

 Technology peripheralsAIYOLOv6's fast and accurate target detection framework has been open sourced
Technology peripheralsAIYOLOv6's fast and accurate target detection framework has been open sourced
Authors: Chu Yi, Kai Heng, etc.
Recently, Meituan’s Visual Intelligence Department has developed YOLOv6, a target detection framework dedicated to industrial applications, which can focus on detection accuracy and reasoning efficiency at the same time. During the research and development process, the Visual Intelligence Department continued to explore and optimize, while drawing on some cutting-edge developments and scientific research results from academia and industry. Experimental results on COCO, the authoritative target detection data set, show that YOLOv6 surpasses other algorithms of the same size in terms of detection accuracy and speed. It also supports the deployment of a variety of different platforms, greatly simplifying the adaptation work during project deployment. This is open source, hoping to help more students.
1. Overview
YOLOv6 is a target detection framework developed by Meituan’s Visual Intelligence Department and is dedicated to industrial applications. This framework focuses on both detection accuracy and inference efficiency. Among the commonly used size models in the industry: YOLOv6-nano has an accuracy of up to 35.0% AP on COCO and an inference speed of on T4. 1242 FPS; YOLOv6-s can achieve an accuracy of 43.1% AP on COCO, and an inference speed of 520 FPS on T4. In terms of deployment, YOLOv6 supports the deployment of different platforms such as GPU (TensorRT), CPU (OPENVINO), ARM (MNN, TNN, NCNN), which greatly Simplify the adaptation work during project deployment. Currently, the project has been open sourced to Github, portal: YOLOv6. Friends who are in need are welcome to Star to collect it and access it at any time.
A new framework whose accuracy and speed far exceed YOLOv5 and YOLOX
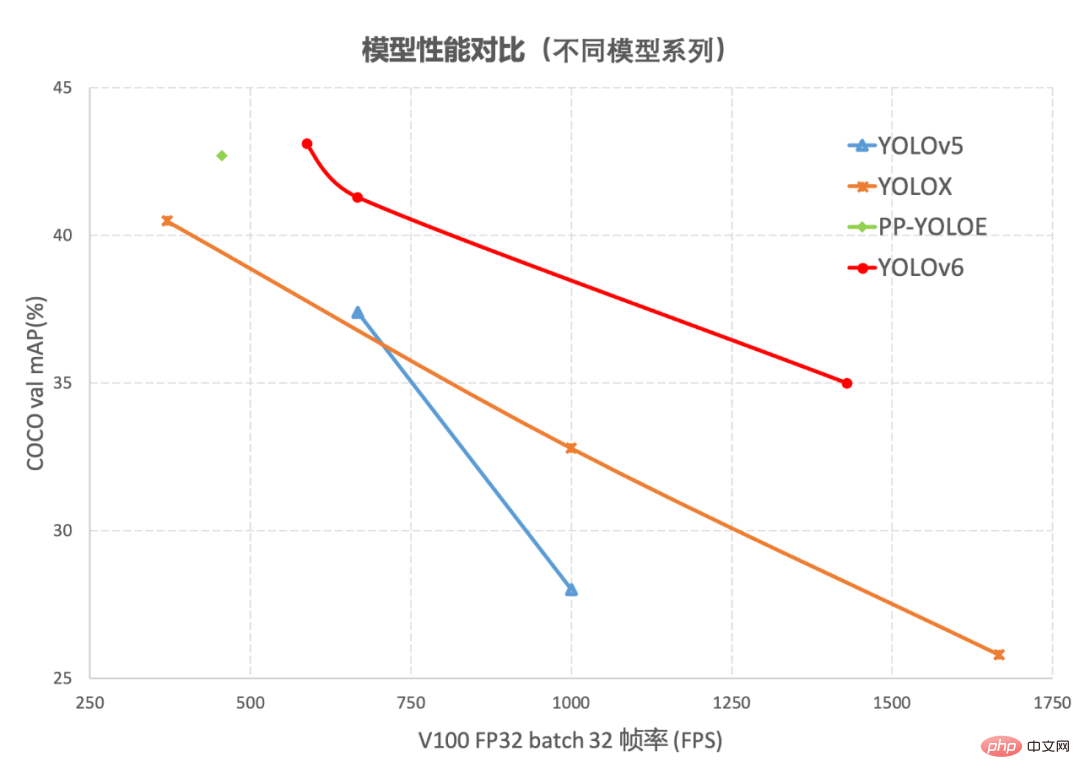
Object detection, as a basic technology in the field of computer vision, has been widely used in the industry , among which the YOLO series algorithms have gradually become the preferred framework for most industrial applications due to their good comprehensive performance. So far, the industry has derived many YOLO detection frameworks, among which YOLOv5[1], YOLOX[2] and PP-YOLOE[3] are the most representative. performance, but in actual use, we found that the above framework still has a lot of room for improvement in terms of speed and accuracy. Based on this, we developed a new target detection framework-YOLOv6 by researching and drawing on existing advanced technologies in the industry. The framework supports the full chain of industrial application requirements such as model training, inference and multi-platform deployment, and has made a number of improvements and optimizations at the algorithm level such as network structure and training strategies. On the COCO data set, YOLOv6 has both accuracy and speed. Surpassing other algorithms of the same size, the relevant results are shown in Figure 1 below:

