
Home >Java >javaTutorial >How does java multi-threading assemble asynchronous computing units through CompletableFuture?
How does java multi-threading assemble asynchronous computing units through CompletableFuture?

- 王林forward
- 2023-05-11 19:04:041324browse
CompletableFuture Introduction
CompletableFuture is a new feature introduced in 1.8. It is used for some more complex asynchronous computing scenarios, especially those that require multiple asynchronous computing units to be connected in series. , you can consider using CompletableFuture to implement.
In the real world, the complex problems we need to solve are divided into several steps. Just like our code, in a complex logical method, multiple methods will be called to implement it step by step.
Imagine the following scenario. Tree planting is to be carried out on Arbor Day, which is divided into the following steps:
dig a hole for 10 minutes
Get saplings for 5 minutes
Plant saplings for 20 minutes
Water for 5 minutes
Among them 1 and 2 can be performed in parallel. Step 3 must be completed only after both 1 and 2 are completed, and then step 4 can be performed.
We have the following implementation methods:
Only one person plants trees
If there is only one person planting trees now and 100 trees are to be planted, then the following order can only be followed Execution:
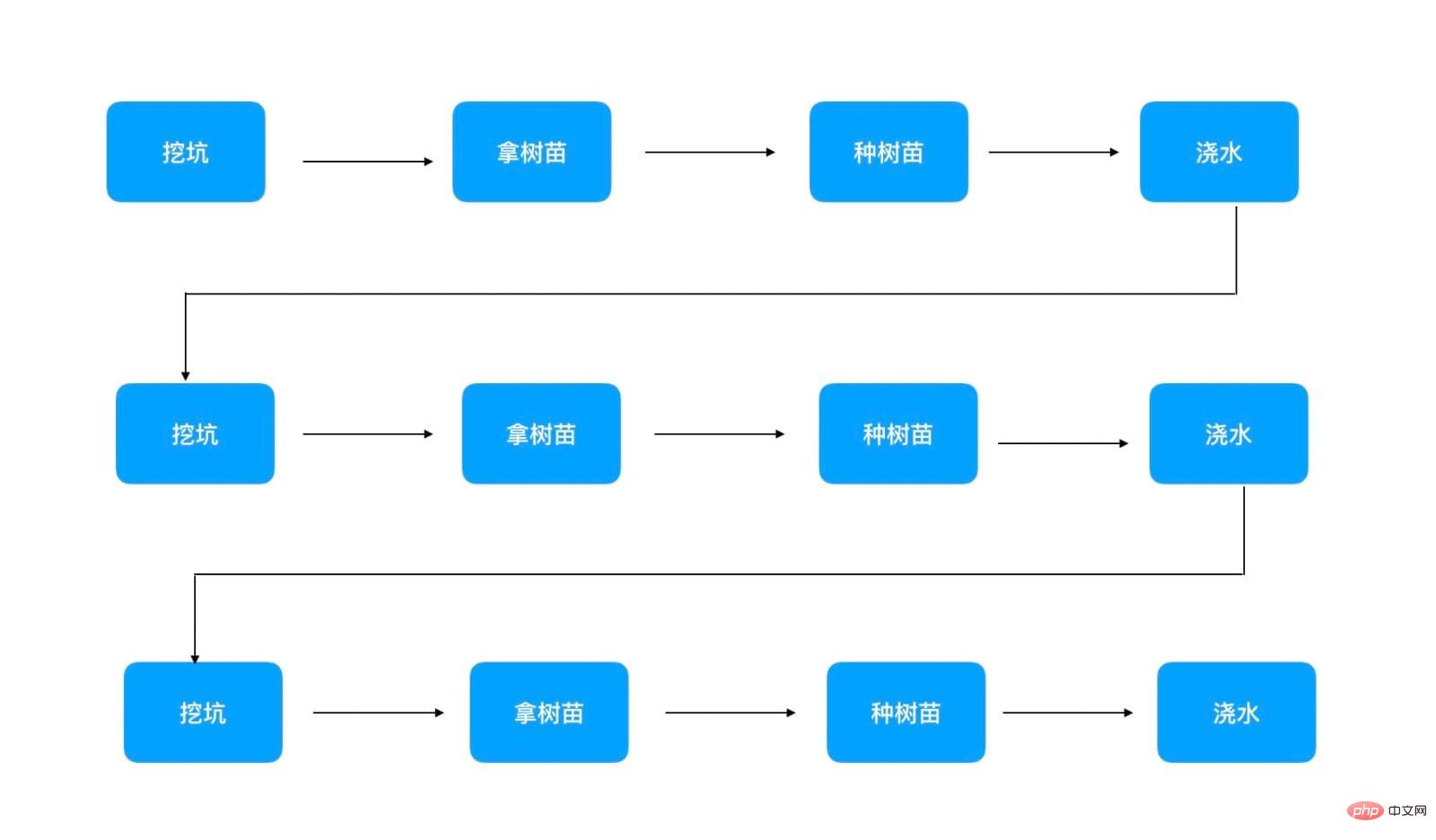
#Only three trees are shown in the picture. You can see that in serial execution, you can only plant one tree and then another, so it takes 40 * 100 = 4000 minutes to plant 100 trees. This method corresponds to the program, which is single-threaded synchronous execution.
