



In 2012, Hinton et al. proposed dropout in their paper "Improving neural networks by preventing co-adaptation of feature detectors". In the same year, the emergence of AlexNet opened a new era of deep learning. AlexNet uses dropout to significantly reduce overfitting and played a key role in its victory in the ILSVRC 2012 competition. Suffice to say, without dropout, the progress we are currently seeing in deep learning might have been delayed by years.
Since the introduction of dropout, it has been widely used as a regularizer to reduce overfitting in neural networks. Dropout deactivates each neuron with probability p, preventing different features from adapting to each other. After applying dropout, the training loss usually increases while the test error decreases, thus closing the model's generalization gap. The development of deep learning continues to introduce new technologies and architectures, but dropout still exists. It continues to play a role in the latest AI achievements, such as AlphaFold protein prediction, DALL-E 2 image generation, etc., demonstrating versatility and effectiveness.
Despite dropout's continued popularity, its intensity (expressed as drop rate p) has been declining over the years. The initial dropout effort used a default drop rate of 0.5. However, in recent years, lower drop rates are often used, such as 0.1. Related examples can be seen in training BERT and ViT. The main driver of this trend is the explosion of available training data, making overfitting increasingly difficult. Combined with other factors, we may quickly end up with more underfitting than overfitting problems.
Recently in a paper "Dropout Reduces Underfitting", researchers from Meta AI, University of California, Berkeley and other institutions demonstrated how to use dropout to solve the underfitting problem.
Paper address: https://arxiv.org/abs/2303.01500
They first passed the gradient norm We examine the training dynamics of dropout using several interesting observations, and then derive a key empirical finding: during the initial stages of training, dropout reduces the gradient variance of the mini-batch and allows the model to update in a more consistent direction. These directions are also more consistent with the gradient directions across the entire dataset, as shown in Figure 1 below.
As a result, the model can more effectively optimize the training loss on the entire training set without being affected by individual mini-batches. In other words, dropout counteracts stochastic gradient descent (SGD) and prevents over-regularization caused by the randomness of sampled mini-batches early in training.

Based on this finding, researchers proposed early dropout (that is, dropout is only used in the early stages of training) to help Underfitted models fit better. Early dropout reduces the final training loss compared to no dropout and standard dropout. In contrast, for models that already use standard dropout, researchers recommend removing dropout in early training epochs to reduce overfitting. They called this method late dropout and showed that it can improve the generalization accuracy of large models. Figure 2 below compares standard dropout, early and late dropout.

Researchers used different models to evaluate early dropout and late dropout on image classification and downstream tasks, and the results show Both consistently produced better results than standard dropout and no dropout. They hope their findings can provide novel insights into dropout and overfitting and inspire further development of neural network regularizers.
Analysis and Validation
Before proposing early dropout and late dropout, this study explored whether dropout can be used as a tool to reduce underfitting. This study performed a detailed analysis of the training dynamics of dropout using its proposed tools and metrics, and compared the training processes of two ViT-T/16 on ImageNet (Deng et al., 2009): one without dropout as a baseline; the other One has a dropout rate of 0.1 throughout training.
Gradient norm (norm). This study first analyzes the impact of dropout on the strength of gradient g. As shown in Figure 6 (left) below, the dropout model produces gradients with smaller norms, indicating that it takes smaller steps with each gradient update.
Model distance. Since the gradient step size is smaller, we expect the dropout model to move a smaller distance relative to its initial point than the baseline model. As shown in Figure 6 (right) below, the study plots the distance of each model from its random initialization. However, surprisingly, the dropout model actually moved a greater distance than the baseline model, contrary to what the study originally expected based on the gradient norm.

