

 Technology peripheralsAIControlling a double-jointed robotic arm using Actor-Critic's DDPG reinforcement learning algorithm
Technology peripheralsAIControlling a double-jointed robotic arm using Actor-Critic's DDPG reinforcement learning algorithmControlling a double-jointed robotic arm using Actor-Critic's DDPG reinforcement learning algorithm

In this article, we will introduce training an intelligent agent to control a dual-jointed robotic arm in the Reacher environment, a Unity-based simulation program developed using the Unity ML-Agents toolkit. Our goal is to reach the target position with high accuracy, so here we can use the state-of-the-art Deep Deterministic Policy Gradient (DDPG) algorithm designed for continuous state and action spaces.

Real World Applications
Robotic arms play a critical role in manufacturing, production facilities, space exploration and search and rescue operations. It is very important to control the robot arm with high precision and flexibility. By employing reinforcement learning techniques, these robotic systems can be enabled to learn and adjust their behavior in real time, thereby improving performance and flexibility. Advances in reinforcement learning not only contribute to our understanding of artificial intelligence, but have the potential to revolutionize industries and have a meaningful impact on society.
Reacher is a robotic arm simulator that is often used for the development and testing of control algorithms. It provides a virtual environment that simulates the physical characteristics and motion laws of the robotic arm, allowing developers to conduct research and experiments on control algorithms without the need for actual hardware.
Reacher's environment mainly consists of the following parts:
- Robotic arm: Reacher simulates a double-jointed robotic arm, including a fixed base and two movable joints. Developers can change the attitude and position of the robotic arm by controlling its two joints.
- Target point: Within the movement range of the robotic arm, Reacher provides a target point, and the position of the target point is randomly generated. The developer's task is to control the robotic arm so that the end of the robotic arm can contact the target point.
- Physics engine: Reacher uses a physics engine to simulate the physical characteristics and movement patterns of the robotic arm. Developers can simulate different physical environments by adjusting the parameters of the physics engine.
- Visual interface: Reacher provides a visual interface that can display the positions of the robotic arm and target points, as well as the posture and movement trajectory of the robotic arm. Developers can debug and optimize control algorithms through a visual interface.
Reacher simulator is a very practical tool that can help developers quickly test and optimize control algorithms without the need for actual hardware.
Simulation Environment
Reacher is built using the Unity ML-Agents toolkit, our agent can control a dual-jointed robotic arm. The goal is to guide the arm toward the target position and maintain its position within the target area for as long as possible. The environment features 20 synchronized agents, each running independently, which helps to efficiently collect experience during training.

