

 Technology peripheralsAIEMNLP 2022 conference officially concluded, best long paper, best short paper and other awards announced
Technology peripheralsAIEMNLP 2022 conference officially concluded, best long paper, best short paper and other awards announced
Recently, EMNLP 2022, the top conference in the field of natural language processing, was held in Abu Dhabi, the capital of the United Arab Emirates.

A total of 4190 papers were submitted to this year’s conference. In the end, 829 papers were accepted (715 long papers, 114 papers), and the overall acceptance rate was 20%, not much different from previous years.

The conference ended on December 11, local time, and the paper awards for this year were also announced, including Best Long Paper (1), Best Short Paper (1 piece), Best Demo Paper (1 piece).
Best Long Paper

Paper: Abstract Visual Reasoning with Tangram Shapes
- Authors: Anya Ji, Noriyuki Kojima, Noah Rush, Alane Suhr, Wai Keen Vong, Robert D. Hawkins, Yoav Artzi
- Organization: Kang Nair University, New York University, Allen Institute, Princeton University
- Paper link: https://arxiv.org/pdf/2211.16492.pdf
Paper abstract: In this paper, the researcher introduces "KiloGram", a user A resource library for studying abstract visual reasoning in humans and machines. KiloGram greatly improves existing resources in two ways. First, the researchers curated and digitized 1,016 shapes, creating a collection that was two orders of magnitude larger than those used in existing work. This collection greatly increases coverage of the entire range of naming variation, providing a more comprehensive perspective on human naming behavior. Second, the collection treats each tangram not as a single overall shape, but as a vector shape made up of the original puzzle pieces. This decomposition enables reasoning about whole shapes and their parts. The researchers used this new collection of digital jigsaw puzzle graphics to collect a large amount of textual description data, reflecting the high diversity of naming behavior.
We leveraged crowdsourcing to extend the annotation process, collecting multiple annotations for each shape to represent the distribution of annotations it elicited rather than a single sample. A total of 13,404 annotations were collected, each describing a complete object and its divided parts.
KiloGram’s potential is extensive. We used this resource to evaluate the abstract visual reasoning capabilities of recent multimodal models and observed that pre-trained weights exhibited limited abstract reasoning capabilities that improved greatly with fine-tuning. They also observed that explicit descriptions facilitate abstract reasoning by both humans and models, especially when jointly encoding language and visual input.
Figure 1 is an example of two tangrams, each with two different annotations. Each annotation includes a description of the entire shape (in bold), a segmentation of the parts (in color), and a name for each part (connected to each part). The upper example shows low variability for near perfect agreement, while the lower example shows high variability for language and segmentation divergence.

##KiloGram Address: https://lil.nlp .cornell.edu/kilogram
The best long paper nomination for this conference was won by two researchers, Kayo Yin and Graham Neubig.

Paper: Interpreting Language Models with Contrastive Explanations
- Author: Kayo Yin, Graham Neubig
Paper abstract: Model interpretability methods are often used to explain the decisions of NLP models on tasks such as text classification. , the output space of these tasks is relatively small. However, when applied to language generation, the output space often consists of tens of thousands of tokens, and these methods cannot provide informative explanations. Language models must consider various features to predict a token, such as its part of speech, number, tense, or semantics. Because existing explanatory methods combine evidence for all these features into a single explanation, this is less interpretable to human understanding.
To distinguish between different decisions in language modeling, researchers have explored language models that focus on contrastive explanations. They look for input tokens that stand out and explain why the model predicted one token but not another. Research demonstrates that contrastive explanations are much better than non-contrastive explanations at validating major grammatical phenomena, and that they significantly improve contrastive model simulatability for human observers. The researchers also identified groups of contrastive decisions for which the model used similar evidence and were able to describe which input tokens the model used in various language generation decisions.
Code address: https://github.com/kayoyin/interpret-lm
Best short paper

