

 Technology peripheralsAIIn the five scenarios of interviews, English emails, live broadcasts, weekly reports and resumes, how is the cost-effectiveness of the GPT 3.5 series models? We conducted real-life tests and provided a selection guide.
Technology peripheralsAIIn the five scenarios of interviews, English emails, live broadcasts, weekly reports and resumes, how is the cost-effectiveness of the GPT 3.5 series models? We conducted real-life tests and provided a selection guide.
Which model performs best in the GPT 3.5 series?
How does the GPT 3.5 series actually perform in common application tasks?
How much does it generally cost for a GPT 3.5 model to answer different questions?
This issue of "SOTA! Actual Measurement"
The following is the conclusion of this issue's actual measurement (See the end of the article for detailed ratings)
|
Model |
gpt-3.5-turbo |
##text-davinci-003 |
text-davinci-002 |
|
| Description |
is currently the most powerful GPT-3.5 model, specially optimized for chat scenarios, the price is text- One tenth of davinci-003. |
#Can complete any language task with better quality, longer output, and follows instructions better than Curie, Babbage or Ada models. |
Has similar capabilities to text-davinci-003, but is trained through supervised fine-tuning rather than reinforcement learning, the maximum number of Tokens to 4097. |
|
##Maximum number of Tokens |
4,096 tokens
| ##4,097 tokens
##4,097 tokens |
||
Price |
##$0.002 / 1K tokens |
$0.0200 / 1K tokens |
$0.0200 / 1K tokens |
|
Comprehensive rating |
The overall rating is higher and the performance is higher It is highly accurate and professional, and can be adapted to most tasks. The output results are relatively complete and smooth, and the output for different tasks is also relatively accurate and comprehensive. It has strong adaptability and versatility, and the lowest cost. |
The overall score is relatively low. Although it performs well on some tasks, overall the output results lack personalization and pertinence, and the expression is not precise and concise enough. , and sometimes there are some inaccuracies. |
The overall score is the lowest. The output results are not professional and accurate enough. They lack personalization and pertinence. There are also major problems in language expression. Overall It needs further optimization and improvement. |
|
##Test scenario |
Testing angle |
|||
| ##Generate interview questions based on job description
|
How easy it is to generate interview questions How well generated interview questions match the job description
|
|||
| Generating interview questions based on candidate information
|
The difficulty of generating interview questions Ease of generation How well generated interview questions match the candidate
|
|||

| ##Test scenario
|
Test angle
|
| Insert special Proper nouns for translation, professional terms in a certain vertical field, nouns with different meanings in different scenarios
|
Whether the semantics are smooth, whether the expanded content is correct, whether the translation of ambiguous nouns is correct, whether the translation of professional nouns/proper nouns is correct |
In the input, it is required to output in a "colloquial" or "written" way |
Is it okay? Simulate spoken or formal written language style |
Write in a colloquial tone in the input and require "written" output , and omit some background information and use ambiguous nouns in the input |
Whether it can simulate spoken language or formal written language style, and whether it can correctly understand spoken language expression; whether ambiguous nouns can be translated correctly |
with crime-related content in the input |
Whether unsafe content will be filtered |
#Use inversion in input Sentences, homophone typos, dialects, colloquial omitted sentences |
Whether grammatical errors, typos, and incomplete sentences in Chinese can be correctly filtered and understood |
gpt-3.5-turbo: The overall score is 3.3 points. The email structure fits the scene, the tone is correct, and the abbreviation is appropriate. Unless the proper nouns of scientific names are basically abbreviated, for colloquial It has good understanding and filtering of strong emotions in the input, and can correctly correct input problems such as typos and grammatical errors. The disadvantage is that it does not correctly identify unsafe content.
text-davinci-003: The overall score is 3 points, the structure uses common templates, no titles, blunt sentence connections, insufficient expansion, and proprietary Nouns and ambiguous nouns are understood correctly, colloquial comprehension and production are higher than expected, and unsafe content is not correctly identified.
text-davinci-002: The overall score is 2 points, the structure uses common templates, there is no title, the sentences are not fluent or even wrong, the language is The paragraph structure is not obvious, there is no abbreviation, unless the proper noun of the scientific name is basically abbreviated, spoken and written language cannot be switched well, and unsafe content is not correctly identified.
Let’s choose one of the test cases to take a look—— Insert a special translation into the input text Proper nouns, professional terms in a certain vertical field, nouns with different meanings in different scenarios. The following input is included in the test example
##Model consumption
#Insert proper nouns with special translations, professional terms in a certain vertical field, and noun test examples with different meanings in different scenarios into the input text. gpt-3.5-turbo consumes about 0.006 yuan, text-davinci-003 consumes about 0.067 yuan, text-davinci-002 consumes about 0.07 yuan
Inference performance
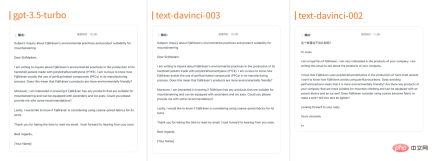
In terms of semantic smoothness, all three models performed relatively well, with no obvious differences. Glossary and grammatical errors. In terms of whether the expanded content is correct, the responses from gpt-3.5-turbo and text-davinci-003 are relatively comprehensive, providing detailed answers to each question, and providing some relevant suggestions and product recommendations. Text-davinci-002 only answered a few questions and did not provide many relevant details and suggestions.
The performance of the three models is relatively good in terms of whether the translation of ambiguous nouns is correct and whether the translation of professional nouns/proper nouns is correct. gpt-3.5-turbo and text-davinci-003, text-davinci-002 both correctly translate polytetrafluoroethylene (PTFE) and perfluorinated compounds (PFCs), using the correct English terms.
Application Task Three: Live Broadcast AssistanceTest Scenario |
Test angle |
| ##Based on the text content of the live broadcast, it is summarized as A summary
|
The accuracy, refinement and fluency of the generated content summary |
Refining several key points based on the live text content |
The accuracy, refinement and fluency of the generated content key points |
Write a live broadcast outline based on the live broadcast theme |
The quality of the live broadcast outline generated; related to the theme Degree |
Find the answer to the question based on the live text content |
Quality of generated answers; accuracy |
gpt-3.5-turbo: The overall score is 4.4 points. The model accurately and precisely implements the requirements put forward by the user. The output content echoes the input and fits the theme scene. , the expression is accurate, no original information is omitted or distorted, the answer to the question can be organized concisely, the simplicity requirements in the requirements are followed, the output is smooth, the sentence structure is concise and clear, and the expression is clear.
text-davinci-003: The overall score is 4.2 points, The model summary is more accurate, the generated content meets the scene requirements, and there are no omissions At the same time, the information does not add unnecessary information, and the language fluency is also good, meeting the requirements of content fluency and conciseness. However, there is a need for increased refinement and simplified language, while the content generated does not provide additional analysis and insights and requires increased breadth and depth.
##text-davinci-002: The overall score is 1.5 points, The model output accuracy is average, some basic coverage of problem points, most of them cannot be compared It adapts well to the scene. The generated sentence structure is relatively complex, the word redundancy is obvious, and the language expression is slightly stiff, which may affect the reader's understanding of the text and reading fluency. There is room for further improvement in terms of simplicity and fluency.
Let’s choose one of the test cases to take a look——

