

 Technology peripheralsAIEven the century-old meme is clear! Microsoft's multi-modal 'Universe' handles IQ testing with only 1.6 billion parameters
Technology peripheralsAIEven the century-old meme is clear! Microsoft's multi-modal 'Universe' handles IQ testing with only 1.6 billion parametersEven the century-old meme is clear! Microsoft's multi-modal 'Universe' handles IQ testing with only 1.6 billion parameters

I can’t keep up with the volume of the big model without sleeping...
No, Microsoft Asia The institute has just released a multimodal large language model (MLLM) - KOSMOS-1.

Paper address: https://arxiv.org/pdf/2302.14045.pdf
The title of the paper, Language Is Not All You Need, comes from a famous saying.
There is a sentence in the article, "The limitations of my language are the limitations of my world. - Austrian philosopher Ludwig Wittgenstein"

##Then the question comes...
Can you figure it out by asking KOSMOS-1 "Is it a duck or a rabbit" while holding the picture? This meme with a history of more than 100 years just can’t fix Google AI.

In 1899, American psychologist Joseph Jastrow first used the "Duck and Rabbit Chart" to It shows that perception is not only what people see, but also a mental activity.
#Now, KOSMOS-1 can combine this kind of perception and language model.
#-What’s in the picture?
#-Like a duck.
#-If not a duck, what is it?
#-Looks more like a rabbit.
-Why?
#-It has bunny ears.
#If you ask this question, KOSMOS-1 is really a bit like Microsoft’s version of ChatGPT.

Not only that, Kosmos-1 can also understand images, text, and text with text. Images, OCR, image captions, visual QA.
# Even IQ tests are not a problem.
"Universe" is omnipotentKosmos comes from the Greek word cosmos, which means "universe".
#According to the paper, the latest Kosmos-1 model is a multi-modal large-scale language model.
The backbone is a causal language model based on Transformer. In addition to text, other modalities, such as vision and audio, can be embedded in the model.
The Transformer decoder serves as a universal interface for multi-modal inputs, so it can perceive general modalities, perform context learning, and follow instructions.
Kosmos-1 achieves impressive performance on language and multimodal tasks without fine-tuning, including image recognition with text instructions, visual question answering, and multimodal dialogue .
#The following are some example styles generated by Kosmos-1.
Picture explanation, picture question and answer, web page question answer, simple number formula, and number recognition.

So, on which data sets is Kosmos-1 pre-trained?
The database used for training includes text corpus, image-subtitle pairs, image and text cross data sets.
Text corpus taken from The Pile and Common Crawl (CC);
Images -The sources of subtitle pairs are English LAION-2B, LAION-400M, COYO-700M and Conceptual Captions;
The source of text cross data set is Common Crawl snapshot .
#Now that the database is available, the next step is to pre-train the model.
The MLLM component has 24 layers, 2,048 hidden dimensions, 8,192 FFNs and 32 attention heads, resulting in approximately 1.3B parameters.
In order to ensure the stability of the optimization, Magneto initialization is used; in order to converge faster, the image representation is derived from a pre-trained image with 1024 feature dimensions. Obtained from CLIP ViT-L/14 model. During the training process, images are preprocessed to 224×224 resolution, and the parameters of the CLIP model are frozen except for the last layer.
#The total number of parameters of KOSMOS-1 is approximately 1.6 billion.
To better align KOSMOS-1 with instructions, language-only instruction adjustments were made [LHV 23, HSLS22], i.e. The model continues to be trained on instruction data, which is the only language data, mixed with the training corpus.
The tuning process is carried out according to the language modeling method, and the selected instruction data sets are Unnatural Instructions [HSLS22] and FLANv2 [LHV 23].
#The results show that the improvement in command following ability can be transferred across modes.
In short, MLLM can benefit from cross-modal transfer, transferring knowledge from language to multimodality and vice versa;
10 tasks in 5 categories, all figured out
You will know if a model is easy to use or not, just take it out and play around.
The research team conducted experiments from multiple angles to evaluate the performance of KOSMOS-1, including ten tasks in 5 categories:
1 Language tasks (language understanding, language generation, text classification without OCR)
2 Multi-modal transfer (common sense Reasoning)
3 Nonverbal Reasoning (IQ Test)
4 Perception - Verbal Tasks (image description, visual Q&A, web Q&A)
5 Vision tasks (zero-shot image classification, zero-shot image classification with description)
No OCR Text Classification
This is a text and image-focused understanding task that does not rely on optical character recognition (OCR).
The accuracy of KOSMOS-1 on HatefulMemes and on the Rendered SST-2 test set is higher than other models.
Although Flamingo explicitly provides OCR text into the prompt, KOSMOS-1 does not access any external tools or resources, which demonstrates that KOSMOS-1 reads and understands the rendering The inherent ability of text within images.
IQ Test
Raven Intelligence Test is an assessment One of the most commonly used tests of non-verbal.
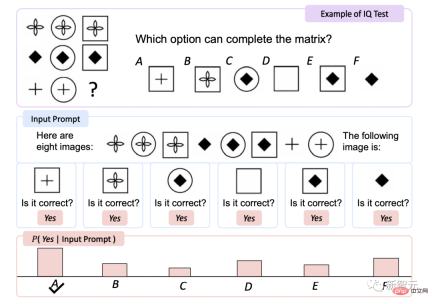
KOSMOS-1 improves accuracy by 5.3% compared to random selection without fine-tuning , after fine-tuning, it increased by 9.3%, indicating its ability to perceive abstract concept patterns in non-linguistic environments.
This is the first time a model has been able to complete the zero-shot Raven test, demonstrating the potential of MLLMs for zero-shot non-verbal reasoning by combining perception and language models.