Three people plant trees at the same time, each person is responsible for planting a tree
How to shorten the time of planting trees? You must be thinking that this is not easy to handle. After studying concurrency for so long, this is definitely not a problem for me. Don’t you want to plant 100 trees? Then I will find 100 people to plant together, and each person will plant a tree. Then it only takes 40 minutes to plant 100 trees.
Yes, if your program has a method called plantTree, which contains the above four parts, then you only need to create 100 threads. However, please note that the creation and destruction of 100 threads consumes a lot of system resources. And creating and destroying threads takes time. In addition, the number of cores of the CPU cannot really support 100 threads concurrently. What if we want to plant 10,000 trees? You can't have 10,000 threads, right?
So this is just an ideal situation. We usually execute it through the thread pool and will not actually start 100 threads.
Multiple people plant trees at the same time
When planting each tree, independent steps can be done by different people in parallel
This method can further shorten the time of tree planting Because the first step of digging the hole and the second step of getting the saplings can be done by two people in parallel, each tree only takes 35 minutes. As shown below:
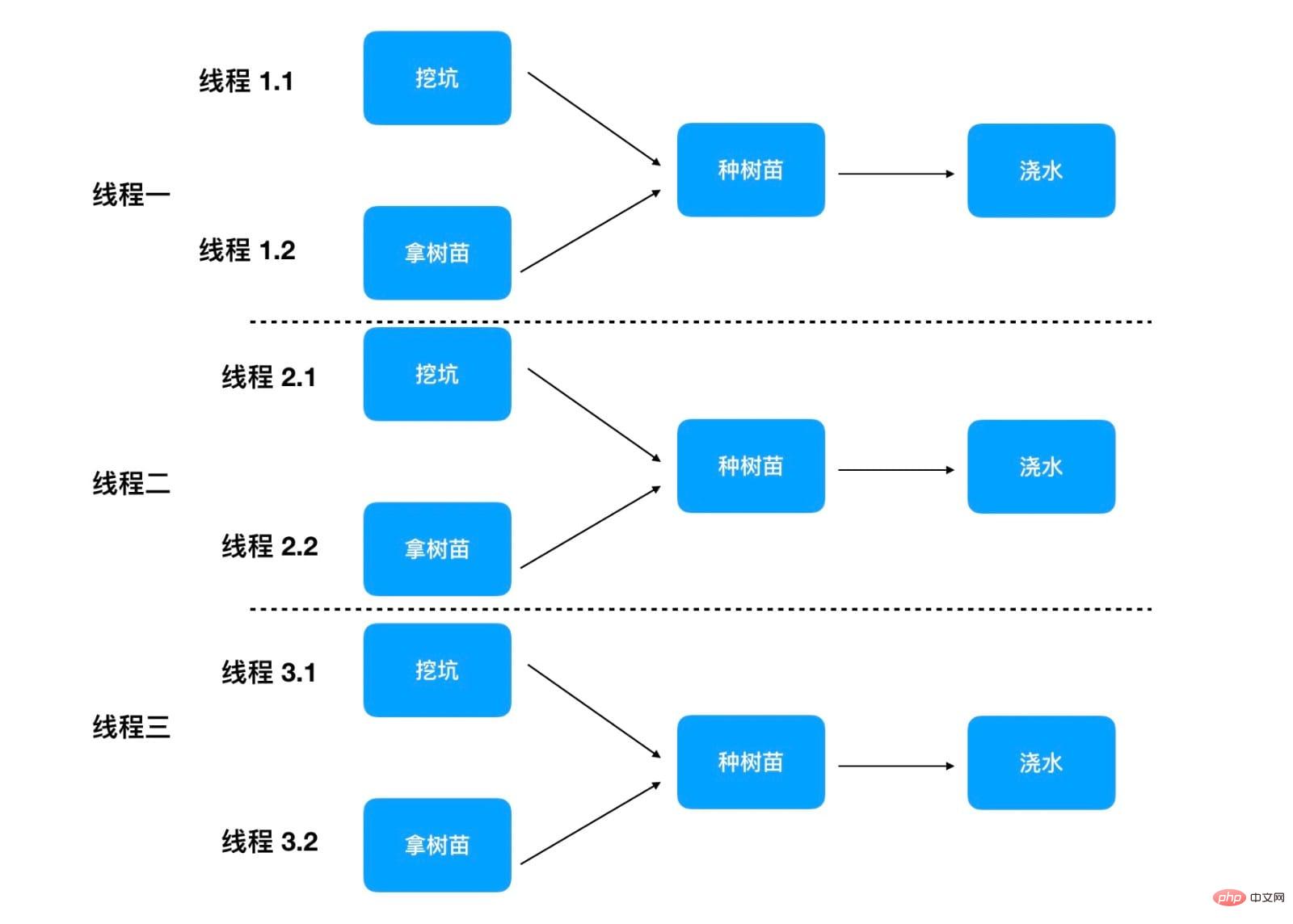
#If the program still has 100 main threads running the plantTree method concurrently, then it only takes 35 minutes to plant 100 trees. Here you need to pay attention to each thread, because there are two threads to do steps 1 and 2 concurrently. In actual operation, 100 x 3 = 300 threads will participate in tree planting. But the thread responsible for steps 1 and 2 will only participate briefly and then become idle.
This method and the second method also have the problem of creating a large number of threads. So it's just an ideal situation.