State and Action Space
Understanding state and action space is crucial to designing effective reinforcement learning algorithms. In the Reacher environment, the state space consists of 33 continuous variables that provide information about the robotic arm, such as its position, rotation, velocity, and angular velocity. The action space is also continuous, with four variables corresponding to the torques exerted on the two joints of the robotic arm. Each action variable is a real number between -1 and 1.
Task Types and Success Criteria
Reacher tasks are considered to be fragmented, with each fragment containing a fixed number of time steps. The agent's goal is to maximize its total reward during these steps. The arm end effector receives a 0.1 bonus for each step it takes to maintain the target position. Success is considered when an agent achieves an average score of 30 points or above over 100 consecutive operations.
Now that we understand the environment, let's explore the DDPG algorithm, its implementation, and how it effectively solves continuous control problems in this environment.
Algorithm Selection for Continuous Control: DDPG
When it comes to continuous control tasks like the Reacher problem, algorithm selection is critical to achieving optimal performance. In this project, we chose the DDPG algorithm because it is an actor-critic method specifically designed to handle continuous state and action spaces.
The DDPG algorithm combines the advantages of policy-based and value-based methods by combining two neural networks: the actor network determines the best behavior given the current state, and the critic network network) estimates the state-behavior value function (Q-function). Both types of networks have target networks that stabilize the learning process by providing a fixed target during the update process.
By using the Critic network to estimate the q function and the Actor network to determine the optimal behavior, the DDPG algorithm effectively combines the advantages of the policy gradient method and DQN. This hybrid approach allows agents to learn efficiently in a continuous control environment.
<code>import random from collections import deque import torch import torch.nn as nn import numpy as np from actor_critic import Actor, Critic class ReplayBuffer: def __init__(self, buffer_size, batch_size): self.memory = deque(maxlen=buffer_size) self.batch_size = batch_size def add(self, state, action, reward, next_state, done): self.memory.append((state, action, reward, next_state, done)) def sample(self): batch = random.sample(self.memory, self.batch_size) states, actions, rewards, next_states, dones = zip(*batch) return states, actions, rewards, next_states, dones def __len__(self): return len(self.memory) class DDPG: def __init__(self, state_dim, action_dim, hidden_dim, buffer_size, batch_size, actor_lr, critic_lr, tau, gamma): self.actor = Actor(state_dim, hidden_dim, action_dim, actor_lr) self.actor_target = Actor(state_dim, hidden_dim, action_dim, actor_lr) self.critic = Critic(state_dim, action_dim, hidden_dim, critic_lr) self.critic_target = Critic(state_dim, action_dim, hidden_dim, critic_lr) self.memory = ReplayBuffer(buffer_size, batch_size) self.batch_size = batch_size self.tau = tau self.gamma = gamma self._update_target_networks(tau=1)# initialize target networks def act(self, state, noise=0.0): state = torch.tensor(state, dtype=torch.float32).unsqueeze(0) action = self.actor(state).detach().numpy()[0] return np.clip(action + noise, -1, 1) def store_transition(self, state, action, reward, next_state, done): self.memory.add(state, action, reward, next_state, done) def learn(self): if len(self.memory) </code>
The above code also uses Replay Buffer, which can improve learning efficiency and stability. Replay Buffer is essentially a memory data structure that stores a fixed number of past experiences or transitions, consisting of status, action, reward, next status and completion information. The main advantage of using it is to enable the agent to break correlations between consecutive experiences, thereby reducing the impact of harmful temporal correlations.
By drawing random mini-batches of experience from the buffer, the agent can learn from a diverse set of transformations, which helps stabilize and generalize the learning process. Replay Buffers also allow agents to reuse past experiences multiple times, thereby increasing data efficiency and promoting more effective learning from limited interactions with the environment.
The DDPG algorithm is a good choice because of its ability to efficiently handle continuous action spaces, which is a key aspect in this environment. The design of the algorithm allows efficient utilization of parallel experience gathered by multiple agents, resulting in faster learning and better convergence. Just like the Reacher introduced above, it can run 20 agents at the same time, so we can use these 20 agents to share experience, learn collectively, and increase the learning speed.
After completing the algorithm, we will introduce the hyperparameter selection and training process below.
DDPG algorithm works in the Reacher environment
To better understand the effectiveness of the algorithm in the environment, we need to take a closer look at the key components and steps involved in the learning process.
Network Architecture
The DDPG algorithm uses two neural networks, Actor and Critic. Both networks contain two hidden layers, each containing 400 nodes. The hidden layer uses the ReLU (Rectified Linear Unit) activation function, while the output layer of the Actor network uses the tanh activation function to generate actions ranging from -1 to 1. The output layer of the critic network has no activation function because it directly estimates the q function.
The following is the code of the network:
<code>import numpy as np import torch import torch.nn as nn import torch.optim as optim class Actor(nn.Module): def __init__(self, input_dim, hidden_dim, output_dim, learning_rate=1e-4): super(Actor, self).__init__() self.fc1 = nn.Linear(input_dim, hidden_dim) self.fc2 = nn.Linear(hidden_dim, hidden_dim) self.fc3 = nn.Linear(hidden_dim, output_dim) self.tanh = nn.Tanh() self.optimizer = optim.Adam(self.parameters(), lr=learning_rate) def forward(self, state): x = torch.relu(self.fc1(state)) x = torch.relu(self.fc2(x)) x = self.tanh(self.fc3(x)) return x class Critic(nn.Module): def __init__(self, state_dim, action_dim, hidden_dim, learning_rate=1e-4): super(Critic, self).__init__() self.fc1 = nn.Linear(state_dim, hidden_dim) self.fc2 = nn.Linear(hidden_dim + action_dim, hidden_dim) self.fc3 = nn.Linear(hidden_dim, 1) self.optimizer = optim.Adam(self.parameters(), lr=learning_rate) def forward(self, state, action): x = torch.relu(self.fc1(state)) x = torch.relu(self.fc2(torch.cat([x, action], dim=1))) x = self.fc3(x) return x</code>
Hyperparameter selection
The selected hyperparameters are crucial for efficient learning. In this project, our Replay Buffer size is 200,000 and the batch size is 256. The learning rate of Actor is 5e-4, the learning rate of Critic is 1e-3, the soft update parameter (tau) is 5e-3, and gamma is 0.995. Finally, action noise was added, with an initial noise scale of 0.5 and a noise attenuation rate of 0.998.
Training process
The training process involves continuous interaction between the two networks, and with 20 parallel agents sharing the same network, the model learns collectively from the experience collected by all agents. This setup speeds up the learning process and increases efficiency.
<code>from collections import deque import numpy as np import torch from ddpg import DDPG def train_ddpg(env, agent, episodes, max_steps, num_agents, noise_scale=0.1, noise_decay=0.99): scores_window = deque(maxlen=100) scores = [] for episode in range(1, episodes + 1): env_info = env.reset(train_mode=True)[brain_name] states = env_info.vector_observations agent_scores = np.zeros(num_agents) for step in range(max_steps): actions = agent.act(states, noise_scale) env_info = env.step(actions)[brain_name] next_states = env_info.vector_observations rewards = env_info.rewards dones = env_info.local_done for i in range(num_agents): agent.store_transition(states[i], actions[i], rewards[i], next_states[i], dones[i]) agent.learn() states = next_states agent_scores += rewards noise_scale *= noise_decay if np.any(dones): break avg_score = np.mean(agent_scores) scores_window.append(avg_score) scores.append(avg_score) if episode % 10 == 0: print(f"Episode: {episode}, Score: {avg_score:.2f}, Avg Score: {np.mean(scores_window):.2f}") # Saving trained Networks torch.save(agent.actor.state_dict(), "actor_final.pth") torch.save(agent.critic.state_dict(), "critic_final.pth") return scores if __name__ == "__main__": env = UnityEnvironment(file_name='Reacher_20.app') brain_name = env.brain_names[0] brain = env.brains[brain_name] state_dim = 33 action_dim = brain.vector_action_space_size num_agents = 20 # Hyperparameter suggestions hidden_dim = 400 batch_size = 256 actor_lr = 5e-4 critic_lr = 1e-3 tau = 5e-3 gamma = 0.995 noise_scale = 0.5 noise_decay = 0.998 agent = DDPG(state_dim, action_dim, hidden_dim=hidden_dim, buffer_size=200000, batch_size=batch_size,actor_lr=actor_lr, critic_lr=critic_lr, tau=tau, gamma=gamma) episodes = 200 max_steps = 1000 scores = train_ddpg(env, agent, episodes, max_steps, num_agents, noise_scale=0.2, noise_decay=0.995)</code>
The key steps in the training process are as follows:
Initialize the network: The agent initializes the shared Actor and Critic networks and their respective target networks with random weights. The target network provides stable learning targets during updates.
- Interacting with the environment: Each agent uses a shared Actor network to interact with the environment by selecting actions based on its current state. To encourage exploration, a noise term is also added to the actions in the initial stages of training. After taking an action, each agent observes the resulting reward and next state.
- Storing experience: Each agent stores the observed experience (state, action, reward, next_state) in the shared replay buffer. This buffer contains a fixed amount of recent experience so that each agent can learn from various transitions collected by all agents.
- Learn from experience: Periodically extract a batch of experiences from the shared replay buffer. Use sampling experience to update the shared critic network by minimizing the mean square error between the predicted Q-value and the target Q-value.
- Update Actor Network: The shared Actor network is updated using the policy gradient, which is calculated by taking the output gradient of the shared Critic network with respect to the selected action. The shared actor network learns to choose actions that maximize the expected Q-value.
- Update target network: The shared Actor and Critic target networks are soft updated using a mixture of current and target network weights. This ensures a stable learning process.
Result Display
Our agent successfully learned to control a double-jointed robotic arm in the Racher environment using the DDPG algorithm. Throughout the training process, we monitor the agent's performance based on the average score of all 20 agents. As the agent explores the environment and gathers experience, its ability to predict optimal behavior for reward maximization improves significantly.

