
Home >Technology peripherals >AI >Users exceeded one million in 5 days, what's the mystery behind ChatGPT?
Users exceeded one million in 5 days, what's the mystery behind ChatGPT?

- PHPzforward
- 2023-05-04 10:19:061285browse
Translator | Li Rui
Reviewer | Sun Shujuan
OpenAI is popular again! Recently, many people have found a ruthless character in their circle of friends who is both loved and feared, so much so that StackOverflow had to remove it from the shelves in a hurry.
Recently, OpenAI released the chat AI ChatGPT. In just a few days, its number of users reached one million, and the server was even overcrowded by registered users.
How does this kind of artifact that netizens marvel at "surpasses Google search" do it? Is it reliable?
1. Event review
OpenAI company recently released ChatGPT, which is another large language model (LLM) based on the flagship GPT series and is a model specifically used for conversational interaction. Users can download the company's free demo version.
Like most large language models (LLMs) released, the release of ChatGPT also caused some controversy. Within just a few hours of its release, the new language model was causing a stir on Twitter, with users uploading screenshots of ChatGPT's impressive achievements or catastrophic failures.
However, viewed from the broad perspective of large language models, ChatGPT reflects the short but rich history of the field, representing how much progress has been made in just a few years, and what fundamental questions remain to be solved .
2. The dream of unsupervised learning
Unsupervised learning is still one of the goals pursued by the artificial intelligence community, and there is a lot of valuable knowledge and information on the Internet. But until recently, much of this information was not available to machine learning systems. Most machine learning and deep learning applications are supervised, meaning humans must take large numbers of data samples and annotate each sample to train the machine learning system.
With the advent of the Transformer architecture, a key component of large language models, this situation has changed. Transformer models can be trained using large corpora of unlabeled text. They randomly mask parts of the text and try to predict the missing parts. By repeatedly performing this operation, the Transformer adjusts its parameters to represent the relationship between different words in the large sequence.
This has proven to be a very effective and scalable strategy. Very large training corpora can be collected without the need for human labeling, allowing the creation and training of increasingly larger Transformer models. Research and experiments show that as Transformer models and Large Language Models (LLMs) increase in size, they can generate longer coherent text sequences. Large Language Models (LLMs) also demonstrate large-scale contingency capabilities.
3. Regression supervised learning?
Large language models (LLMs) are typically text-only, which means they lack the rich multi-sensory experience of humans they are trying to imitate. Although large language models (LLMs) such as GPT-3 achieve impressive results, they suffer from some fundamental flaws that make them unpredictable in tasks that require common sense, logic, planning, reasoning, and other knowledge that Usually omitted from the text. Large language models (LLMs) are known for producing illusive responses, generating coherent but factually false text, and often misinterpreting the apparent intent of user prompts.
By increasing the size of the model and its training corpus, scientists have been able to reduce the frequency of apparent errors in large language models. But the fundamental problem doesn't go away, even the largest large language models (LLMs) can make stupid mistakes with very little push.
This might not be a big problem if large language models (LLMs) were only used in scientific research labs to track performance on benchmarks. However, as interest in using large language models (LLMs) in real-world applications grows, it becomes more important to address these and other issues. Engineers must ensure that their machine learning models remain robust under varying conditions and meet user needs and requirements.
To solve this problem, OpenAI uses reinforcement learning from human feedback (RLHF) technology, which was previously developed to optimize reinforcement learning models. Rather than letting a reinforcement learning model randomly explore its environment and behavior, Reinforcement Learning with Human Feedback (RLHF) uses occasional feedback from a human supervisor to guide the agent in the right direction. The benefit of Reinforcement Learning with Human Feedback (RLHF) is that it improves the training of reinforcement learning agents with minimal human feedback.
OpenAI later applied Reinforcement Learning with Human Feedback (RLHF) to InstructGPT, a family of large language models (LLM) designed to better understand and respond to instructions in user prompts. InstructGPT is a GPT-3 model fine-tuned based on human feedback.
This is obviously a trade-off. Human annotation can become a bottleneck in the scalable training process. But by finding the right balance between unsupervised and supervised learning, OpenAI is able to achieve important benefits, including better response to instructions, reduction of harmful output, and resource optimization. According to OpenAI’s research results, the 1.3 billion parameter InstructionGPT generally outperforms the 175 billion parameter GPT-3 model in instruction following.