Paper: Topic-Regularized Authorship Representation Learning
- ## Author: Jitkapat Sawatphol, Nonthakit Chaiwong, Can Udomcharoenchaikit, Sarana Nutanong
- Institution: VISTEC Institute of Science and Technology, Thailand
Abstract :In this study, the researchers proposed Authorship Representation Regularization, a distillation framework that can improve cross-topic performance and can also handle unseen authors. This approach can be applied to any authorship representation model. Experimental results show that in the cross-topic setting, 4/6 performance is improved. At the same time, researchers' analysis shows that in data sets with a large number of topics, training shards set across topics have topic information leakage problems, thus weakening their ability to evaluate cross-topic attributes.
Best Demo Paper
Paper: Evaluate & Evaluation on the Hub: Better Best Practices for Data and Model Measurements
- ##Authors: Leandro von Werra, Lewis Tunstall, Abhishek Thakur, Alexandra Sasha Luccioni, etc.
- Organization: Hugging Face
- Paper link: https://arxiv.org/pdf/2210.01970.pdf
Paper abstract:Evaluation is a key part of machine learning (ML), and this study introduces Evaluate and Evaluation on Hub - a set of tools that help evaluate Tools for models and datasets in ML. Evaluate is a library for comparing different models and datasets, supporting various metrics. The Evaluate library is designed to support reproducibility of evaluations, document the evaluation process, and expand the scope of evaluations to cover more aspects of model performance. It includes more than 50 efficient specification implementations for a variety of domains and scenarios, interactive documentation, and the ability to easily share implementation and evaluation results.
Project address: https://github.com/huggingface/evaluate
In addition, the researcher also launched Evaluation on the Hub, the platform enables free, large-scale evaluation of over 75,000 models and 11,000 datasets on Hugging Face Hub with the click of a button.The above is the detailed content of EMNLP 2022 conference officially concluded, best long paper, best short paper and other awards announced. For more information, please follow other related articles on the PHP Chinese website!