It can be seen that the agent showed significant proficiency in the task, with the average score exceeding the threshold required to solve the environment (30), although the agent's performance varied throughout There are differences during the training process, but the overall trend is upward, indicating that the learning process is successful.
The graph below shows the average score of 20 agents:
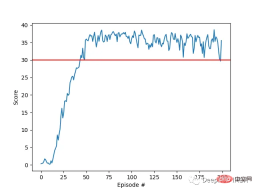
#You can see that the DDPG algorithm we implemented effectively solved the problem of the Racher environment. Agents are able to adjust their behavior and achieve expected performance in tasks.
Next steps
The hyperparameters in this project were selected based on a combination of recommendations from the literature and empirical testing. Further optimization through system hyperparameter tuning may lead to better performance.
Multi-agent parallel training: In this project, we use 20 agents to collect experience at the same time. The impact of using more agents on the overall learning process may result in faster convergence or improved performance.
Batch normalization: To further enhance the learning process, implementing batch normalization in neural network architectures is worth exploring. By normalizing the input features of each layer during training, batch normalization can help reduce internal covariate shifts, speed up learning, and potentially improve generalization. Adding batch normalization to the Actor and Critic networks may lead to more stable and efficient training, but this requires further testing.
The above is the detailed content of Controlling a double-jointed robotic arm using Actor-Critic's DDPG reinforcement learning algorithm. For more information, please follow other related articles on the PHP Chinese website!