Gradient direction variance. The study first hypothesizes that dropout models produce more consistent gradient directions across mini-batches. The variances shown in Figure 7 below are generally consistent with the assumptions. Until a certain number of iterations (about 1000), the gradient variances of both the dropout model and the baseline model fluctuate at a low level.
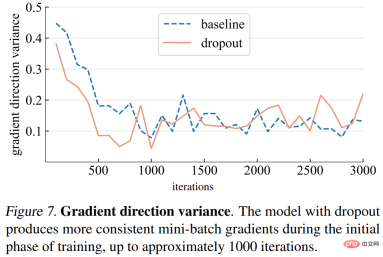
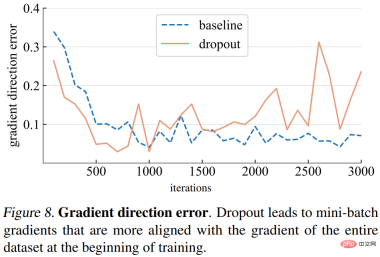
Gradient direction error. However, what should be the correct gradient direction? To fit the training data, the basic goal is to minimize the loss of the entire training set, not just the loss of any one mini-batch. The study computes the gradient of a given model over the entire training set, with dropout set to inference mode to capture the gradient of the full model. The gradient direction error is shown in Figure 8 below.
Based on the above analysis, this study found that using dropout as early as possible can potentially improve the model's ability to fit the training data. Whether a better fit to the training data is needed depends on whether the model is underfitting or overfitting, which can be difficult to define precisely. The study used the following criteria:
- #If a model generalizes better under standard dropout, it is considered to be overfitting;
- If a model performs better without dropout, it is considered underfitted.
#The state of a model depends not only on the model architecture, but also on the dataset used and other training parameters.
Then, the study proposed two methods, early dropout and late dropout
early dropout. By default, underfitted models do not use dropout. To improve its ability to adapt to training data, this study proposes early dropout: using dropout before a certain iteration and then disabling dropout during the rest of the training process. The research experiments show that early dropout reduces the final training loss and improves accuracy.
late dropout. Standard dropout is already included in the training settings for overfitting models. In the early stages of training, dropout may inadvertently cause overfitting, which is undesirable. To reduce overfitting, this study proposes late dropout: dropout is not used before a certain iteration, but is used in the rest of training.
The method proposed in this study is simple in concept and implementation, as shown in Figure 2. The implementation requires two hyperparameters: 1) the number of epochs to wait before turning dropout on or off; 2) the drop rate p, which is similar to the standard dropout rate. This study shows that these two hyperparameters can ensure the robustness of the proposed method.
Experiments and results
The researchers conducted an empirical evaluation on the ImageNet-1K classification dataset with 1000 classes and 1.2M training images, and reported top-1 verification accuracy.
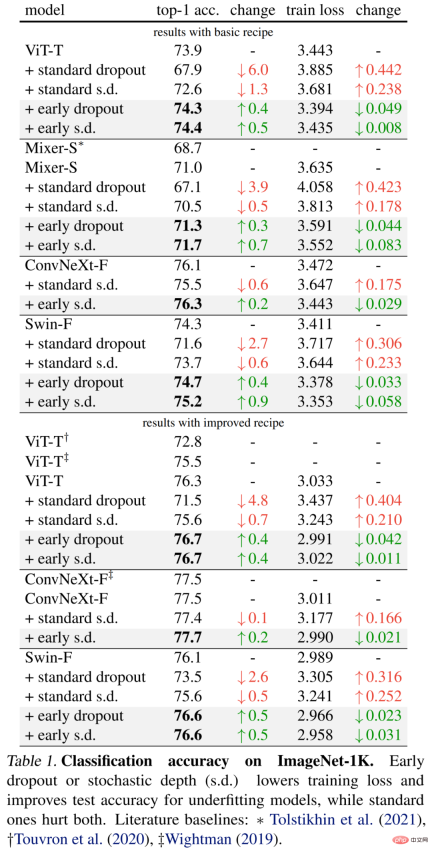
The specific results are first shown in Table 1 (upper part) below. Early dropout continues to improve test accuracy and reduce training loss, indicating that dropout in the early stage helps the model fit better. data. The researchers also show comparisons with standard dropout and stochastic depth (s.d.) using a drop rate of 0.1, both of which have a negative impact on the model.
Additionally, the researchers improved the method for these small models by doubling the training epochs and reducing the mixup and cutmix intensity. The results in Table 1 below (bottom) show significant improvements in baseline accuracy, sometimes significantly exceeding the results of previous work.
To evaluate late dropout, the researchers chose larger models, namely ViT-B and Mixer-B with 59M and 86M parameters respectively. , using basic training methods.
The results are shown in Table 3 below. Compared with standard s.d., late s.d. improves the test accuracy. This improvement is achieved while maintaining ViT-B or increasing the Mixer-B training loss, indicating that late s.d. effectively reduces overfitting.

