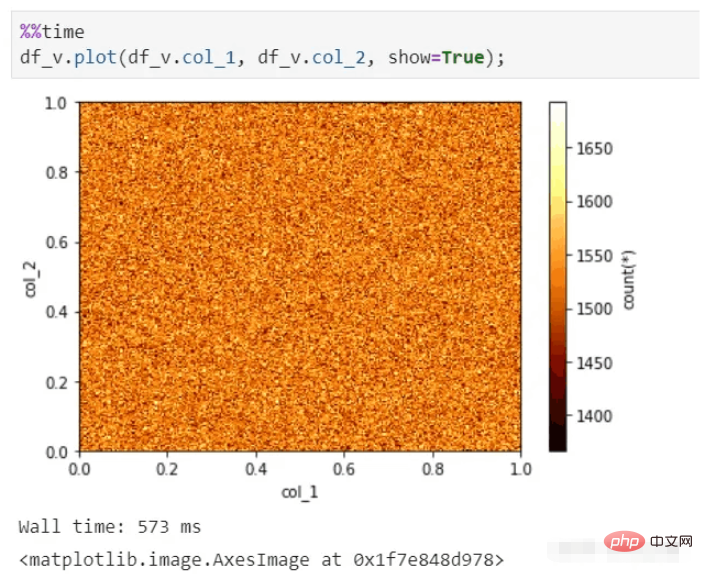
vaex visualization function:

Conclusion
vaex is somewhat similar to a combination of spark and pandas , the larger the amount of data, the more its advantages can be reflected. As long as your hard drive can hold as much data as it needs, it can quickly analyze the data.
vaex is still developing rapidly, integrating more and more pandas functions. Its star number on github is 5k, and its growth potential is huge.
Attachment: hdf5 data set generation code (4 columns and 100 million rows of data)
import pandas as pd import vaex df = pd.DataFrame(np.random.rand(100000000,4),columns=['col_1','col_2','col_3','col_4']) df.to_csv('example.csv',index=False) vaex.read('example.csv',convert='example1.hdf5')
Note that do not use pandas to directly generate hdf5, as its format will be incompatible with vaex.
The above is the detailed content of How Python Vaex can quickly analyze 100G large data volume. For more information, please follow other related articles on the PHP Chinese website!