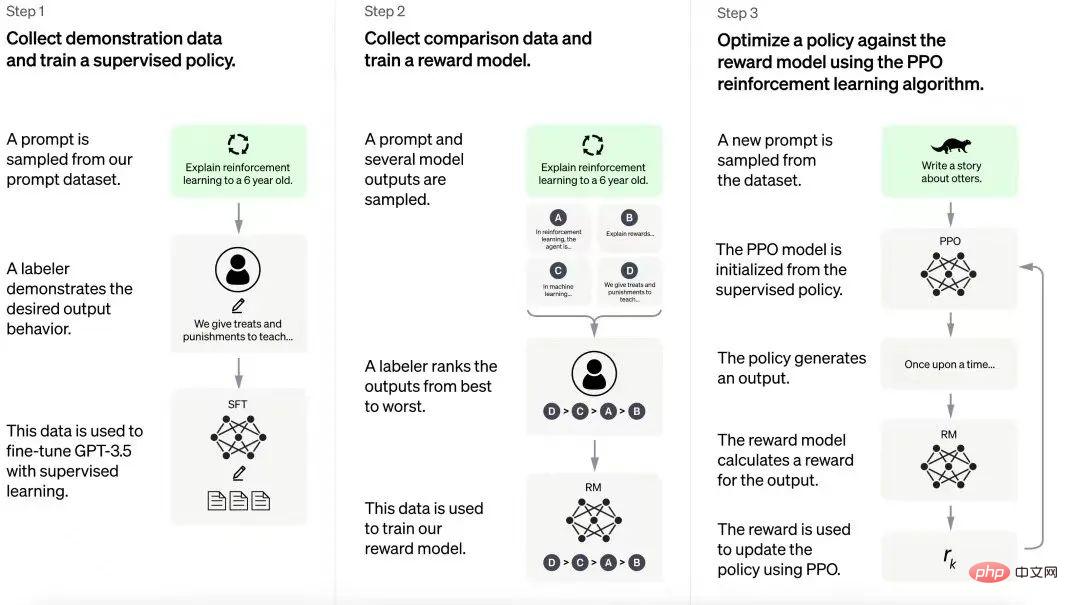
Training process of ChatGPT
ChatGPT is built on the experience gained from the InstructGPT model. The human annotator creates a set of example conversations that include user prompts and model responses. This data is used to fine-tune the GPT-3.5 model on which ChatGPT is built. In the next step, the fine-tuned model is given new prompts and given several responses. Annotators rank these responses. The data generated from these interactions is then used to train reward models, which helps further fine-tune large language models (LLMs) in reinforcement learning pipelines.
OpenAI has not disclosed the full details of the reinforcement learning process, but people are curious to know the "non-scalable cost" of this process, that is, how much manpower is required.
4. To what extent can you trust ChatGPT?
The results of ChatGPT are impressive. The model has completed a variety of tasks, including providing feedback on code, writing poetry, explaining technical concepts in different tones, and generating prompts for generative artificial intelligence models.
However, the model is also prone to mistakes similar to those made by large language models (LLMs), such as citing non-existent papers and books, misunderstanding intuitive physics, and failing at compositionality.
People are not surprised by these failures. ChatGPT doesn't work any magic and it should suffer from the same problems as its predecessor. However, where and to what extent can it be trusted in real-world applications? Clearly there is some value here, as one can see in Codex and GitHubCopilot that Large Language Models (LLMs) can be Used very effectively.
Here, what determines whether ChatGPT is useful is the kind of tools and protection implemented with it. For example, ChatGPT could become a very good platform for creating chatbots for businesses, such as digital companions for coding and graphic design. First, if it follows InstructGPT's example, you should be able to get the performance of complex models with fewer parameters, which would make it cost-effective. Furthermore, if OpenAI provides tools that enable enterprises to implement their own fine-tuning of reinforcement learning with human feedback (RLHF), it can be further optimized for specific applications, which in most cases will be more useful than chatbots. Feel free to talk about anything. Finally, if application developers are given the tools to integrate ChatGPT with application scenarios and map its inputs and outputs to specific application events and actions, they will be able to set the right guardrails to prevent models from taking unstable operate.
Basically, OpenAI created a powerful artificial intelligence tool, but with obvious flaws. It now requires creating the right ecosystem of development tools to ensure product teams can harness the power of ChatGPT. GPT-3 opens the way for many unpredictable applications, so it will be interesting to know what ChatGPT has in store.
Original link: https://bdtechtalks.com/2022/12/05/openai-chatgpt/
The above is the detailed content of Users exceeded one million in 5 days, what's the mystery behind ChatGPT?. For more information, please follow other related articles on the PHP Chinese website!