Finally, the researchers fine-tuned the pre-trained ImageNet-1K models on downstream tasks and evaluated them . Downstream tasks include COCO object detection and segmentation, ADE20K semantic segmentation, and downstream classification on five datasets including C-100. The goal is to evaluate the learned representation during the fine-tuning phase without using early dropout or late dropout.
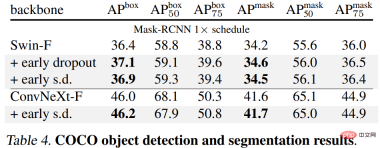
The results are shown in Tables 4, 5 and 6 below. First, when fine-tuned on COCO, the model pre-trained using early dropout or s.d. always maintains an advantage.
Secondly, for the ADE20K semantic segmentation task, the model pre-trained using this method is better than the baseline model.

Finally, there are downstream classification tasks. This method improves the generalization performance on most classification tasks.

For more technical details and experimental results, please refer to the original paper.
The above is the detailed content of Improved Dropout can be used to alleviate underfitting problems.. For more information, please follow other related articles on the PHP Chinese website!

 人工智能(AI)、机器学习(ML)和深度学习(DL):有什么区别?Apr 12, 2023 pm 01:25 PM
人工智能(AI)、机器学习(ML)和深度学习(DL):有什么区别?Apr 12, 2023 pm 01:25 PM人工智能Artificial Intelligence(AI)、机器学习Machine Learning(ML)和深度学习Deep Learning(DL)通常可以互换使用。但是,它们并不完全相同。人工智能是最广泛的概念,它赋予机器模仿人类行为的能力。机器学习是将人工智能应用到系统或机器中,帮助其自我学习和不断改进。最后,深度学习使用复杂的算法和深度神经网络来重复训练特定的模型或模式。让我们看看每个术语的演变和历程,以更好地理解人工智能、机器学习和深度学习实际指的是什么。人工智能自过去 70 多
 深度学习GPU选购指南:哪款显卡配得上我的炼丹炉?Apr 12, 2023 pm 04:31 PM
深度学习GPU选购指南:哪款显卡配得上我的炼丹炉?Apr 12, 2023 pm 04:31 PM众所周知,在处理深度学习和神经网络任务时,最好使用GPU而不是CPU来处理,因为在神经网络方面,即使是一个比较低端的GPU,性能也会胜过CPU。深度学习是一个对计算有着大量需求的领域,从一定程度上来说,GPU的选择将从根本上决定深度学习的体验。但问题来了,如何选购合适的GPU也是件头疼烧脑的事。怎么避免踩雷,如何做出性价比高的选择?曾经拿到过斯坦福、UCL、CMU、NYU、UW 博士 offer、目前在华盛顿大学读博的知名评测博主Tim Dettmers就针对深度学习领域需要怎样的GPU,结合自
 字节跳动模型大规模部署实战Apr 12, 2023 pm 08:31 PM
字节跳动模型大规模部署实战Apr 12, 2023 pm 08:31 PM一. 背景介绍在字节跳动,基于深度学习的应用遍地开花,工程师关注模型效果的同时也需要关注线上服务一致性和性能,早期这通常需要算法专家和工程专家分工合作并紧密配合来完成,这种模式存在比较高的 diff 排查验证等成本。随着 PyTorch/TensorFlow 框架的流行,深度学习模型训练和在线推理完成了统一,开发者仅需要关注具体算法逻辑,调用框架的 Python API 完成训练验证过程即可,之后模型可以很方便的序列化导出,并由统一的高性能 C++ 引擎完成推理工作。提升了开发者训练到部署的体验
