



With 100 billion neurons, each neuron has about 8,000 synapses, the complex structure of the brain inspires artificial intelligence research.
#Currently, the architecture of most deep learning models is an artificial neural network inspired by the neurons of the biological brain.

## Generative AI explodes, you can see the deep learning algorithm generating , the ability to summarize, translate and classify text is increasingly powerful.
#However, these language models still cannot match human language capabilities.
Predictive coding theory provides a preliminary explanation for this difference:
While language models can predict nearby words, the human brain constantly predicts layers of representation across multiple time scales.
To test this hypothesis, scientists at Meta AI analyzed the brain fMRI signals of 304 people who listened to the short story.
#It is concluded that hierarchical predictive coding plays a crucial role in language processing.
#Meanwhile, research illustrates how synergies between neuroscience and artificial intelligence can reveal the computational basis of human cognition.
#The latest research has been published in the Nature sub-journal Nature Human Behavior.

##Paper address: https://www.php.cn/link/7eab47bf3a57db8e440e5a788467c37f
It is worth mentioning that GPT-2 was used during the experiment. Maybe this research can inspire OpenAI’s unopened models in the future.
Wouldn’t ChatGPT be even stronger by then? Brain Predictive Coding Hierarchy
In less than 3 years, deep learning has made significant progress in text generation and translation. Thanks to a well-trained algorithm: predict words based on nearby context.
#Notably, activation from these models has been shown to map linearly to brain responses to speech and text.
# Furthermore, this mapping depends primarily on the algorithm's ability to predict future words, thus suggesting that this goal is sufficient for them to converge to brain-like computations.
#However, a gap still exists between these algorithms and the brain: despite large amounts of training data, current language models fail at generating long stories, summarizing, and Challenges with coherent conversation and information retrieval.
#Because the algorithm cannot capture some syntactic structures and semantic properties, and the understanding of the language is also very superficial.
#For example, the algorithm tends to incorrectly assign verbs to subjects in nested phrases.
「the keys that the man holds ARE here」
Similarly, when the text When generating predictions optimized only for the next word, deep language models can generate bland, incoherent sequences, or get stuck in loops that repeat endlessly. Currently, predictive coding theory provides a potential explanation for this flaw: Although deep language models are mainly used to Predicting the next word, but this framework shows that the human brain can predict at multiple time scales and cortical levels of representation. Previous research has demonstrated that speech prediction in the brain, that is, a word or phoneme, correlates well with functional magnetic resonance imaging ( fMRI), electroencephalography, magnetoencephalography and electrocorticography were correlated. #A model trained to predict the next word or phoneme can have its output reduced to a single number, the probability of the next symbol. # However, the nature and time scale of predictive representations are largely unknown. #In this study, the researchers extracted fMRI signals from 304 people and had each person listen to them for about 26 minutes short story (Y), and input the same content to activate the language algorithm (X). Then, the similarity between X and Y is quantified by the "brain score", that is, the Pearson correlation coefficient (R) after the best linear mapping W . #To test whether adding representations of predicted words improves this correlation, change the activation of the network (black rectangle X ) is connected to the prediction window (colored rectangle ~X), and then uses PCA to reduce the dimension of the prediction window to the dimension of X. Finally F quantifies the brain score gain obtained by enhancing the activation of this prediction window by the language algorithm. We repeat this analysis (d) with different distance windows. #It was found that this brain mapping could be improved by augmenting these algorithms with predictions that span multiple time scales, namely long-range predictions and hierarchical predictions. #Finally, the experimental results found that these predictions are hierarchically organized: the frontal cortex predicts higher levels, greater scope, and more predictions than the temporal cortex. Contextual representation. Deep language model maps to brain activity Researchers quantitatively studied the similarity between deep language models and the brain when the input content is the same. Using the Narratives dataset, the fMRI (functional magnetic resonance imaging) of 304 people who listened to short stories was analyzed. Perform independent linear ridge regression on the results for each voxel and each experimental individual to predict the fMRI signal resulting from activation of several deep language models . Using the held-out data, the corresponding "brain score" was calculated, that is, the correlation between the fMRI signal and the ridge regression prediction result obtained by inputting the specified language model stimulus sex. For