

 Technology peripheralsAIMemory reduction by 3%-7%! Google proposes machine learning framework MLGO for compiler optimization
Technology peripheralsAIMemory reduction by 3%-7%! Google proposes machine learning framework MLGO for compiler optimizationMemory reduction by 3%-7%! Google proposes machine learning framework MLGO for compiler optimization

With the birth of modern computers, the problem of how to compile faster and smaller code emerged.
Compilation optimization is the optimization method with the highest cost-benefit ratio. Better code optimization can significantly reduce the operating costs of large data center applications. Compiled code size is critical for mobile and embedded systems or software deployed on a secure boot partition, as compiled binaries must meet strict code size budgets. As the field advances, increasingly complex heuristics severely squeeze the limited system space, hindering maintenance and further improvements.
Recent research shows that machine learning can unlock more opportunities in compiler optimization by replacing complex heuristics with machine learning strategies. However, adopting machine learning strategies in general-purpose, industry-grade compilers remains a challenge.
In order to solve this problem, two senior engineers at Google, Qian Yundi and Mircea Trofin, proposed "MLGO, a machine learning-guided compiler optimization framework", which is the first industrial A universal framework for systematically integrating machine learning techniques into LLVM, an open source industrial compiler infrastructure ubiquitous in building mission-critical, high-performance software.

##Paper address: https://arxiv.org/pdf/2101.04808.pdf
MLGO uses reinforcement learning to train neural networks to make decisions, replacing heuristic algorithms in LLVM. According to the author's description, there are two MLGO optimizations on LLVM:
1) Reduce the amount of code through inlining;
2) Through register allocation Improve code performance.
Both optimizations are available in the LLVM repository and have been deployed in production.
1 How does MLGO work?Inlining helps reduce code size by making decisions that remove redundant code. In the following example, the caller function foo()<span style="font-size: 15px;"></span> calls the callee function bar()<span style="font-size: 15px;"></span>, and bar()<span style="font-size: 15px;"></span> itself calls baz()<span style="font-size: 15px;"></span>. Inlining these two call sites will return a simple foo()<span style="font-size: 15px;"></span> function, which will reduce code size.
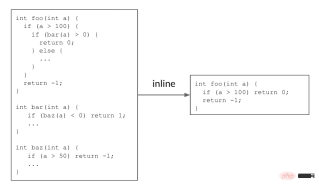
Caption: Inlining reduces code size by removing redundant code
In actual code, there are thousands of functions calling each other, thus forming a call graph. During the inlining phase, the compiler traverses the call graph of all caller-callee pairs and decides whether to inline a caller-callee pair. This is a continuous decision-making process, because previous inlining decisions will change the call graph, affecting subsequent decisions and the final result. In the above example, the call graph <span style="font-size: 15px;">foo()</span> → <span style="font-size: 15px;">bar()</span> → <span style="font-size: 15px;">baz()</span>Need to make a "yes" decision on both sides to Reduce code size.
Before MLGO, inline/non-inline decisions were made by heuristics that became increasingly difficult to improve over time. MLGO replaces heuristics with a machine learning model. During the traversal of the call graph, the compiler seeks the neural network's recommendation on whether to inline a specific caller-callee pair via relevant features (i.e., inputs) in the input graph, and executes the decisions sequentially until the entire Until the call graph is reached.

Legend: Illustration of MLGO during the inlining process, "# bbs", "# users" and "callsite height" is an instance of the caller-callee pair feature
MLGO performs RL training of decision networks using policy gradient and evolutionary policy algorithms. While there is no ground truth about optimal decisions, online RL uses a trained policy iterating between training and running assembly to collect data and improve the policy. In particular, given the model currently in training, the compiler consults the model during the inlining phase to make an inline/not inline decision. After compilation, it produces a log of the sequential decision process (status, action, reward). This log is then passed to the trainer to update the model. This process is repeated until a satisfactory model is obtained.

Note: Compiler behavior during training——The compiler compiles the source code foo.cpp into object file foo.o, and performed a series of optimizations, one of which was the inline channel.
The trained policy is embedded into the compiler, providing inline/non-inline decisions during the compilation process. Unlike the training scenario, this strategy does not generate logs. TensorFlow models are embedded in XLA AOT, which converts the model into executable code. This avoids TensorFlow runtime dependencies and overhead, minimizing the additional time and memory costs introduced by ML model inference at compile time.

Caption: Compiler behavior in production environment
We The size inline strategy was trained on a large in-house package containing 30k modules. The trained strategy can be generalized when compiling other software, and reduces time and memory overhead by 3% ~ 7%. In addition to generality across software, generality across time is also important. Both software and compilers are actively developed, so a well-trained strategy is needed to maintain good performance in a reasonable amount of time. We evaluated the model's performance on the same set of software after three months and found only slight degradation.

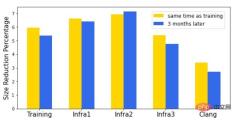
Legend: Inline size policy size reduction percentage, x-axis represents different software, y-axis represents the percentage reduction. "Training" is the software that trains the model, and "InfraX" is a different internal software package.
MLGO’s inline resize training has been deployed on Fuchsia, a general-purpose open source operating system designed to power a diverse hardware and software ecosystem, Where binary size is key. Here, MLGO shows a 6.3% reduction in C translation unit size.
2 Register Allocation
As a general framework, we use MLGO to improve the register allocation (Register allocation) channel to improve code performance in LLVM. Register allocation solves the problem of allocating physical registers to active scopes (i.e. variables).
As the code is executed, different live ranges are completed at different times, and the registers are released for use in subsequent processing stages. In the following example, each "add" and "multiply" instruction requires that all operands and results are in physical registers. Real-time range x is assigned to the green register and completes before the real-time range of the blue or yellow register. After x completes, the green register becomes available and assigned to live range t.
During code execution, different live ranges are completed at different times, and the released registers are used in subsequent processing stages. In the example below, each "add" and "multiply" instruction requires that all operands and results be in physical registers. The active range x is assigned to the green register and completes before the live range of the blue or yellow register. After x completes, the green register becomes available and is assigned to the live range t .