If there are only 4 people planting trees, each person is only responsible for his own steps
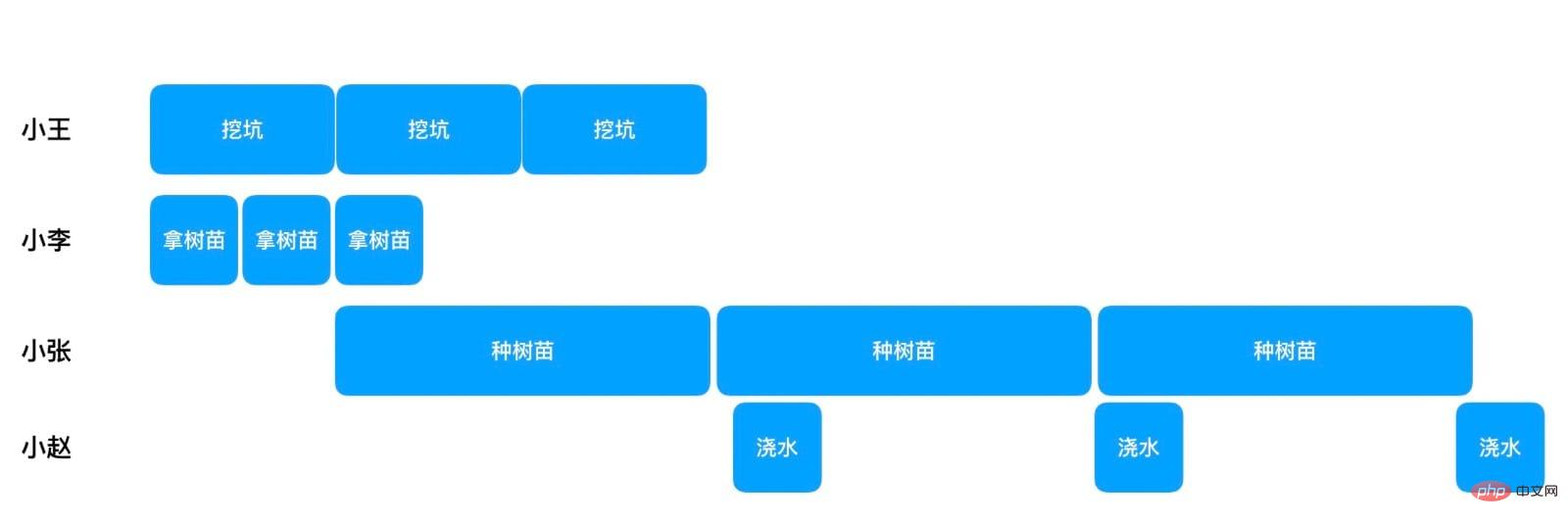
You can see that after Xiao Wang dug the first hole at the beginning, Xiao Wang Li has retrieved two saplings, but now Xiao Zhang can start planting the first sapling. From then on, Xiao Zhang can plant saplings one by one, and when he plants a sapling, Xiao Zhao can water it in parallel. Following this process, it will take 10 20x100 5=2015 minutes to plant 100 saplings. It is much better than the 4000 minutes of a single thread, but it is far less than the speed of 100 threads concurrently planting trees. But don’t forget that 100 threads concurrently is only an ideal situation, and this method only uses 4 threads.
Let’s make some adjustments to the division of labor. Everyone not only does their own work, but once their own work is done, they see if there is any other work that can be done. For example, after Xiao Wang dug a hole and found that he could plant saplings, he would plant saplings. After Xiao Li has finished taking the saplings, he can also dig holes or plant saplings. In this way, the overall efficiency will be higher. If based on this idea, then we actually divide the tasks into 4 categories, with 100 tasks in each category, for a total of 400 tasks. When all 400 tasks are completed, it means that the entire task is completed. Then the participants of the task only need to know the dependencies of the task, and then continuously receive executable tasks to execute. This efficiency will be the highest.