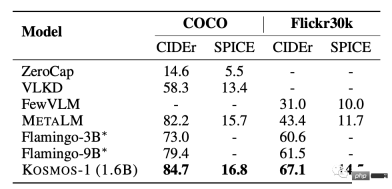
##Image description
KOSMOS-1 has excellent zero-sample performance in both COCO and Flickr30k tests. Compared with other models, it scores higher but uses a smaller number of parameters.
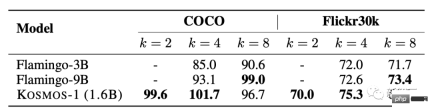
In the few-sample performance test, the score increases as the k value increases .
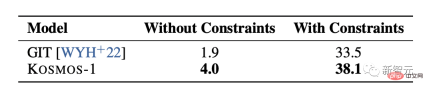
##Zero-shot image classification
Given an input image, connect the image with the prompt "The photo of the". Then, feed the model to get the class name of the image.

By evaluating the model on ImageNet [DDS 09], both with and without constraints Under constrained conditions, the image classification effect of KOSMOS-1 is significantly better than that of GIT [WYH 22], demonstrating its powerful ability to complete visual tasks.
## Common sense reasoning Visual common sense reasoning tasks require models to understand the properties of everyday objects in the real world, such as color, size, and shape. These tasks are challenging because they may require more information about them than in text. Information about object properties. The results show that the reasoning ability of KOSMOS-1 is significantly better than the LLM model in terms of size and color. This is mainly because KOSMOS-1 has multi-modal transfer capabilities, which enables it to apply visual knowledge to language tasks without having to rely on textual knowledge and clues for reasoning like LLM. 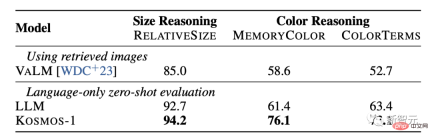
##For Microsoft Kosmos-1, netizens praised Dao, in the next 5 years, I can see an advanced robot browsing the web and working based on human text input only through visual means. Such interesting times.

The above is the detailed content of Even the century-old meme is clear! Microsoft's multi-modal 'Universe' handles IQ testing with only 1.6 billion parameters. For more information, please follow other related articles on the PHP Chinese website!

 Gemma Scope: Google's Microscope for Peering into AI's Thought ProcessApr 17, 2025 am 11:55 AM
Gemma Scope: Google's Microscope for Peering into AI's Thought ProcessApr 17, 2025 am 11:55 AMExploring the Inner Workings of Language Models with Gemma Scope Understanding the complexities of AI language models is a significant challenge. Google's release of Gemma Scope, a comprehensive toolkit, offers researchers a powerful way to delve in
 Who Is a Business Intelligence Analyst and How To Become One?Apr 17, 2025 am 11:44 AM
Who Is a Business Intelligence Analyst and How To Become One?Apr 17, 2025 am 11:44 AMUnlocking Business Success: A Guide to Becoming a Business Intelligence Analyst Imagine transforming raw data into actionable insights that drive organizational growth. This is the power of a Business Intelligence (BI) Analyst – a crucial role in gu
 How to Add a Column in SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AM
How to Add a Column in SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AMSQL's ALTER TABLE Statement: Dynamically Adding Columns to Your Database In data management, SQL's adaptability is crucial. Need to adjust your database structure on the fly? The ALTER TABLE statement is your solution. This guide details adding colu
 Business Analyst vs. Data AnalystApr 17, 2025 am 11:38 AM
Business Analyst vs. Data AnalystApr 17, 2025 am 11:38 AMIntroduction Imagine a bustling office where two professionals collaborate on a critical project. The business analyst focuses on the company's objectives, identifying areas for improvement, and ensuring strategic alignment with market trends. Simu
 What are COUNT and COUNTA in Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AM
What are COUNT and COUNTA in Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AMExcel data counting and analysis: detailed explanation of COUNT and COUNTA functions Accurate data counting and analysis are critical in Excel, especially when working with large data sets. Excel provides a variety of functions to achieve this, with the COUNT and COUNTA functions being key tools for counting the number of cells under different conditions. Although both functions are used to count cells, their design targets are targeted at different data types. Let's dig into the specific details of COUNT and COUNTA functions, highlight their unique features and differences, and learn how to apply them in data analysis. Overview of key points Understand COUNT and COU
 Chrome is Here With AI: Experiencing Something New Everyday!!Apr 17, 2025 am 11:29 AM
Chrome is Here With AI: Experiencing Something New Everyday!!Apr 17, 2025 am 11:29 AMGoogle Chrome's AI Revolution: A Personalized and Efficient Browsing Experience Artificial Intelligence (AI) is rapidly transforming our daily lives, and Google Chrome is leading the charge in the web browsing arena. This article explores the exciti
 AI's Human Side: Wellbeing And The Quadruple Bottom LineApr 17, 2025 am 11:28 AM
AI's Human Side: Wellbeing And The Quadruple Bottom LineApr 17, 2025 am 11:28 AMReimagining Impact: The Quadruple Bottom Line For too long, the conversation has been dominated by a narrow view of AI’s impact, primarily focused on the bottom line of profit. However, a more holistic approach recognizes the interconnectedness of bu
 5 Game-Changing Quantum Computing Use Cases You Should Know AboutApr 17, 2025 am 11:24 AM
5 Game-Changing Quantum Computing Use Cases You Should Know AboutApr 17, 2025 am 11:24 AMThings are moving steadily towards that point. The investment pouring into quantum service providers and startups shows that industry understands its significance. And a growing number of real-world use cases are emerging to demonstrate its value out


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

