
Home >Backend Development >Python Tutorial >How to use Python's json module and pickle module
How to use Python's json module and pickle module

- 王林forward
- 2023-05-09 15:43:141079browse
json module
json is used for data exchange between different languages, such as between C and Python, etc., which can be cross-language. Pickle can only be used for data exchange between python and python.
Serialization and Deserialization
The process by which we change objects (variables) from memory to storable or transferable is called serialization. It is called pickling in Python and pickling in other languages. It is also called serialization, marshalling, flattening, etc., all with the same meaning. After serialization, the serialized content can be written to disk or transmitted to other machines through the network. In turn, rereading the variable content from the serialized object into memory is called deserialization, that is, unpickling.
If we want to transfer objects between different programming languages, we must serialize the object into a standard format, such as XML, but a better way is to serialize it into JSON, because JSON is expressed as a character Strings can be read by all languages and can be easily stored to disk or transmitted over the network. JSON is not only a standard format and faster than XML, but it can also be read directly in Web pages, which is very convenient.
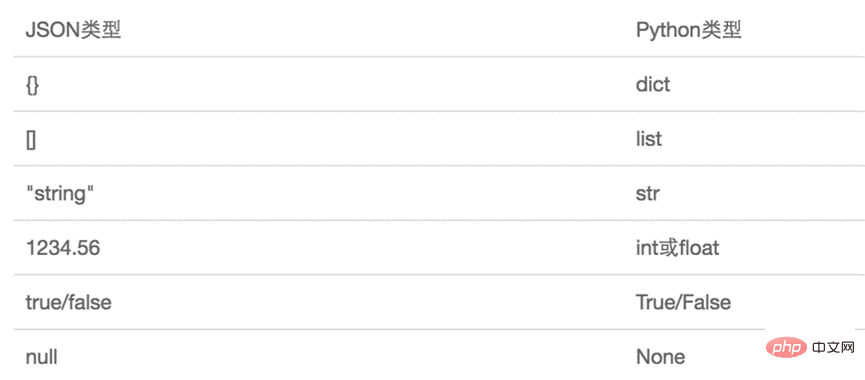
The object represented by JSON is a standard JavaScript language object. The corresponding data types between JSON and Python are as follows:
Write and read in the file Data-Dictionary
dic =' {‘string1':'hello'}' #写文件只能写入字符串 - 手动把字典变成字符串
f = open(‘hello', ‘w')
f.write(dic)f_read = open(‘hello', ‘r') data = f_read.read() #从文件中读出的都是字符串 data = eval(data) #提取出字符串中的字典 print(data[‘name'])
json implements the above functions - json can transmit data in any language
dic = {‘string1':'hello'}
data = json.dumps(dic)
print(data)
print(type(data)) #dumps()会把我们的变量变成一个json字符串
f = open(“new_hello”, “w”)
f.write(data)There is a difference between the json string and the string we manually add ’’ , which follows the json string specification, that is, the string is enclosed in double quotes.
dumps will turn any data type we pass in into a string enclosed in double quotes
# {‘string1':'hello'} ---> “{“string1”:”hello”}”
# 8 ---> “8”
# ‘hello' ---> ““hello”” – 被json包装后的数据内部只能有双引号
#[1, 2] ---> “[1, 2]”We convert the data into a json string when storing or transmitting, which can achieve any Language general
f_read = open(“new_hello”, “r”) data = json.loads(f_read.read()) #这个data直接就是字典类型 print(data) print(type(data))
Methods in json module
json.dumps() # 把数据包装成json字符串 – 序列化 json.loads() # 从json字符串中提取出原来的数据 – 反序列化
We wrap a list l = [1, 2, 3] into a json string in python and store or send it out, if When we use json parsing in C language, we will get the corresponding data structure in C language, and the extracted data is an array buf[3] = {1, 2, 3}.
This does not mean that dumps and loads must be used together. As long as the json string conforms to the json specification, loads can be used to process and extract the data structure. It does not matter whether dumps are used or not.
json.dump(data, f) #转换成json字符串并写入文件 #相当于 data = json.dumps(dic) + f.write(data) data = json.load(f) #先读取文件,再提取出数据 #相当于data = json.loads(f_read.read())
Example:
#----------------------------序列化
import json
dic={'name':'alvin','age':23,'sex':'male'}
print(type(dic))#<class 'dict'>
j=json.dumps(dic)
print(type(j))#<class 'str'>
f=open('序列化对象','w')
f.write(j) #-------------------等价于json.dump(dic,f)
f.close()#-----------------------------反序列化<br> import json f=open('序列化对象') data=json.loads(f.read())# 等价于data=json.load(f)
Note:
import json
#dct="{'1':111}"#json 不认单引号
#dct=str({"1":111})#报错,因为生成的数据还是单引号:{'one': 1}
dct='{"1":"111"}'
print(json.loads(dct))No matter how the data is created, as long as it meets the json format, it can be json.loads out and does not necessarily have to be dumps Data can be loaded.
pickle module
The problem with Pickle is the same as the serialization problem specific to all other programming languages, which is that it can only be used with Python, and it is possible that different versions of Python are incompatible with each other, so, You can only use Pickle to save unimportant data, and it doesn't matter if you can't successfully deserialize it.
##----------------------------序列化
import pickle
dic={'name':'alvin','age':23,'sex':'male'}
print(type(dic))#<class 'dict'>
j=pickle.dumps(dic)
print(type(j))#<class 'bytes'>
f=open('序列化对象_pickle','wb')#注意是w是写入str,wb是写入bytes,j是'bytes'
f.write(j) #-------------------等价于pickle.dump(dic,f)
f.close()#-------------------------反序列化 import pickle f=open('序列化对象_pickle','rb') data=pickle.loads(f.read())# 等价于data=pickle.load(f) print(data['age'])
The usage of pickle and json are the same. The scientific names of both are called serialization, but the result of json serialization is a string, and the result of pickle serialization is bytes. That is to say, the form is different, but the content is the same. However, what is serialized by pickle is bytes, that is, the data to be written to the file is bytes, so when open opens the file, it must be opened in the form of wb binary. The content written to the file by pickle is unreadable (messy characters, but the computer can recognize it), but the data written by json is readable. pickle supports more data types, and pickle can serialize functions and classes. Although json does not support these two serializations, json is still used in most scenarios.
The above is the detailed content of How to use Python's json module and pickle module. For more information, please follow other related articles on the PHP Chinese website!