As mentioned earlier, it is impossible for us to execute tasks through 100 threads concurrently, so under normal circumstances we will use a thread pool, which coincides with the above design idea. After using the thread pool, the fourth method breaks down the steps into finer details, increasing the possibility of concurrency. Therefore the speed will be faster than the second method. So compared with the third type, which one is faster? If the number of threads can be infinite, the minimum time that these two methods can achieve is the same, 35 minutes. However, when threads are limited, the fourth method will have a higher utilization rate of threads, because each step can be executed in parallel (people involved in tree planting can help others after completing their work), thread The scheduling is more flexible, so the threads in the thread pool are difficult to idle and keep running. Yes, no one can be lazy. The third method can only be used concurrently in the plantTree method, digging holes and taking saplings, so it is not as flexible as the fourth method.
I have said so much above, mainly to explain the reasons for the emergence of CompletableFuture. It is used to break down complex tasks into connected asynchronous execution steps, thereby improving overall efficiency. Let’s go back to the topic of the section: No one can be lazy. Yes, this is what CompletableFuture aims to achieve. By abstracting the computing unit, threads can participate in each step efficiently and concurrently. Synchronous code can be completely transformed into asynchronous code through CompletableFuture. Let's take a look at how to use CompletableFuture.
CompletableFuture uses
CompletableFuture implements the Future interface and implements the CompletionStage interface. We are already familiar with the Future interface, and the CompletionStage interface sets the specifications between asynchronous calculation steps to ensure that they can be connected step by step. CompletionStage defines 38 public methods for connection between asynchronous calculation steps. Next, we will select some commonly used and relatively frequently used methods to see how to use them.