##Figure 1-1 YOLOv6 model performance of each size and other models Comparison

Figure 1-2 Performance comparison between YOLOv6 and other models at different resolutionsFigure 1-1 shows the performance comparison of each detection algorithm under different size networks. The points on the curve respectively represent the performance of the detection algorithm under different size networks (s /tiny/nano) model performance, as can be seen from the figure, YOLOv6 surpasses other YOLO series algorithms of the same size in terms of accuracy and speed. Figure 1-2 shows the performance comparison of each detection network model when the input resolution changes. The points on the curve from left to right represent when the image resolution increases sequentially (384/448/512/576 /640) The performance of this model, as can be seen from the figure, YOLOv6 still maintains a large performance advantage under different resolutions.
2. Introduction to key technologies of YOLOv6YOLOv6 has made many improvements mainly in Backbone, Neck, Head and training strategies:
- We have designed a more efficient Backbone and Neck in a unified manner: Inspired by the design ideas of hardware-aware neural networks, we designed a reparameterizable and more efficient design based on RepVGG style[4] EfficientRep Backbone and Rep-PAN Neck.
- The more concise and effective Efficient Decoupled Head is optimized and designed to further reduce the additional delay overhead caused by general decoupled heads while maintaining accuracy.
- In terms of training strategy, we adopt the Anchor-free anchor-free paradigm, supplemented by SimOTA[2] label allocation strategy and SIoU[9] Bounding box regression loss to further improve detection accuracy.
2.1 Hardware-friendly backbone network design
The Backbone and Neck used by YOLOv5/YOLOX are both built based on CSPNet[5] , using a multi-branch approach and residual structure. For hardware such as GPUs, this structure will increase latency to a certain extent and reduce memory bandwidth utilization. Figure 2 below is an introduction to the Roofline Model[8] in the field of computer architecture, showing the relationship between computing power and memory bandwidth in hardware.