Legend: Register allocation example
When allocating active range q When , there are no registers available, so the register allocation channel must decide which active range can be "evicted" from its registers to make room for q. This is called the "field eviction" problem, and is where we train the model to replace the decision of the original heuristic. In this example, it evicts z from the yellow register and assigns it to q and the first half of z.
We now consider the unallocated lower half of the actual range z. We have another conflict, this time the active range t is evicted and split, the first half of t and the last part of z end up using the green register. The middle part of Z corresponds to the instruction q = t * y, where z is not used, so it is not allocated to any register, and its value is stored in the stack from the yellow register and is later reloaded into the green register. The same thing happens with t. This adds extra load/store instructions to the code and reduces performance. The goal of the register allocation algorithm is to minimize this inefficiency. This is used as a reward to guide RL policy training.
Similar to the inline size strategy, the register allocation (regalloc-for-Performance) strategy was trained on a large software package within Google and can be used universally across different software. Queries per second (QPS) increased by 0.3% ~ 1.5% on a set of internal large data center applications. Improvements in QPS persisted for several months after deployment, demonstrating the generalizability of the model.
3 Summary
MLGO uses reinforcement learning to train neural networks to make decisions. It is a machine learning strategy that replaces complex heuristic methods. As a general industrial-grade framework it will be deeper and more widely used in more environments, not just inlining and register allocation.
MLGO can be developed into: 1) deeper, such as adding more features and applying better RL algorithms; 2) broader, can be applied to inlining and redistribution More optimization heuristics beyond.
The authors are enthusiastic about the possibilities that MLGO can bring to the field of compiler optimization and look forward to its further adoption and future contributions from the research community.
The above is the detailed content of Memory reduction by 3%-7%! Google proposes machine learning framework MLGO for compiler optimization. For more information, please follow other related articles on the PHP Chinese website!

 What is Graph of Thought in Prompt EngineeringApr 13, 2025 am 11:53 AM
What is Graph of Thought in Prompt EngineeringApr 13, 2025 am 11:53 AMIntroduction In prompt engineering, “Graph of Thought” refers to a novel approach that uses graph theory to structure and guide AI’s reasoning process. Unlike traditional methods, which often involve linear s
 Optimize Your Organisation's Email Marketing with GenAI AgentsApr 13, 2025 am 11:44 AM
Optimize Your Organisation's Email Marketing with GenAI AgentsApr 13, 2025 am 11:44 AMIntroduction Congratulations! You run a successful business. Through your web pages, social media campaigns, webinars, conferences, free resources, and other sources, you collect 5000 email IDs daily. The next obvious step is
 Real-Time App Performance Monitoring with Apache PinotApr 13, 2025 am 11:40 AM
Real-Time App Performance Monitoring with Apache PinotApr 13, 2025 am 11:40 AMIntroduction In today’s fast-paced software development environment, ensuring optimal application performance is crucial. Monitoring real-time metrics such as response times, error rates, and resource utilization can help main
 ChatGPT Hits 1 Billion Users? 'Doubled In Just Weeks' Says OpenAI CEOApr 13, 2025 am 11:23 AM
ChatGPT Hits 1 Billion Users? 'Doubled In Just Weeks' Says OpenAI CEOApr 13, 2025 am 11:23 AM“How many users do you have?” he prodded. “I think the last time we said was 500 million weekly actives, and it is growing very rapidly,” replied Altman. “You told me that it like doubled in just a few weeks,” Anderson continued. “I said that priv
 Pixtral-12B: Mistral AI's First Multimodal Model - Analytics VidhyaApr 13, 2025 am 11:20 AM
Pixtral-12B: Mistral AI's First Multimodal Model - Analytics VidhyaApr 13, 2025 am 11:20 AMIntroduction Mistral has released its very first multimodal model, namely the Pixtral-12B-2409. This model is built upon Mistral’s 12 Billion parameter, Nemo 12B. What sets this model apart? It can now take both images and tex
 Agentic Frameworks for Generative AI Applications - Analytics VidhyaApr 13, 2025 am 11:13 AM
Agentic Frameworks for Generative AI Applications - Analytics VidhyaApr 13, 2025 am 11:13 AMImagine having an AI-powered assistant that not only responds to your queries but also autonomously gathers information, executes tasks, and even handles multiple types of data—text, images, and code. Sounds futuristic? In this a
 Applications of Generative AI in the Financial SectorApr 13, 2025 am 11:12 AM
Applications of Generative AI in the Financial SectorApr 13, 2025 am 11:12 AMIntroduction The finance industry is the cornerstone of any country’s development, as it drives economic growth by facilitating efficient transactions and credit availability. The ease with which transactions occur and credit
 Guide to Online Learning and Passive-Aggressive AlgorithmsApr 13, 2025 am 11:09 AM
Guide to Online Learning and Passive-Aggressive AlgorithmsApr 13, 2025 am 11:09 AMIntroduction Data is being generated at an unprecedented rate from sources such as social media, financial transactions, and e-commerce platforms. Handling this continuous stream of information is a challenge, but it offers an


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SublimeText3 Chinese version
Chinese version, very easy to use

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

Dreamweaver Mac version
Visual web development tools

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

