



The core goal of the short video recommendation system is to drive DAU growth by improving user retention. Therefore, retention is one of the core business optimization indicators of each APP. However, retention is long-term feedback after multiple interactions between users and the system, and it is difficult to decompose it into a single item or a single list. Therefore, it is difficult for traditional point-wise and list-wise models to directly optimize retention.
The reinforcement learning (RL) method optimizes long-term rewards by interacting with the environment, and is suitable for directly optimizing user retention. This work models the retention optimization problem as a Markov decision process (MDP) with infinite horizon request granularity. Each time the user requests the recommendation system to decide an action, it is used to aggregate multiple different short-term feedback estimates (watch Duration, likes, attention, comments, retweets, etc.) ranking model scoring. The goal of this work is to learn policies, minimize the cumulative time interval between multiple user sessions, increase the frequency of app openings, and thereby increase user retention.
However, due to the characteristics of the retained signal, the direct application of existing RL algorithms has the following challenges: 1) Uncertainty: the retained signal is not only determined by the recommendation algorithm, but is also interfered by many external factors; 2) Bias: The retention signal has deviations in different time periods and user groups with different levels of activity; 3) Instability: Unlike game environments that return rewards immediately, retention signals usually return within hours to days, which will cause the RL algorithm to go online Training instability problem.
This work proposes the Reinforcement Learning for User Retention algorithm (RLUR) algorithm to solve the above challenges and directly optimize retention. Through offline and online verification, the RLUR algorithm can significantly improve the secondary retention index compared to the State of Art baseline. The RLUR algorithm has been fully implemented in the Kuaishou App and can continuously achieve significant secondary retention and DAU revenue. It is the first time in the industry that RL technology has been used to improve user retention in a real production environment. This work has been accepted into the WWW 2023 Industry Track.

## Author: Cai Qingpeng, Liu Shuchang, Wang Xueliang, Zuo Tianyou, Xie Wentao, Yang Bin, Zheng Dong, Jiang Peng
Paper address: https://arxiv.org/pdf/2302.01724.pdf
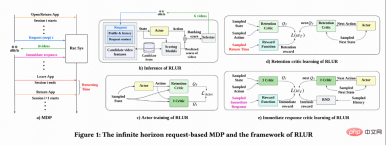
Problem ModelingAs shown in Figure 1(a), this work models the retention optimization problem as an infinite horizon request-based Markov Decision Process, in which the recommendation system is agent, the user is the environment. Every time the user opens the App, a new session i is opened. As shown in Figure 1(b), each time the user requests  the recommendation system decides a parameter vector
the recommendation system decides a parameter vector  based on the user status
based on the user status  , while n A ranking model that estimates different short-term indicators (viewing time, likes, attention, etc.) scores each candidate video j
, while n A ranking model that estimates different short-term indicators (viewing time, likes, attention, etc.) scores each candidate video j . Then the sorting function inputs the action and the scoring vector of each video to obtain the final score of each video, and selects the 6 videos with the highest scores to display to the user, and the user returns immediate feedback
. Then the sorting function inputs the action and the scoring vector of each video to obtain the final score of each video, and selects the 6 videos with the highest scores to display to the user, and the user returns immediate feedback . When the user leaves the App, this session ends. The next time the user opens the App, session i 1 is opened. The time interval between the end of the previous session and the beginning of the next session is called return time (Returning time),
. When the user leaves the App, this session ends. The next time the user opens the App, session i 1 is opened. The time interval between the end of the previous session and the beginning of the next session is called return time (Returning time),  . The goal of this research is to train a strategy that minimizes the sum of callback times for multiple sessions.
. The goal of this research is to train a strategy that minimizes the sum of callback times for multiple sessions.
RLUR Algorithm
This work first discusses how to estimate the cumulative return visit time, and then proposes methods to solve several key challenges of retained signals. These methods are summarized into the Reinforcement Learning for User Retention algorithm, abbreviated as RLUR.
Estimation of return visit time
As shown in Figure 1(d), since the action is continuous, the The work adopts the temporal difference (TD) learning method of DDPG algorithm to estimate the return visit time.