Figure 2 Roofline Model introduction diagram
So, we based on the idea of hardware-aware neural network design , Backbone and Neck have been redesigned and optimized. This idea is based on the characteristics of the hardware and the characteristics of the inference framework/compilation framework. It takes the hardware and compilation-friendly structure as the design principle. When building the network, it comprehensively considers the hardware computing power, memory bandwidth, compilation optimization characteristics, network representation capabilities, etc., and then Get fast and good network structure. For the above two redesigned detection components, we call them EfficientRep Backbone and Rep-PAN Neck respectively in YOLOv6. Their main contributions are:
- The introduction of RepVGG[4] style structure.
- Backbone and Neck have been redesigned based on hardware-aware thinking.
RepVGG[4] Style structure is a multi-branch topology during training, which can be equivalently fused into a single 3x3 during actual deployment A reparameterizable structure of convolution (The fusion process is shown in Figure 3 below). Through the fused 3x3 convolution structure, the computing power of computationally intensive hardware (such as GPU) can be effectively utilized, and the help of the highly optimized NVIDIA cuDNN and Intel MKL compilation frameworks on GPU/CPU can also be obtained. .
Experiments show that through the above strategy, YOLOv6 reduces the hardware delay and significantly improves the accuracy of the algorithm, making the detection network faster and stronger. Taking the nano-size model as an example, compared with the network structure used by YOLOv5-nano, this method improves the speed by 21% and increases the accuracy by 3.6% AP.

Figure 3 Fusion process of Rep operator[4]
EfficientRep Backbone: In terms of Backbone design, we designed an efficient Backbone based on the above Rep operator. Compared with the CSP-Backbone used by YOLOv5, this Backbone can efficiently utilize the computing power of hardware (such as GPU) and also has strong representation capabilities.
Figure 4 below is the specific design structure diagram of EfficientRep Backbone. We replaced the ordinary Conv layer with stride=2 in Backbone with the RepConv layer with stride=2. At the same time, the original CSP-Block is redesigned into RepBlock, where the first RepConv of RepBlock will transform and align the channel dimension. Additionally, we optimize the original SPPF into a more efficient SimSPPF.

Figure 4 EfficientRep Backbone structure diagram
Rep-PAN: In terms of Neck design, in order to make its reasoning on hardware more efficient and achieve a better balance between accuracy and speed, we designed a more effective feature fusion network structure for YOLOv6 based on the hardware-aware neural network design idea.
Rep-PAN is based on the PAN[6] topology, using RepBlock to replace the CSP-Block used in YOLOv5, and at the same time adjusting the operators in the overall Neck, with the purpose of While achieving efficient inference on the hardware, it maintains good multi-scale feature fusion capabilities (Rep-PAN structure diagram is shown in Figure 5 below).

Figure 5 Rep-PAN structure diagram
2.2 More concise and efficient Decoupled Head
In YOLOv6, we adopt the decoupled detection head (Decoupled Head) structure and streamline its design. The detection head of the original YOLOv5 is implemented by merging and sharing the classification and regression branches, while the detection head of YOLOX decouples the classification and regression branches, and adds two additional 3x3 convolutional layers. Although The detection accuracy is improved, but the network delay is increased to a certain extent.
Therefore, we streamlined the design of the decoupling head, taking into account the balance between the representation capabilities of the relevant operators and the computational overhead of the hardware, and redesigned it using the Hybrid Channels strategy A more efficient decoupling head structure is developed, which reduces the delay while maintaining accuracy, and alleviates the additional delay overhead caused by the 3x3 convolution in the decoupling head. By conducting ablation experiments on a nano-size model and comparing the decoupling head structure with the same number of channels, the accuracy is increased by 0.2% AP and the speed is increased by 6.8%.