 基于深度学习的Deepfake检测综述Apr 12, 2023 pm 06:04 PM
基于深度学习的Deepfake检测综述Apr 12, 2023 pm 06:04 PM深度学习 (DL) 已成为计算机科学中最具影响力的领域之一,直接影响着当今人类生活和社会。与历史上所有其他技术创新一样,深度学习也被用于一些违法的行为。Deepfakes 就是这样一种深度学习应用,在过去的几年里已经进行了数百项研究,发明和优化各种使用 AI 的 Deepfake 检测,本文主要就是讨论如何对 Deepfake 进行检测。为了应对Deepfake,已经开发出了深度学习方法以及机器学习(非深度学习)方法来检测 。深度学习模型需要考虑大量参数,因此需要大量数据来训练此类模型。这正是
 聊聊实时通信中的AI降噪技术Apr 12, 2023 pm 01:07 PM
聊聊实时通信中的AI降噪技术Apr 12, 2023 pm 01:07 PMPart 01 概述 在实时音视频通信场景,麦克风采集用户语音的同时会采集大量环境噪声,传统降噪算法仅对平稳噪声(如电扇风声、白噪声、电路底噪等)有一定效果,对非平稳的瞬态噪声(如餐厅嘈杂噪声、地铁环境噪声、家庭厨房噪声等)降噪效果较差,严重影响用户的通话体验。针对泛家庭、办公等复杂场景中的上百种非平稳噪声问题,融合通信系统部生态赋能团队自主研发基于GRU模型的AI音频降噪技术,并通过算法和工程优化,将降噪模型尺寸从2.4MB压缩至82KB,运行内存降低约65%;计算复杂度从约186Mflop
 地址标准化服务AI深度学习模型推理优化实践Apr 11, 2023 pm 07:28 PM
地址标准化服务AI深度学习模型推理优化实践Apr 11, 2023 pm 07:28 PM导读深度学习已在面向自然语言处理等领域的实际业务场景中广泛落地,对它的推理性能优化成为了部署环节中重要的一环。推理性能的提升:一方面,可以充分发挥部署硬件的能力,降低用户响应时间,同时节省成本;另一方面,可以在保持响应时间不变的前提下,使用结构更为复杂的深度学习模型,进而提升业务精度指标。本文针对地址标准化服务中的深度学习模型开展了推理性能优化工作。通过高性能算子、量化、编译优化等优化手段,在精度指标不降低的前提下,AI模型的模型端到端推理速度最高可获得了4.11倍的提升。1. 模型推理性能优化
 深度学习撞墙?LeCun与Marcus到底谁捅了马蜂窝Apr 09, 2023 am 09:41 AM
深度学习撞墙?LeCun与Marcus到底谁捅了马蜂窝Apr 09, 2023 am 09:41 AM今天的主角,是一对AI界相爱相杀的老冤家:Yann LeCun和Gary Marcus在正式讲述这一次的「新仇」之前,我们先来回顾一下,两位大神的「旧恨」。LeCun与Marcus之争Facebook首席人工智能科学家和纽约大学教授,2018年图灵奖(Turing Award)得主杨立昆(Yann LeCun)在NOEMA杂志发表文章,回应此前Gary Marcus对AI与深度学习的评论。此前,Marcus在杂志Nautilus中发文,称深度学习已经「无法前进」Marcus此人,属于是看热闹的不
 英伟达首席科学家:深度学习硬件的过去、现在和未来Apr 12, 2023 pm 03:07 PM
英伟达首席科学家:深度学习硬件的过去、现在和未来Apr 12, 2023 pm 03:07 PM过去十年是深度学习的“黄金十年”,它彻底改变了人类的工作和娱乐方式,并且广泛应用到医疗、教育、产品设计等各行各业,而这一切离不开计算硬件的进步,特别是GPU的革新。 深度学习技术的成功实现取决于三大要素:第一是算法。20世纪80年代甚至更早就提出了大多数深度学习算法如深度神经网络、卷积神经网络、反向传播算法和随机梯度下降等。 第二是数据集。训练神经网络的数据集必须足够大,才能使神经网络的性能优于其他技术。直至21世纪初,诸如Pascal和ImageNet等大数据集才得以现世。 第三是硬件。只有


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Dreamweaver CS6
Visual web development tools

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

Dreamweaver Mac version
Visual web development tools