Since only the last request of each session has a return visit time reward, and the intermediate reward is 0, the author sets the discount factor The value of the last request in each session is
The value of the last request in each session is  , and the value of other requests is 1. This setting can avoid the exponential decay of return visit time. And it can be theoretically proven that when loss (1) is 0, Q actually estimates the cumulative return time of multiple sessions,
, and the value of other requests is 1. This setting can avoid the exponential decay of return visit time. And it can be theoretically proven that when loss (1) is 0, Q actually estimates the cumulative return time of multiple sessions,  .
.
Solve the delayed reward problem
Since the return visit time only occurs at the end of each session , which will bring about the problem of low learning efficiency. The authors therefore use heuristic rewards to enhance policy learning. Since short-term feedback is positively related to retention, the author uses short-term feedback as the first heuristic reward. And the author adopts Random Network Distillation (RND) network to calculate the intrinsic reward of each sample as the second heuristic reward. Specifically, the RND network uses two identical network structures. One network is randomly initialized to fixed, and the other network fits the fixed network, and the fitting loss is used as an intrinsic reward. As shown in Figure 1(e), in order to reduce the interference of heuristic rewards on retention rewards, this work learns a separate critic network to estimate the sum of short-term feedback and intrinsic rewards. Right now  .
.
Solve the problem of uncertainty
Received many recommendations due to the time of return visit The uncertainty is high due to the influence of factors, which will affect the learning effect. This work proposes a regularization method to reduce variance: first estimate a classification model  to estimate the return visit time probability, that is, whether the estimated return visit time is shorter than
to estimate the return visit time probability, that is, whether the estimated return visit time is shorter than  ; Then use Markov's inequality to get the lower bound of the return visit time,
; Then use Markov's inequality to get the lower bound of the return visit time,  ; Finally, use the actual return visit time/estimated return visit time lower bound as the regularized return visit reward.
; Finally, use the actual return visit time/estimated return visit time lower bound as the regularized return visit reward.
Solve the bias problem
Due to the large differences in behavioral habits of different active groups, highly active users The retention rate is high and the number of training samples is significantly larger than that of low-active users, which will cause model learning to be dominated by high-active users. To solve this problem, this work learns 2 independent strategies for different groups of high activity and low activity, and uses different data streams for training. The Actor minimizes the return visit time while maximizing the auxiliary reward. As shown in Figure 1(c), taking the high-activity group as an example, the Actor loss is:

Solving the instability problem
Due to the signal delay in return visit time, Generally returns within a few hours to days, which can lead to instability in RL online training. Directly using existing behavior cloning methods either greatly limits the learning speed or cannot guarantee stable learning. Therefore, this work proposes a new soft regularization method, that is, multiplying the actor loss by a soft regularization coefficient:
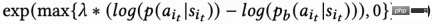
This regularization method is essentially a braking effect: if the current learning strategy and the sample strategy deviate greatly, the loss will become smaller and the learning will tend to be stable; if the learning speed tends to be stable, the loss will re- The bigger you get, the faster you learn. When  , it means there is no restriction on the learning process.
, it means there is no restriction on the learning process.
Offline experiment
This work combines RLUR and State of the Art’s reinforcement learning algorithm TD3, as well as the black-box optimization method Cross Entropy Method (CEM) in The public data set KuaiRand is used for comparison. This work first builds a retention simulator based on the KuaiRand data set: including three modules: user immediate feedback, user leaving the session, and user return visit to the app, and then evaluating the retention simulator method.