Figure 6 Efficient Decoupled Head structure diagram
2.3 More effective training strategy
In order to further improve detection accuracy, we draw on advanced research progress from other detection frameworks in academia and industry: Anchor-free anchor-free paradigm, SimOTA label allocation strategy and SIoU bounding box regression loss.
Anchor-free anchor-free paradigm
YOLOv6 adopts a more concise Anchor-free detection method. Since Anchor-based detectors need to perform cluster analysis before training to determine the optimal Anchor set, this will increase the complexity of the detector to a certain extent; at the same time, in some edge-end applications, a large number of detection results need to be transported between hardware steps will also bring additional delays. The Anchor-free anchor-free paradigm has been widely used in recent years due to its strong generalization ability and simpler decoding logic. After experimental research on Anchor-free, we found that compared to the additional delay caused by the complexity of the Anchor-based detector, the Anchor-free detector has a 51% improvement in speed.
SimOTA label allocation strategy
In order to obtain more high-quality positive samples, YOLOv6 introduced SimOTA [4]The algorithm dynamically allocates positive samples to further improve detection accuracy. The label allocation strategy of YOLOv5 is based on Shape matching, and increases the number of positive samples through the cross-grid matching strategy, thereby allowing the network to converge quickly. However, this method is a static allocation method and will not be adjusted along with the network training process.
In recent years, many methods based on dynamic label assignment have emerged. Such methods will allocate positive samples based on the network output during the training process, thereby producing more high-quality Positive samples, in turn, promote forward optimization of the network. For example, OTA[7] models sample matching as an optimal transmission problem and obtains the best sample matching strategy under global information to improve accuracy. However, OTA uses the Sinkhorn-Knopp algorithm, resulting in training The time is lengthened, and the SimOTA[4] algorithm uses the Top-K approximation strategy to obtain the best match of the sample, which greatly speeds up the training. Therefore, YOLOv6 adopts the SimOTA dynamic allocation strategy and combines it with the anchor-free paradigm to increase the average detection accuracy by 1.3% AP on the nano-size model.
SIoU bounding box regression loss
In order to further improve the regression accuracy, YOLOv6 adopts SIoU[9 ] Bounding box regression loss function to supervise the learning of the network. The training of target detection networks generally requires the definition of at least two loss functions: classification loss and bounding box regression loss, and the definition of the loss function often has a greater impact on detection accuracy and training speed.
In recent years, commonly used bounding box regression losses include IoU, GIoU, CIoU, DIoU loss, etc. These loss functions consider factors such as the degree of overlap between the prediction frame and the target frame, center point distance, aspect ratio, etc. To measure the gap between the two, thereby guiding the network to minimize the loss to improve regression accuracy, but these methods do not take into account the matching of the direction between the prediction box and the target box. The SIoU loss function redefines distance loss by introducing the vector angle between required regressions, effectively reducing the degree of freedom of regression, accelerating network convergence, and further improving regression accuracy. By using SIoU loss for experiments on YOLOv6s, compared with CIoU loss, the average detection accuracy is increased by 0.3% AP.
3. Experimental results
After the above optimization strategies and improvements, YOLOv6 has achieved excellent performance in multiple models of different sizes. Table 1 below shows the ablation experimental results of YOLOv6-nano. From the experimental results, we can see that our self-designed detection network has brought great gains in both accuracy and speed. 
Table 1 YOLOv6-nano ablation experimental resultsTable 2 below shows the experimental results of YOLOv6 compared with other currently mainstream YOLO series algorithms. You can see from the table:

Table 2 Comparison of the performance of YOLOv6 models of various sizes with other models
- YOLOv6-nano achieved an accuracy of 35.0% AP on COCO val. At the same time, using TRT FP16 batchsize=32 for inference on T4, it can reach a performance of 1242FPS. Compared with YOLOv5-nano, the accuracy is increased by 7% AP. , the speed is increased by 85%.
- YOLOv6-tiny achieved an accuracy of 41.3% AP on COCO val. At the same time, using TRT FP16 batchsize=32 for inference on T4, it can achieve a performance of 602FPS, compared to YOLOv5 -s increases accuracy by 3.9% AP and speed by 29.4%.
- YOLOv6-s achieved an accuracy of 43.1% AP on COCO val. At the same time, using TRT FP16 batchsize=32 for inference on T4, it can achieve a performance of 520FPS, compared to YOLOX -s accuracy increases by 2.6% AP, and speed increases by 38.6%; compared to PP-YOLOE-s, which increases accuracy by 0.4% AP, using TRT FP16 on T4 for single-batch inference, the speed increases by 71.3%.
4. Summary and Outlook
This article introduces the optimization and practical experience of Meituan Visual Intelligence Department in the target detection framework , we have thought and optimized the training strategy, backbone network, multi-scale feature fusion, detection head, etc. for the YOLO series framework, and designed a new detection framework-YOLOv6. The original intention came from solving the actual problems encountered when implementing industrial applications. question.
While building the YOLOv6 framework, we explored and optimized some new methods, such as self-developed EfficientRep Backbone, Rep-Neck and Efficient Decoupled Head based on hardware-aware neural network design ideas. , and also draws on some cutting-edge developments and results in academia and industry, such as Anchor-free, SimOTA and SIoU regression loss. Experimental results on the COCO data set show that YOLOv6 is among the best in terms of detection accuracy and speed.
In the future, we will continue to build and improve the YOLOv6 ecosystem. The main work includes the following aspects:
- ##Improving the full range of YOLOv6 models , and continue to improve detection performance.
- Design hardware-friendly models on a variety of hardware platforms.
- Supports full-chain adaptation such as ARM platform deployment and quantitative distillation.
- Laterally expand and introduce related technologies, such as semi-supervised, self-supervised learning, etc.
- Explore the generalization performance of YOLOv6 in more unknown business scenarios.
The above is the detailed content of YOLOv6's fast and accurate target detection framework has been open sourced. For more information, please follow other related articles on the PHP Chinese website!