 论文插图也能自动生成了,用到了扩散模型,还被ICLR接收Jun 27, 2023 pm 05:46 PM
论文插图也能自动生成了,用到了扩散模型,还被ICLR接收Jun 27, 2023 pm 05:46 PM生成式AI已经风靡了人工智能社区,无论是个人还是企业,都开始热衷于创建相关的模态转换应用,比如文生图、文生视频、文生音乐等等。最近呢,来自ServiceNowResearch、LIVIA等科研机构的几位研究者尝试基于文本描述生成论文中的图表。为此,他们提出了一种FigGen的新方法,相关论文还被ICLR2023收录为了TinyPaper。图片论文地址:https://arxiv.org/pdf/2306.00800.pdf也许有人会问了,生成论文中的图表有什么难的呢?这样做对于科研又有哪些帮助呢
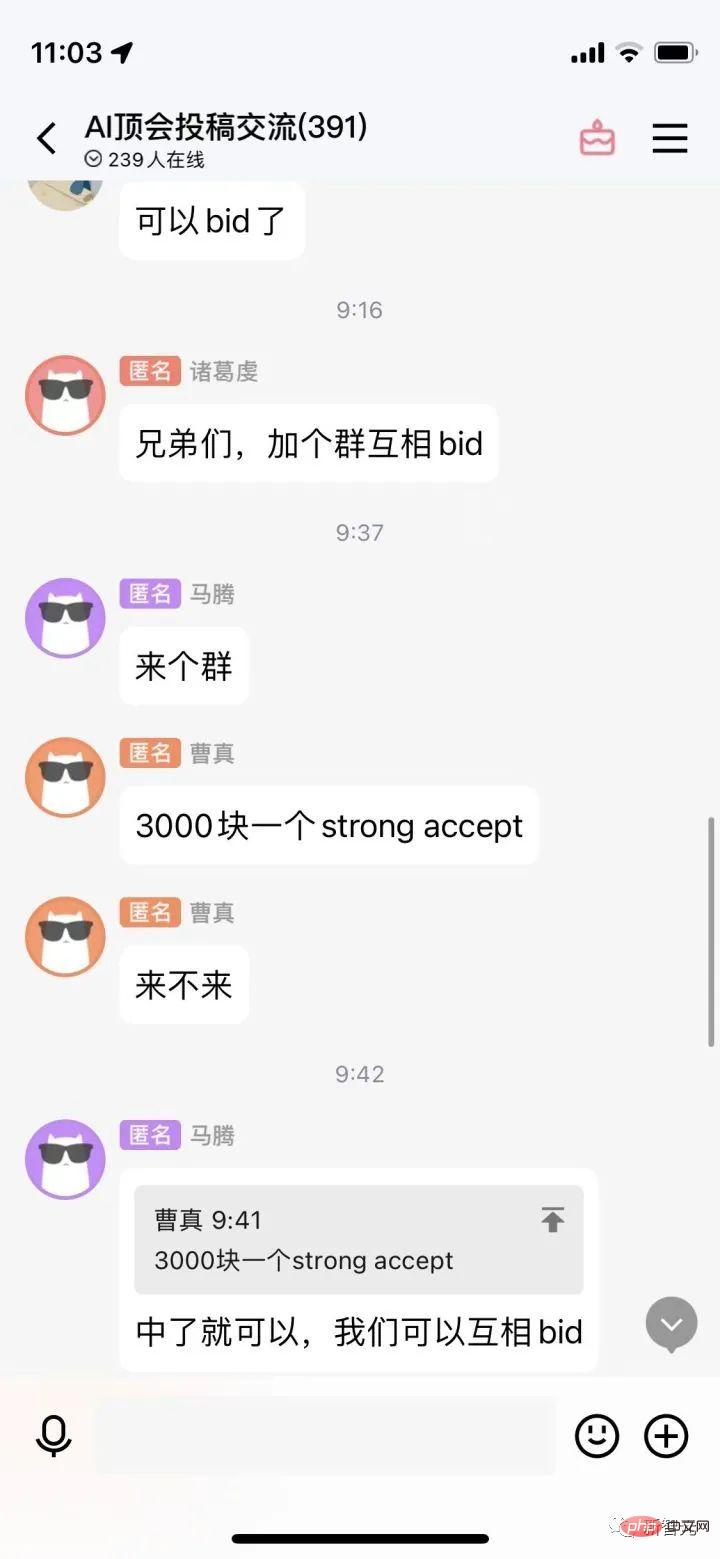 聊天截图曝出AI顶会审稿潜规则!AAAI 3000块即可strong accept?Apr 12, 2023 am 08:34 AM
聊天截图曝出AI顶会审稿潜规则!AAAI 3000块即可strong accept?Apr 12, 2023 am 08:34 AM正值AAAI 2023论文截止提交之际,知乎上突然出现了一张AI投稿群的匿名聊天截图。其中有人声称,自己可以提供「3000块一个strong accept」的服务。爆料一出,顿时引起了网友们的公愤。不过,先不要着急。知乎大佬「微调」表示,这大概率只是「口嗨」而已。据「微调」透露,打招呼和团伙作案这个是任何领域都不能避免的问题。随着openreview的兴起,cmt的各种弊端也越来越清楚,未来留给小圈子操作的空间会变小,但永远会有空间。因为这是个人的问题,不是投稿系统和机制的问题。引入open r
 CVPR 2023放榜,录用率25.78%!2360篇论文被接收,提交量暴涨至9155篇Apr 13, 2023 am 09:37 AM
CVPR 2023放榜,录用率25.78%!2360篇论文被接收,提交量暴涨至9155篇Apr 13, 2023 am 09:37 AM刚刚,CVPR 2023发文称:今年,我们收到了创纪录的9155份论文(比CVPR2022增加了12%),并录用了2360篇论文,接收率为25.78%。据统计,CVPR的投稿量在2010-2016的7年间仅从1724增加到2145。在2017年后则迅速飙升,进入快速增长期,2019年首次突破5000,至2022年投稿数已达到8161份。可以看到,今年提交了共9155份论文确实创下了最高记录。疫情放开后,今年的CVPR顶会将在加拿大举行。今年采用单轨会议的形式,并取消了传统Oral的评选。谷歌研究