Table 1 illustrates that RLUR is significantly better than CEM and TD3 in terms of return visit time and secondary retention indicators. This study conducts ablation experiments to compare RLUR with only the retention learning part (RLUR (naive)), which can illustrate the effectiveness of this study's approach to solving retention challenges. And through the comparison of  and
and  , it is shown that the algorithm of minimizing the return visit time of multiple sessions is better than minimizing the return visit time of a single session.
, it is shown that the algorithm of minimizing the return visit time of multiple sessions is better than minimizing the return visit time of a single session.
Online experiment
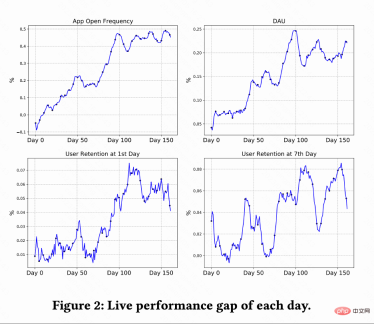
This work conducts A/B testing on the Kuaishou short video recommendation system to compare the RLUR and CEM methods . Figure 2 shows the improvement percentages of app opening frequency, DAU, first retention, and 7th retention compared to RLUR and CEM respectively. It can be found that the frequency of app opening gradually increases and even converges from 0 to 100 days. And it also drives the improvement of the second retention, 7th retention and DAU indicators (a 0.1% DAU and 0.01% improvement in second retention are considered statistically significant).
Summary and future work
This paper studies how to improve user retention of recommendation systems through RL technology. This work models retention optimization as a Marko with infinite horizon request granularity. This work proposes the RLUR algorithm to directly optimize retention and effectively address several key challenges of retention signals. The RLUR algorithm has been fully implemented in Kuaishou App and can achieve significant secondary retention and DAU revenue. Regarding future work, how to use offline reinforcement learning, Decision Transformer and other methods to more effectively improve user retention is a promising direction.
The above is the detailed content of How to use reinforcement learning to improve Kuaishou user retention?. For more information, please follow other related articles on the PHP Chinese website!