 美团取消订单怎么取消Mar 07, 2024 pm 05:58 PM
美团取消订单怎么取消Mar 07, 2024 pm 05:58 PM用户在使用美团下单时可以选择不想要的订单取消,有很多用户不知道美团取消订单怎么取消,用户可以在我的页面中点击进入订单待收货选择需要取消的订单点击取消。美团取消订单怎么取消1、首先在美团我的页面中点击进入订单待收货。2、然后点击进入需要取消的订单。3、点击取消订单。4、点击确定取消订单。5、最后根据个人情况选择取消原因后点击提交即可。
 美团地址在哪里改?美团地址修改教程!Mar 15, 2024 pm 04:07 PM
美团地址在哪里改?美团地址修改教程!Mar 15, 2024 pm 04:07 PM一、美团地址在哪里改?美团地址修改教程!方法(一)1.进入美团我的页面,点击设置。2.选择个人信息。3.再点击收货地址。4.最后选择要修改的地址,点击地址右侧的笔图标,修改即可。方法(二)1.在美团app首页,单击外卖,进入后点击更多功能。2.在更多界面,点击管理地址。3.在我的收货地址界面,选择编辑。4.根据需求一一进行修改,最后点击保存地址即可。
 YOLOv6又快又准的目标检测框架已经开源了May 09, 2023 pm 02:52 PM
YOLOv6又快又准的目标检测框架已经开源了May 09, 2023 pm 02:52 PM作者:楚怡、凯衡等近日,美团视觉智能部研发了一款致力于工业应用的目标检测框架YOLOv6,能够同时专注于检测的精度和推理效率。在研发过程中,视觉智能部不断进行了探索和优化,同时吸取借鉴了学术界和工业界的一些前沿进展和科研成果。在目标检测权威数据集COCO上的实验结果显示,YOLOv6在检测精度和速度方面均超越其他同体量的算法,同时支持多种不同平台的部署,极大简化工程部署时的适配工作。特此开源,希望能帮助到更多的同学。1.概述YOLOv6是美团视觉智能部研发的一款目标检测框架,致力于工业应用。
 美团app怎么删除订单 取消订单的方法Mar 12, 2024 pm 09:50 PM
美团app怎么删除订单 取消订单的方法Mar 12, 2024 pm 09:50 PM对于上面的各项功能我相信很多玩家用户们应该都对此都非常的了解,所以对于我们在使用时候的那种订单的时候,都能够让你们更好的对于一些订单有所了解,所以我们在选择购买的时候,都可以直接的去进行一些生成,不过对于自己想要取消的一些订单的时候,都可以直接的过来多方面的了解一下其中的方法,为了让大家们更好的对其了解,以后方便自己来进行多方面的操作,今日小编就来给你好好的讲解一下其中的内容方法,有任何想法的朋友们,一定不能够错过,现在就赶紧和小编一起来试一试吧,我相信你们一定会非常的感兴趣的,不要错过了。
 美团超时怎么赔付?美团超时赔付标准!Mar 16, 2024 pm 07:55 PM
美团超时怎么赔付?美团超时赔付标准!Mar 16, 2024 pm 07:55 PM一、美团超时怎么赔付?美团超时赔付标准!美团超时赔付规则如下:(一)购买了准时宝服务的超时:选择准时宝服务后,如外卖骑手未能按时送达,系统将自动启动赔偿流程,赔偿金额根据订单细节和超时时长而定。(二)未购买准时宝的普通超时:1.订单实际送达时间晚于承诺送达时间10分钟以上、20分钟以下的,赔付订单实际支付金额的25%。2.订单实际送达时间晚于承诺送达时间20分钟以上、30分钟以下的,赔付订单实际支付金额的30%。3.订单实际送达时间晚于承诺送达时间30分钟以上的,赔付订单实际支付金额的50%。4
 美团怎么取消订单 取消订单的方法介绍Mar 13, 2024 am 11:01 AM
美团怎么取消订单 取消订单的方法介绍Mar 13, 2024 am 11:01 AM我们在使用这款平台的时候,我相信很多用户们应该都能了解得到,上面是可以购买订购很多的一些东西,电影票啊,或者是外卖,还是一些优惠券,酒店等等预订都是可以的,那么我们在平台上面是怎么来进行去掉订单的呢,也去很多用户们对此可能并不是非常的了解,其实我们在上面不管是对于哪一些的订购,都是可以进行取消订单退款都是没有问题的,前提是你没有使用过,我们在订单里面就可以找得到,然后进行取消退款就可以了,效果还是特别方便的,所以对此方面,如果你们也感兴趣的话,现在就和小编一起来试一试吧,我相信你会喜欢的。
 手机美团怎么不能修改评价了Nov 14, 2023 pm 01:40 PM
手机美团怎么不能修改评价了Nov 14, 2023 pm 01:40 PM手机美团不能修改评价的原因:1、评价不符合平台规定,可以联系美团客服咨询具体情况;2、评价已经生效,可以联系商家或平台客服进行沟通;3、评价权限被限制,可以查看平台的相关规定或联系客服了解更多信息;4、软件或网络问题,可以尝试重新启动应用程序、检查网络连接或尝试更新应用程序版本;5、评价时间过久;6、评价次数过多,可以暂停一段时间再尝试修改评价;7、账户问题等等。
 美团怎么删除评价 删除评价操作方法Mar 12, 2024 pm 07:31 PM
美团怎么删除评价 删除评价操作方法Mar 12, 2024 pm 07:31 PM我们在使用这款平台的时候,上面也是拥有对于各种美食还有消费方面都是有评价的,其中的一些操作方法也是极为简单的,我们所去消费的时候,都应该能够看到上面对于一些功能方面的一些选择,都是可以自己来进行一些打分评价的,不过有些时候我们可能要自己来删除对于一些店铺方面的错误评价,但是用户们不知道怎么去进行这些评价,所以今日小编就来给你们详细的讲解上面的一些功能,所以有任何想法的,今日小编就来给你们详解怎么去进行删除,有兴趣的话,现在就和小编一起来看看吧,我相信大家们应该都会有所了解,不要错过了。 删


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Atom editor mac version download
The most popular open source editor

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

SublimeText3 Linux new version
SublimeText3 Linux latest version

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