clarity, first focus on the activations of the eighth layer of GPT-2, a 12-layer causal deep neural network powered by HuggingFace2 that is the most predictive Brain activity. Consistent with previous studies, GPT-2 activation accurately mapped to a distributed set of bilateral brain regions, with brain scores peaking in the auditory cortex and anterior and superior temporal regions. The Meta team then tested Does increasing stimulation of language models with long-range prediction capabilities lead to higher brain scores. #For each word, the researchers connected the model activation for the current word to a "prediction window" consisting of future words. The representation parameters of the prediction window include d, which represents the distance between the current word and the last future word in the window, and w, which represents the number of concatenated words. For each d, compare the brain scores with and without the predictive representation and calculate the “prediction score”. The results show that the prediction score is the highest when d=8, and the peak value appears in the brain area related to language processing. d=8 corresponds to 3.15 seconds of audio, which is the time of two consecutive fMRI scans. Prediction scores were distributed bilaterally in the brain, except in the inferior frontal and supramarginal gyri. Through supplementary analysis, the team also obtained the following results: (1) Each future word with a distance of 0 to 10 from the current word has a significant contribution to the prediction result. ; (2) Predictive representations are best captured with a window size of around 8 words; (3) Random predictive representations cannot improve brain scores; (4) Compared to real future words, GPT-2 generated words can achieve similar results results, but with lower scores. The predicted time frame changes along the layers of the brain Anatomy & Functional studies have shown that the cerebral cortex is hierarchical. Are the prediction time windows the same for different levels of cortex? #The researchers estimated the peak prediction score of each voxel and expressed its corresponding distance as d. The results showed that the d corresponding to the predicted peak in the prefrontal area was larger than that in the temporal lobe area on average (Figure 2e), and the d of the inferior temporal gyrus It is larger than the superior temporal sulcus. The variation of the best prediction distance along the temporal-parietal-frontal axis is basically symmetrical in both hemispheres of the brain . For each word and its preceding context, ten possible future words that match the syntax of a true future word. For each possible future word, the corresponding GPT-2 activation is extracted and averaged. This approach is able to decompose a given language model activation into syntactic and semantic components, thereby calculating their respective prediction scores. The results show that semantic prediction is long-range (d = 8), involving a distributed network, in front Peaks were reached in the lobe and parietal lobes, while syntactic prediction was shorter in scope (d = 5) and concentrated in superior temporal and left frontal regions. These results reveal multiple levels of prediction in the brain, in which the superior temporal cortex mainly predicts short-term, superficial and syntactic representations, while the inferior frontal and parietal regions mainly predict long-term, contextual, high-level and syntactic representations. Semantic representation. The predicted background becomes more complex along the brain hierarchy Still as before The method calculates the prediction score, but changes the use of GPT-2 layers to determine k for each voxel, the depth at which the prediction score is maximized. # Our results show that the optimal prediction depth varies along the expected cortical hierarchy, with the best model predicting deeper in associative cortex than in lower-level language areas . Differences between regions, although small on average, are very noticeable in different individuals. In general, long-term predictions in the frontal cortex have a more complex background than short-term predictions in lower-level brain areas. The level is higher. Adjust GPT-2 to a predictive encoding structure Adjust the current word and future words of GPT-2 The representations can be concatenated to obtain a better model of brain activity, especially in the frontal area. Can fine-tuning GPT-2 to predict representations at greater distances, with richer backgrounds, and higher levels of hierarchy improve brain mapping of these regions? In the adjustment, not only language modeling is used, but also high-level and long-distance targets are used. The high-level targets here are pre-trained GPT -Layer 8 of the 2 model. The results showed that fine-tuning GPT-2 with high-level and long-range modeling pairs best improved frontal lobe responses, while auditory area and lower-level of brain regions did not significantly benefit from such high-level targeting, further reflecting the role of frontal regions in predicting long-range, contextual, and high-level representations of language. Reference: https:/ /www.php.cn/link/7eab47bf3a57db8e440e5a788467c37f



Experimental results








The above is the detailed content of Brain hierarchical prediction makes large models more efficient!. For more information, please follow other related articles on the PHP Chinese website!