Known calculation result
If you already know the calculation result of CompletableFuture, you can use the static method completedFuture. Pass in the calculation result and declare the CompletableFuture object. When the get method is called, the incoming calculation result will be returned immediately without being blocked, as shown in the following code:
public static void main(String[] args) throws Exception{
CompletableFuture<String> completableFuture = CompletableFuture.completedFuture("Hello World");
System.out.println("result is " + completableFuture.get());
}
// result is Hello WorldDo you think this usage is meaningless? Now that you know the calculation result, you can just use it directly. Why do you need to package it with CompletableFuture? This is because asynchronous computing units need to be connected through CompletableFuture, so sometimes even if we already know the calculation results, we need to package them into CompletableFuture to integrate into the asynchronous computing process.
Encapsulating asynchronous calculation logic with return value
This is our most commonly used method. Encapsulate the logic that requires asynchronous calculation into a calculation unit and hand it over to CompletableFuture to run. As in the following code:
public static void main(String[] args) throws Exception {
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> "挖坑完成");
System.out.println("result is " + completableFuture.get());
}
// result is 挖坑完成Here we use the supplyAsync method of CompletableFuture and pass it an implementation of the supplier interface in the form of a lambda expression.
It can be seen that completableFuture.get() The calculation result obtained is the value returned after the function you pass in is executed. Then if you have logic that requires asynchronous calculation, you can put it in the function body passed in by supplyAsync. How is this function executed asynchronously? If you follow the code, you can see that supplyAsync actually runs this function through the Executor, which is the thread pool. completableFuture uses ForkJoinPool by default. Of course, you can also specify other Excutors for supplyAsync and pass it into the supplyAsync method through the second parameter.
supplyAsync is used in many scenarios. To give a simple example, the main program needs to call the interfaces of multiple microservices to request data. Then it can start multiple CompletableFutures and call supplyAsync. The function body is about different interfaces. Call logic. In this way, different interface requests can be run asynchronously and simultaneously, and finally when all interfaces return, the subsequent logic will be executed.
Encapsulate asynchronous calculation logic without return value
The function received by supplyAsync has a return value. In some cases, we are just a calculation process and do not need to return a value. This is like Runnable's run method, which does not return a value. In this case, we can use the runAsync method, such as the following code:
public static void main(String[] args) throws Exception {
CompletableFuture<Void> completableFuture = CompletableFuture.runAsync(() -> System.out.println("挖坑完成"));
completableFuture.get();
}
// 挖坑完成runAsync receives the function of the runnable interface. So there is no return value. The logic in Chestnut just prints "Digming completed".
Further process the asynchronously returned results and return new calculation results
When we complete the asynchronous calculation through supplyAsync and return CompletableFuture, we can continue to process the returned results at this time, as shown below Code:
public static void main(String[] args) throws Exception {
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> "挖坑完成")
.thenApply(s -> s + ", 并且归还铁锹")
.thenApply(s -> s + ", 全部完成。");
System.out.println("result is " + completableFuture.get());
}
// result is 挖坑完成, 并且归还铁锹, 全部完成。After calling supplyAsync, we chain call the thenApply method twice. s is the calculation result returned by supplyAsync in the previous step. We reprocessed the calculation result twice. We can continuously process the calculation results through thenApply. If you want to run thenApply's logic asynchronously, you can use thenApplyAsync. The usage method is the same, but it will run asynchronously through the thread pool.