 特斯拉自动驾驶算法和模型解读Apr 11, 2023 pm 12:04 PM
特斯拉自动驾驶算法和模型解读Apr 11, 2023 pm 12:04 PM特斯拉是一个典型的AI公司,过去一年训练了75000个神经网络,意味着每8分钟就要出一个新的模型,共有281个模型用到了特斯拉的车上。接下来我们分几个方面来解读特斯拉FSD的算法和模型进展。01 感知 Occupancy Network特斯拉今年在感知方面的一个重点技术是Occupancy Network (占据网络)。研究机器人技术的同学肯定对occupancy grid不会陌生,occupancy表示空间中每个3D体素(voxel)是否被占据,可以是0/1二元表示,也可以是[0, 1]之间的
 基于因果森林算法的决策定位应用Apr 08, 2023 am 11:21 AM
基于因果森林算法的决策定位应用Apr 08, 2023 am 11:21 AM译者 | 朱先忠审校 | 孙淑娟在我之前的博客中,我们已经了解了如何使用因果树来评估政策的异质处理效应。如果你还没有阅读过,我建议你在阅读本文前先读一遍,因为我们在本文中认为你已经了解了此文中的部分与本文相关的内容。为什么是异质处理效应(HTE:heterogenous treatment effects)呢?首先,对异质处理效应的估计允许我们根据它们的预期结果(疾病、公司收入、客户满意度等)选择提供处理(药物、广告、产品等)的用户(患者、用户、客户等)。换句话说,估计HTE有助于我
 Mango:基于Python环境的贝叶斯优化新方法Apr 08, 2023 pm 12:44 PM
Mango:基于Python环境的贝叶斯优化新方法Apr 08, 2023 pm 12:44 PM译者 | 朱先忠审校 | 孙淑娟引言模型超参数(或模型设置)的优化可能是训练机器学习算法中最重要的一步,因为它可以找到最小化模型损失函数的最佳参数。这一步对于构建不易过拟合的泛化模型也是必不可少的。优化模型超参数的最著名技术是穷举网格搜索和随机网格搜索。在第一种方法中,搜索空间被定义为跨越每个模型超参数的域的网格。通过在网格的每个点上训练模型来获得最优超参数。尽管网格搜索非常容易实现,但它在计算上变得昂贵,尤其是当要优化的变量数量很大时。另一方面,随机网格搜索是一种更快的优化方法,可以提供更好的
 因果推断主要技术思想与方法总结Apr 12, 2023 am 08:10 AM
因果推断主要技术思想与方法总结Apr 12, 2023 am 08:10 AM导读:因果推断是数据科学的一个重要分支,在互联网和工业界的产品迭代、算法和激励策略的评估中都扮演者重要的角色,结合数据、实验或者统计计量模型来计算新的改变带来的收益,是决策制定的基础。然而,因果推断并不是一件简单的事情。首先,在日常生活中,人们常常把相关和因果混为一谈。相关往往代表着两个变量具有同时增长或者降低的趋势,但是因果意味着我们想要知道对一个变量施加改变的时候会发生什么样的结果,或者说我们期望得到反事实的结果,如果过去做了不一样的动作,未来是否会发生改变?然而难点在于,反事实的数据往往是
 使用Pytorch实现对比学习SimCLR 进行自监督预训练Apr 10, 2023 pm 02:11 PM
使用Pytorch实现对比学习SimCLR 进行自监督预训练Apr 10, 2023 pm 02:11 PMSimCLR(Simple Framework for Contrastive Learning of Representations)是一种学习图像表示的自监督技术。 与传统的监督学习方法不同,SimCLR 不依赖标记数据来学习有用的表示。 它利用对比学习框架来学习一组有用的特征,这些特征可以从未标记的图像中捕获高级语义信息。SimCLR 已被证明在各种图像分类基准上优于最先进的无监督学习方法。 并且它学习到的表示可以很容易地转移到下游任务,例如对象检测、语义分割和小样本学习,只需在较小的标记
 盒马供应链算法实战Apr 10, 2023 pm 09:11 PM
盒马供应链算法实战Apr 10, 2023 pm 09:11 PM一、盒马供应链介绍1、盒马商业模式盒马是一个技术创新的公司,更是一个消费驱动的公司,回归消费者价值:买的到、买的好、买的方便、买的放心、买的开心。盒马包含盒马鲜生、X 会员店、盒马超云、盒马邻里等多种业务模式,其中最核心的商业模式是线上线下一体化,最快 30 分钟到家的 O2O(即盒马鲜生)模式。2、盒马经营品类介绍盒马精选全球品质商品,追求极致新鲜;结合品类特点和消费者购物体验预期,为不同品类选择最为高效的经营模式。盒马生鲜的销售占比达 60%~70%,是最核心的品类,该品类的特点是用户预期时
 人类反超 AI:DeepMind 用 AI 打破矩阵乘法计算速度 50 年记录一周后,数学家再次刷新Apr 11, 2023 pm 01:16 PM
人类反超 AI:DeepMind 用 AI 打破矩阵乘法计算速度 50 年记录一周后,数学家再次刷新Apr 11, 2023 pm 01:16 PM10 月 5 日,AlphaTensor 横空出世,DeepMind 宣布其解决了数学领域 50 年来一个悬而未决的数学算法问题,即矩阵乘法。AlphaTensor 成为首个用于为矩阵乘法等数学问题发现新颖、高效且可证明正确的算法的 AI 系统。论文《Discovering faster matrix multiplication algorithms with reinforcement learning》也登上了 Nature 封面。然而,AlphaTensor 的记录仅保持了一周,便被人类
 研究表明强化学习模型容易受到成员推理攻击Apr 09, 2023 pm 08:01 PM
研究表明强化学习模型容易受到成员推理攻击Apr 09, 2023 pm 08:01 PM译者 | 李睿 审校 | 孙淑娟随着机器学习成为人们每天都在使用的很多应用程序的一部分,人们越来越关注如何识别和解决机器学习模型的安全和隐私方面的威胁。 然而,不同机器学习范式面临的安全威胁各不相同,机器学习安全的某些领域仍未得到充分研究。尤其是强化学习算法的安全性近年来并未受到太多关注。 加拿大的麦吉尔大学、机器学习实验室(MILA)和滑铁卢大学的研究人员开展了一项新研究,主要侧重于深度强化学习算法的隐私威胁。研究人员提出了一个框架,用于测试强化学习模型对成员推理攻击的脆弱性。 研究


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)

Dreamweaver Mac version
Visual web development tools

SublimeText3 Chinese version
Chinese version, very easy to use

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

SublimeText3 Linux new version
SublimeText3 Linux latest version