 上交大校友获最佳论文,机器人顶会CoRL 2022奖项公布Apr 11, 2023 pm 11:43 PM
上交大校友获最佳论文,机器人顶会CoRL 2022奖项公布Apr 11, 2023 pm 11:43 PM自 2017 年首次举办以来,CoRL 已经成为了机器人学与机器学习交叉领域的全球顶级学术会议之一。CoRL 是面向机器人学习研究的 single-track 会议,涵盖机器人学、机器学习和控制等多个主题,包括理论与应用。2022年的CoRL大会于12月14日至18日在新西兰奥克兰举行。本届大会共收到504篇投稿,最终接收34篇Oral论文、163篇Poster论文,接收率为39%。目前,CoRL 2022 公布了最佳论文奖、最佳系统论文奖、特别创新奖等全部奖项。宾夕法尼亚大学GRASP实验
 Nature新规:用ChatGPT写论文可以,列为作者不行Apr 11, 2023 pm 01:13 PM
Nature新规:用ChatGPT写论文可以,列为作者不行Apr 11, 2023 pm 01:13 PM本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。面对ChatGPT,Nature终于坐不住了。本周,这家权威学术出版机构下场,针对ChatGPT代写学研文章、被列为作者等一系列问题,给了定性。具体来说,Nature列出两项原则:(1)任何大型语言模型工具(比如ChatGPT)都不能成为论文作者;(2)如在论文创作中用过相关工具,作者应在“方法”或“致谢”或适当的部分明确说明。现在,上述要求已经添进作者投稿指南中。近段时间,ChatGPT染指学研圈情况越来越多。去年1
 学术专用版ChatGPT火了,一键完成论文润色、代码解释、报告生成Apr 04, 2023 pm 01:05 PM
学术专用版ChatGPT火了,一键完成论文润色、代码解释、报告生成Apr 04, 2023 pm 01:05 PM用 ChatGPT 辅助写论文这件事,越来越靠谱了。 ChatGPT 发布以来,各个领域的从业者都在探索 ChatGPT 的应用前景,挖掘它的潜力。其中,学术文本的理解与编辑是一种极具挑战性的应用场景,因为学术文本需要较高的专业性、严谨性等,有时还需要处理公式、代码、图谱等特殊的内容格式。现在,一个名为「ChatGPT 学术优化(chatgpt_academic)」的新项目在 GitHub 上爆火,上线几天就在 GitHub 上狂揽上万 Star。项目地址:https://github.com/