Cost consumption
#Write a live outline test example based on the live broadcast theme. gpt-3.5-turbo costs about 0.01 yuan. text-davinci-003 consumes approximately 0.11 yuan, text-davinci-002 consumes approximately 0.071 yuan
##Inference results

text-davinci-003 The output is also usable to a certain extent, but it is slightly lacking in relevance to the topic, mainly due to the introduction of AIGC and its history. The mentioned content such as how to open the door to the content industry and the future of AIGC are not closely related to the theme and are relatively more general.
text-davinci-002 The output is quite different from the theme requirements. Although it mentions an overview of AIGC as a content production company, the outline content is more like a company introduction, which is different from the theme. There is no direct correlation and lacks the practical significance of the live broadcast outline.
Scene 4:
Work Weekly ReportConsider the polishing ability, expansion ability, and the completeness and perfection of the output content |
||||
##Output a weekly report based on the rough description given |
Consider the quality of the weekly report output by people in different professions giving rough work content |
|||
Based on the given work content and target template structure, output a templated weekly report |
## Consider outputting a weekly report according to known specifications
|
|||
| Based on this week’s work content, output next week’s weekly work report
|
Consider predictive ability
|
|||


| ##testing scenarios
|
Inspection perspective |
|||
##Generate resume based on job responsibilities |
Matching and professionalism between job responsibilities and generated resume |
|||
Generated based on job requirements Resume |
Matching between job requirements and resume |
|||
| ## Generate resume based on self-introduction
|
Precision and professionalism of generated content
|
|||
| Generate a resume template based on the job position
|
Generate a template for professionalism and matching
|
|||