 How to Run LLM Locally Using LM Studio? - Analytics VidhyaApr 19, 2025 am 11:38 AM
How to Run LLM Locally Using LM Studio? - Analytics VidhyaApr 19, 2025 am 11:38 AMRunning large language models at home with ease: LM Studio User Guide In recent years, advances in software and hardware have made it possible to run large language models (LLMs) on personal computers. LM Studio is an excellent tool to make this process easy and convenient. This article will dive into how to run LLM locally using LM Studio, covering key steps, potential challenges, and the benefits of having LLM locally. Whether you are a tech enthusiast or are curious about the latest AI technologies, this guide will provide valuable insights and practical tips. Let's get started! Overview Understand the basic requirements for running LLM locally. Set up LM Studi on your computer
 Guy Peri Helps Flavor McCormick's Future Through Data TransformationApr 19, 2025 am 11:35 AM
Guy Peri Helps Flavor McCormick's Future Through Data TransformationApr 19, 2025 am 11:35 AMGuy Peri is McCormick’s Chief Information and Digital Officer. Though only seven months into his role, Peri is rapidly advancing a comprehensive transformation of the company’s digital capabilities. His career-long focus on data and analytics informs
 What is the Chain of Emotion in Prompt Engineering? - Analytics VidhyaApr 19, 2025 am 11:33 AM
What is the Chain of Emotion in Prompt Engineering? - Analytics VidhyaApr 19, 2025 am 11:33 AMIntroduction Artificial intelligence (AI) is evolving to understand not just words, but also emotions, responding with a human touch. This sophisticated interaction is crucial in the rapidly advancing field of AI and natural language processing. Th
 12 Best AI Tools for Data Science Workflow - Analytics VidhyaApr 19, 2025 am 11:31 AM
12 Best AI Tools for Data Science Workflow - Analytics VidhyaApr 19, 2025 am 11:31 AMIntroduction In today's data-centric world, leveraging advanced AI technologies is crucial for businesses seeking a competitive edge and enhanced efficiency. A range of powerful tools empowers data scientists, analysts, and developers to build, depl
 AV Byte: OpenAI's GPT-4o Mini and Other AI InnovationsApr 19, 2025 am 11:30 AM
AV Byte: OpenAI's GPT-4o Mini and Other AI InnovationsApr 19, 2025 am 11:30 AMThis week's AI landscape exploded with groundbreaking releases from industry giants like OpenAI, Mistral AI, NVIDIA, DeepSeek, and Hugging Face. These new models promise increased power, affordability, and accessibility, fueled by advancements in tr
 Perplexity's Android App Is Infested With Security Flaws, Report FindsApr 19, 2025 am 11:24 AM
Perplexity's Android App Is Infested With Security Flaws, Report FindsApr 19, 2025 am 11:24 AMBut the company’s Android app, which offers not only search capabilities but also acts as an AI assistant, is riddled with a host of security issues that could expose its users to data theft, account takeovers and impersonation attacks from malicious
 Everyone's Getting Better At Using AI: Thoughts On Vibe CodingApr 19, 2025 am 11:17 AM
Everyone's Getting Better At Using AI: Thoughts On Vibe CodingApr 19, 2025 am 11:17 AMYou can look at what’s happening in conferences and at trade shows. You can ask engineers what they’re doing, or consult with a CEO. Everywhere you look, things are changing at breakneck speed. Engineers, and Non-Engineers What’s the difference be
 Rocket Launch Simulation and Analysis using RocketPy - Analytics VidhyaApr 19, 2025 am 11:12 AM
Rocket Launch Simulation and Analysis using RocketPy - Analytics VidhyaApr 19, 2025 am 11:12 AMSimulate Rocket Launches with RocketPy: A Comprehensive Guide This article guides you through simulating high-power rocket launches using RocketPy, a powerful Python library. We'll cover everything from defining rocket components to analyzing simula


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

SublimeText3 Mac version
God-level code editing software (SublimeText3)

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