 快速学习InstructGPT论文的关键技术点:跟随李沐掌握ChatGPT背后的技术Apr 24, 2023 pm 04:04 PM
快速学习InstructGPT论文的关键技术点:跟随李沐掌握ChatGPT背后的技术Apr 24, 2023 pm 04:04 PM在ChatGPT走红之后,很多关注技术的同学都在问一个问题:有没有什么学习资料可以让我们系统地了解ChatGPT背后的原理?由于OpenAI还没有发布ChatGPT相关论文,这一问题变得棘手起来。不过,从OpenAI关于ChatGPT的博客中我们知道,ChatGPT用到的方法和它的兄弟模型——InstructGPT一样,只不过InstructGPT是在GPT-3上微调的,而ChatGPT则是基于GPT-3.5。在数据收集工作上,二者也存在一些差别。博客链接:ht
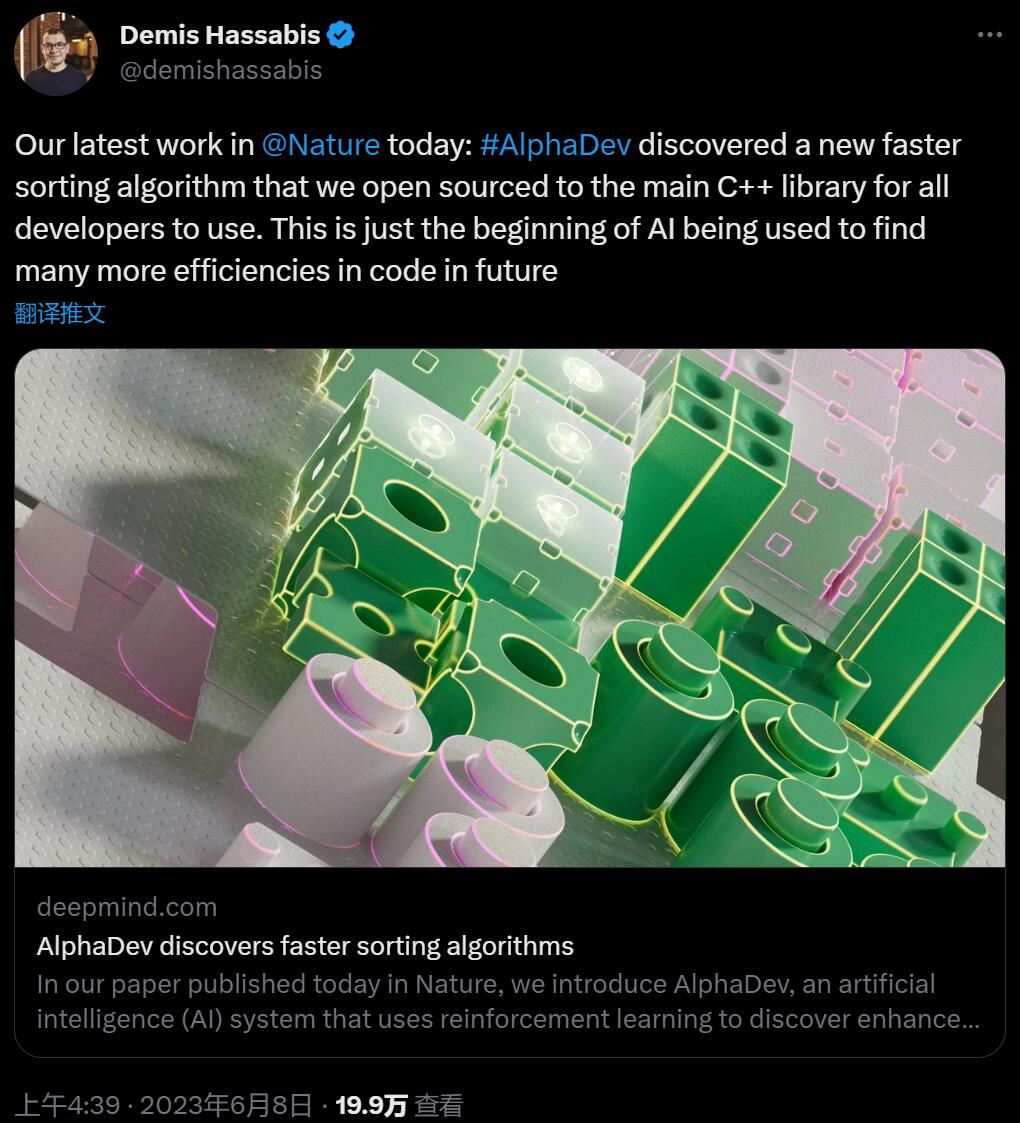 DeepMind用AI重写排序算法;将33B大模型塞进单个消费级GPUJun 12, 2023 pm 06:49 PM
DeepMind用AI重写排序算法;将33B大模型塞进单个消费级GPUJun 12, 2023 pm 06:49 PM目录:FastersortingalgorithmsdiscoveredusingdeepreinforcementlearningVideo-LLaMA:AnInstruction-tunedAudio-VisualLanguageModelforVideoUnderstandingPatch-based3DNaturalSceneGenerationfromaSingleExampleSpatio-temporalDiffusionPointProcessesSpQR:ASparse-Qua


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

SublimeText3 Linux new version
SublimeText3 Linux latest version

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

WebStorm Mac version
Useful JavaScript development tools

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