进一步处理异步返回的结果,无返回
这种场景你可以使用thenApply。这个方法可以让你处理上一步的返回结果,但无返回值。参照如下代码:
public static void main(String[] args) throws Exception {
CompletableFuture<Void> completableFuture = CompletableFuture.supplyAsync(() -> "挖坑完成")
.thenAccept(s -> System.out.println(s + ", 并且归还铁锹"));
completableFuture.get();
}这里可以看到 thenAccept 接收的函数没有返回值,只有业务逻辑。处理后返回 CompletableFuture 类型对象。
既不需要返回值,也不需要上一步计算结果,只想在执行结束后再执行一段代码
此时你可以使用 thenRun 方法,他接收 Runnable 的函数,没有输入也没有输出,仅仅是在异步计算结束后回调一段逻辑,比如记录 log 等。参照下面代码:
public static void main(String[] args) throws Exception {
CompletableFuture<Void> completableFuture = CompletableFuture.supplyAsync(() -> "挖坑完成")
.thenAccept(s -> System.out.println(s + ", 并且归还铁锹"))
.thenRun(() -> System.out.println("挖坑工作已经全部完成"));
completableFuture.get();
}
// 挖坑完成, 并且归还铁锹
// 挖坑工作已经全部完成可以看到在 thenAccept 之后继续调用了 thenRun,仅仅是打印了日志而已
组合 Future 处理逻辑
我们可以把两个 CompletableFuture 组合起来使用,如下面的代码:
public static void main(String[] args) throws Exception {
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> "挖坑完成")
.thenCompose(s -> CompletableFuture.supplyAsync(() -> s + ", 并且归还铁锹"));
System.out.println("result is " + completableFuture.get());
}
// result is 挖坑完成, 并且归还铁锹thenApply 和 thenCompose 的关系就像 stream中的 map 和 flatmap。从上面的例子来看,thenApply 和thenCompose 都可以实现同样的功能。但是如果你使用一个第三方的库,有一个API返回的是CompletableFuture 类型,那么你就只能使用 thenCompose方法。
组合Futurue结果
如果你有两个异步操作互相没有依赖,但是第三步操作依赖前两部计算的结果,那么你可以使用 thenCombine 方法来实现,如下面代码:
public static void main(String[] args) throws Exception {
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> "挖坑完成")
.thenCombine(CompletableFuture.supplyAsync(() -> ", 拿树苗完成"), (x, y) -> x + y + "植树完成");
System.out.println("result is " + completableFuture.get());
}
// result is 挖坑完成, 拿树苗完成植树完成挖坑和拿树苗可以同时进行,但是第三步植树则祖尧前两步完成后才能进行。
可以看到符合我们的预期。使用场景之前也提到过。我们调用多个微服务的接口时,可以使用这种方式进行组合。处理接口调用间的依赖关系。 当你需要两个 Future 的结果,但是不需要再加工后向下游传递计算结果时,可以使用 thenAcceptBoth,用法一样,只不过接收的函数没有返回值。
并行处理多个 Future
假如我们对微服务接口的调用不止两个,并且还有一些其它可以异步执行的逻辑。主流程需要等待这些所有的异步操作都返回时,才能继续往下执行。此时我们可以使用 CompletableFuture.allOf 方法。它接收 n 个 CompletableFuture,返回一个 CompletableFuture。对其调用 get 方法后,只有所有的 CompletableFuture 全完成时才会继续后面的逻辑。我们看下面示例代码:
public static void main(String[] args) throws Exception {
CompletableFuture<Void> future1 = CompletableFuture.runAsync(() -> {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("挖坑完成");
});
CompletableFuture<Void> future2 = CompletableFuture.runAsync(() -> {
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("取树苗完成");
});
CompletableFuture<Void> future3 = CompletableFuture.runAsync(() -> {
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("取肥料完成");
});
CompletableFuture.allOf(future1, future2, future3).get();
System.out.println("植树准备工作完成!");
}
// 挖坑完成
// 取肥料完成
// 取树苗完成
// 植树准备工作完成!异常处理
在异步计算链中的异常处理可以采用 handle 方法,它接收两个参数,第一个参数是计算及过,第二个参数是异步计算链中抛出的异常。使用方法如下:
public static void main(String[] args) throws Exception {
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> {
if (1 == 1) {
throw new RuntimeException("Computation error");
}
return "挖坑完成";
}).handle((result, throwable) -> {
if (result == null) {
return "挖坑异常";
}
return result;
});
System.out.println("result is " + completableFuture.get());
}
// result is 挖坑异常代码中会抛出一个 RuntimeException,抛出这个异常时 result 为 null,而 throwable 不为null。根据这些信息你可以在 handle 中进行处理,如果抛出的异常种类很多,你可以判断 throwable 的类型,来选择不同的处理逻辑。
The above is the detailed content of How does java multi-threading assemble asynchronous computing units through CompletableFuture?. For more information, please follow other related articles on the PHP Chinese website!