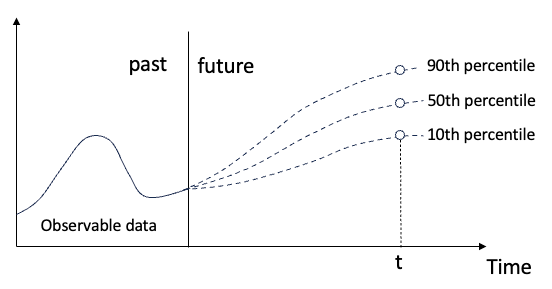 用于时间序列概率预测的分位数回归May 07, 2024 pm 05:04 PM
用于时间序列概率预测的分位数回归May 07, 2024 pm 05:04 PM不要改变原内容的意思,微调内容,重写内容,不要续写。“分位数回归满足这一需求,提供具有量化机会的预测区间。它是一种统计技术,用于模拟预测变量与响应变量之间的关系,特别是当响应变量的条件分布命令人感兴趣时。与传统的回归方法不同,分位数回归侧重于估计响应变量变量的条件量值,而不是条件均值。”图(A):分位数回归分位数回归概念分位数回归是估计⼀组回归变量X与被解释变量Y的分位数之间线性关系的建模⽅法。现有的回归模型实际上是研究被解释变量与解释变量之间关系的一种方法。他们关注解释变量与被解释变量之间的关
 SIMPL:用于自动驾驶的简单高效的多智能体运动预测基准Feb 20, 2024 am 11:48 AM
SIMPL:用于自动驾驶的简单高效的多智能体运动预测基准Feb 20, 2024 am 11:48 AM原标题:SIMPL:ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving论文链接:https://arxiv.org/pdf/2402.02519.pdf代码链接:https://github.com/HKUST-Aerial-Robotics/SIMPL作者单位:香港科技大学大疆论文思路:本文提出了一种用于自动驾驶车辆的简单高效的运动预测基线(SIMPL)。与传统的以代理为中心(agent-cent
 如何使用MySQL数据库进行预测和预测分析?Jul 12, 2023 pm 08:43 PM
如何使用MySQL数据库进行预测和预测分析?Jul 12, 2023 pm 08:43 PM如何使用MySQL数据库进行预测和预测分析?概述:预测和预测分析在数据分析中扮演着重要角色。MySQL作为一种广泛使用的关系型数据库管理系统,也可以用于预测和预测分析任务。本文将介绍如何使用MySQL进行预测和预测分析,并提供相关的代码示例。数据准备:首先,我们需要准备相关的数据。假设我们要进行销售预测,我们需要具有销售数据的表。在MySQL中,我们可以使用
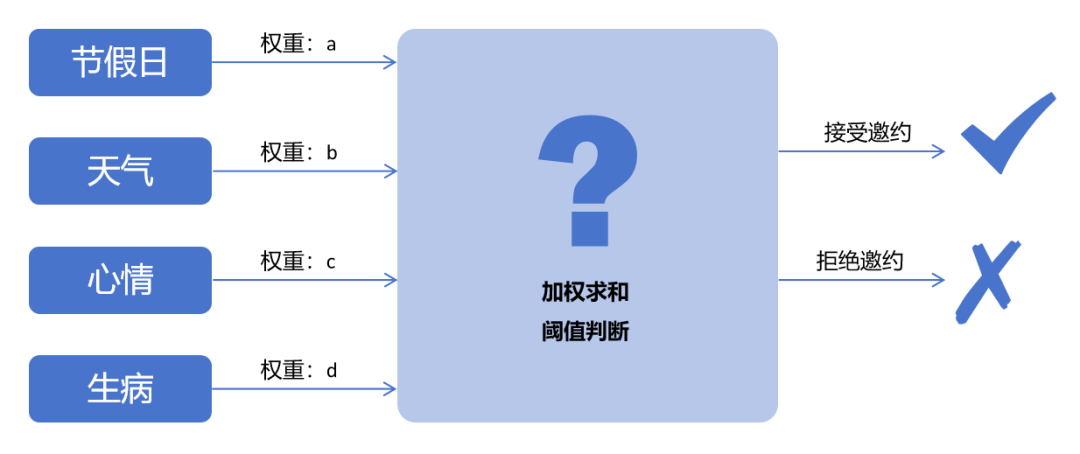 AI推理和训练有什么不同?你知道吗?Mar 26, 2024 pm 02:40 PM
AI推理和训练有什么不同?你知道吗?Mar 26, 2024 pm 02:40 PM如果要用一句话概括AI的训练和推理的不同之处,我觉得用“台上一分钟,台下十年功”最为贴切。小明和心仪已久的女神交往多年,对邀约她出门的技巧和心得颇有心得,但仍对其中的奥秘感到困惑。借助AI技术,能否实现精准预测呢?小明思考再三,总结出了可能影响女神是否接受邀请的变量:是否节假日,天气不好,太热/太冷了,心情不好,生病了,另有他约,家里来亲戚了......等等。图片将这些变量加权求和,如果大于某个阈值,女神必定接受邀约。那么,这些变量的都占多少权重,阈值又是多少呢?这是一个十分复杂的问题,很难通过
 跨模态占据性知识的学习:使用渲染辅助蒸馏技术的RadOccJan 25, 2024 am 11:36 AM