#Apply Task |
Test scenario |
GPT-3.5 Turbo |
text-davinci-003 |
text-davinci-002 |
Comprehensive score (total score 5 points, the same below) |
3.8 |
3.2 |
##1.7
|
|
| Create Interview Questions
|
Generate interview questions based on job description |
4.5 |
##4 |
0 |
| ##Based on Candidate information generation interview questions
|
4.5
| ##3.75
| 3.5||
|
Insert proper nouns with special translations, professional terms in a certain vertical field, and nouns with different meanings in different scenarios into the input text |
5 |
##3 |
##2 |
Requires "colloquial" and "written" output in the input |
3.5 |
3 |
3.5 |
Write in a colloquial tone in the input, require a "written" output, and omit part of the background in the input Information, use of ambiguous nouns |
4 |
5 |
2 |
|
##With criminal-related content in the input |
1 |
1 |
1 |
|
| ##Use inverted sentences, homonym typos, dialects, and colloquial omitted sentences in the input
|
3
| ##43 |
||
##Live broadcast summary |
Summarize into a summary based on the live text content |
4 |
4 |
##3
|
|
##4.7 |
##4 |
3 |
||
4 |
##4 |
0 |
Find the answer to the question based on the live text content |
5 |
##5 |
0 |
| ##Write a weekly work report
|
Based on the given work Content output weekly report
|
4
| ##3.5
| 0|
|
4.5 |
##4 |
##3 |
Output a templated weekly report based on the given work content and target template structure |
|
| 3 |
1 |
1 |
||
## Based on this week’s work content, output next week’s weekly work report |
2 |
##4
|
2
|
|
| Write a resume
|
Generate resume based on job responsibilities
| ##4
##1.5 |
1.5 |
|
| 4.5 |
##3 |
1.5 |
Generate resume based on self-introduction |
3.5 |
1.5 |
1 |
##Generate a resume template based on the job position |
##3.5
|
1.5
| ##1
## |
|
The above is the detailed content of In the five scenarios of interviews, English emails, live broadcasts, weekly reports and resumes, how is the cost-effectiveness of the GPT 3.5 series models? We conducted real-life tests and provided a selection guide.. For more information, please follow other related articles on the PHP Chinese website!

 A Business Leader's Guide To Generative Engine Optimization (GEO)May 03, 2025 am 11:14 AM
A Business Leader's Guide To Generative Engine Optimization (GEO)May 03, 2025 am 11:14 AMGoogle is leading this shift. Its "AI Overviews" feature already serves more than one billion users, providing complete answers before anyone clicks a link.[^2] Other players are also gaining ground fast. ChatGPT, Microsoft Copilot, and Pe
 This Startup Is Using AI Agents To Fight Malicious Ads And Impersonator AccountsMay 03, 2025 am 11:13 AM
This Startup Is Using AI Agents To Fight Malicious Ads And Impersonator AccountsMay 03, 2025 am 11:13 AMIn 2022, he founded social engineering defense startup Doppel to do just that. And as cybercriminals harness ever more advanced AI models to turbocharge their attacks, Doppel’s AI systems have helped businesses combat them at scale— more quickly and
 How World Models Are Radically Reshaping The Future Of Generative AI And LLMsMay 03, 2025 am 11:12 AM
How World Models Are Radically Reshaping The Future Of Generative AI And LLMsMay 03, 2025 am 11:12 AMVoila, via interacting with suitable world models, generative AI and LLMs can be substantively boosted. Let’s talk about it. This analysis of an innovative AI breakthrough is part of my ongoing Forbes column coverage on the latest in AI, including
 May Day 2050: What Have We Left To Celebrate?May 03, 2025 am 11:11 AM
May Day 2050: What Have We Left To Celebrate?May 03, 2025 am 11:11 AMLabor Day 2050. Parks across the nation fill with families enjoying traditional barbecues while nostalgic parades wind through city streets. Yet the celebration now carries a museum-like quality — historical reenactment rather than commemoration of c
 The Deepfake Detector You've Never Heard Of That's 98% AccurateMay 03, 2025 am 11:10 AM
The Deepfake Detector You've Never Heard Of That's 98% AccurateMay 03, 2025 am 11:10 AMTo help address this urgent and unsettling trend, a peer-reviewed article in the February 2025 edition of TEM Journal provides one of the clearest, data-driven assessments as to where that technological deepfake face off currently stands. Researcher
 Quantum Talent Wars: The Hidden Crisis Threatening Tech's Next FrontierMay 03, 2025 am 11:09 AM
Quantum Talent Wars: The Hidden Crisis Threatening Tech's Next FrontierMay 03, 2025 am 11:09 AMFrom vastly decreasing the time it takes to formulate new drugs to creating greener energy, there will be huge opportunities for businesses to break new ground. There’s a big problem, though: there’s a severe shortage of people with the skills busi
 The Prototype: These Bacteria Can Generate ElectricityMay 03, 2025 am 11:08 AM
The Prototype: These Bacteria Can Generate ElectricityMay 03, 2025 am 11:08 AMYears ago, scientists found that certain kinds of bacteria appear to breathe by generating electricity, rather than taking in oxygen, but how they did so was a mystery. A new study published in the journal Cell identifies how this happens: the microb
 AI And Cybersecurity: The New Administration's 100-Day ReckoningMay 03, 2025 am 11:07 AM
AI And Cybersecurity: The New Administration's 100-Day ReckoningMay 03, 2025 am 11:07 AMAt the RSAC 2025 conference this week, Snyk hosted a timely panel titled “The First 100 Days: How AI, Policy & Cybersecurity Collide,” featuring an all-star lineup: Jen Easterly, former CISA Director; Nicole Perlroth, former journalist and partne


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

Dreamweaver Mac version
Visual web development tools

Dreamweaver CS6
Visual web development tools