跨模态占据性知识的学习:使用渲染辅助蒸馏技术的RadOccJan 25, 2024 am 11:36 AM原标题:Radocc:LearningCross-ModalityOccupancyKnowledgethroughRenderingAssistedDistillation论文链接:https://arxiv.org/pdf/2312.11829.pdf作者单位:FNii,CUHK-ShenzhenSSE,CUHK-Shenzhen华为诺亚方舟实验室会议:AAAI2024论文思路:3D占用预测是一项新兴任务,旨在使用多视图图像估计3D场景的占用状态和语义。然而,由于缺乏几何先验,基于图像的场景
 Microsoft 365 在 Excel 中启用 PythonSep 22, 2023 pm 10:53 PM
Microsoft 365 在 Excel 中启用 PythonSep 22, 2023 pm 10:53 PM1、在Excel中启用PythonPythoninExcel目前处于测试阶段,如果要使用这个功能,请确保是Windows版的Microsoft365,并加入Microsoft365预览体验计划,选择Beta版频道。点击Excel页面左上角的【文件】>【账户】。在页面左边可以找到以下信息:以上步骤完成后,打开空白工作薄:单击【公式】选项卡,选择【插入Python】-【Excel中的Python】。在弹出的对话框里单击【试用预览版】。接下来,我们就可以开始体验Python的妙用啦!2、
 马斯克看好、OpenAI杀入,特斯拉的长期价值是机器人?May 27, 2023 pm 02:51 PM
马斯克看好、OpenAI杀入,特斯拉的长期价值是机器人?May 27, 2023 pm 02:51 PM科技狂人马斯克和他的特斯拉一直走在全球技术创新的前沿。日前,在特斯拉2023年股东大会上,马斯克再次披露有关未来发展的更多宏伟计划,包括汽车、储能、人形机器人。对于人形机器人马斯克似乎十分看好,并认为未来特斯拉的长期价值或在机器人。值得一提的是,ChatGPT母公司OpenAI也投资了一家挪威机器人公司,意在打造首款商用机器人EVE。Optimus和EVE的竞逐也引发了国内二级市场人形机器人概念热,受概念推动,人形机器人产业链哪些环节将受益?投资标的有哪些?布局汽车、储能、人形机器人作为全球科技
 如何使用Java实现一个简单的学生考试成绩预测系统?Nov 04, 2023 am 08:44 AM
如何使用Java实现一个简单的学生考试成绩预测系统?Nov 04, 2023 am 08:44 AM如何使用Java实现一个简单的学生考试成绩预测系统?随着教育的发展,学生的考试成绩一直被视为衡量学生学习成果的重要指标之一。然而,对于学生而言,了解自己的考试成绩预测是一种非常有用的工具,可以让他们了解自己在接下来的考试中的表现,并制定相应的学习策略。本文将介绍如何使用Java实现一个简单的学生考试成绩预测系统。首先,我们需要收集学生的历史考试成绩数据。我们


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

Atom editor mac version download
The most popular open source editor

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

