

 Technology peripheralsAIUniversity of Wisconsin-Madison and others jointly issued a post! The latest multi-modal large model LLaVA is released, and its level is close to GPT-4
Technology peripheralsAIUniversity of Wisconsin-Madison and others jointly issued a post! The latest multi-modal large model LLaVA is released, and its level is close to GPT-4
Visual command fine-tuning is popular.
This paper is called Visual Instruction Tuning and is jointly produced by the University of Wisconsin-Madison, Microsoft Research and Columbia University.
The authors include Haotian Liu, Chunyuan Li, Qingyang Wu and Yong Jae Lee.

At the same time, the researchers also open sourced their code, models and data sets on GitHub. The paper is also posted on Arxiv.
Explanation
So what exactly is the function of LLaVA? If you dive into the paper, it may be a bit strange to those who are not familiar with it.
Let’s first see what LLaVA itself says.
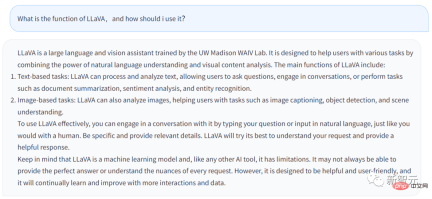
## The above answer is generated from LLaVA’s Chatbot. The question I entered is, what is the function of LLaVA and what should users do? Take advantage of it?
The answer is as follows:
LLaVA is a large language and visual assistant trained in the UW Madison WAIV laboratory. LLaVA is designed to help users handle various tasks by leveraging its natural language understanding capabilities and visual content analysis capabilities.
LLaVA’s main features include:
· Text-based tasks: LLaVA can process and analyze text , allowing users to ask questions, LLaVA can chat with users, or complete tasks entered by users, such as refining document summaries, sentiment analysis, entity recognition, etc.
· Image-based tasks: LLaVA can analyze images, describe images, perform object recognition, and analyze and understand scenes.
If users want to better apply LLaVA, they can directly talk to LLaVA, just like talking to humans. Provide as much detail as possible and LLaVA will generate a more complete answer.
At the same time, you should remember that after all, LLaVA is a machine learning model and an AI tool. As long as it is a tool, it has its limitations. LLaVA may not perfectly answer the questions entered by the user every time.
Of course, LLaVA is constantly learning and improving, and its functions will become more and more powerful.
In general, it can be seen from LLaVA’s answer that the functions of Chatbot are not much different from GPT. But LLaVA can handle some tasks related to images.
Exhibiting ColorThe researchers detailed the technical details of LLaVA in their Arxiv paper.
It is important to know that using machine-generated instructions to follow data to fine-tune instructions for large language models (LLMs) improves the zero-point capability of new tasks, but this idea is not explored in the multi-modal field. less.
In the paper, the researchers attempted for the first time to use language-only GPT-4 to generate instruction-following data for multi-modal language images.
By conditioning instructions on this generated data, the researchers introduce LLaVA: a large-scale language and vision assistant that is an end-to-end trained large-scale multi-modal Stateful model, which connects a visual encoder and LLM for general vision and language understanding.
Early experiments show that LLaVA demonstrates impressive multi-modal chat capabilities, sometimes outputting multi-modal GPT-4 performance on unseen images/commands, and on synthetic multi-modal chats. Compared with GPT-4 on the modal instruction following data set, it achieved a relative score of 85.1%.
When fine-tuned for Science Magazine, the synergy of LLaVA and GPT-4 achieved a new state-of-the-art accuracy of 92.53%.
Researchers have disclosed the data, models and code base for visual command adjustments generated by GPT-4.
Multimodal model
First clarify the definition.
Large-scale multimodal model refers to a model based on machine learning technology that can process and analyze multiple input types, such as text and images.
These models are designed to handle a wider range of tasks and are able to understand different forms of data. By taking text and images as input, these models improve their ability to understand and compile explanations to generate more accurate and relevant answers.
Humans interact with the world through multiple channels, including vision and language, because each individual channel has unique advantages in representing and conveying certain concepts of the world, thereby facilitating greater Understand the world well.
One of the core aspirations of artificial intelligence is to develop a universal assistant that can effectively follow multi-modal visual and language instructions, be consistent with human intentions, and complete various real-life tasks. World Mission.
As a result, the developer community has witnessed a renewed interest in developing language-enhanced basic vision models with powerful capabilities in open-world visual understanding such as classification, detection, segmentation, description, and visual generation and editing.
In these features, each task is independently solved by a single large visual model, with task instructions implicitly considered in the model design.
Furthermore, language is only used to describe image content. While this allows language to play an important role in mapping visual signals to linguistic semantics - a common channel for human communication. However, this results in models that often have fixed interfaces with limited interactivity and adaptability to user instructions.
And large language models (LLM) show that language can play a broader role: a common interface for a general assistant, various task instructions can be explicitly expressed in language, and guide the end to The end-trained neural assistant switches to the task of interest to solve it.
For example, the recent success of ChatGPT and GPT-4 have demonstrated the ability of this LLM to follow human instructions and stimulated huge interest in developing open source LLM.
LLaMA is an open source LLM whose performance is equivalent to GPT-3. Ongoing work leverages various machine-generated high-quality instruction following samples to improve LLM's alignment capabilities, reporting impressive performance compared to proprietary LLMs. Importantly, this line of work is text-only.
In this paper, researchers propose visual command tuning, which is the first attempt to extend command tuning into a multimodal space and paves the way for building a universal visual assistant. the way. Specifically, the main contents of the paper include:
Multimodal instruction following data. A key challenge is the lack of visual language instructions to follow the data. We present a data reform perspective and pipeline that uses ChatGPT/GPT-4 to convert image-text pairs into appropriate command-following formats.
Large multi-modal model. The researchers developed a large multimodal model (LMM) by connecting CLIP's open-set visual encoder and language decoder LaMA, and fine-tuned them end-to-end on the generated instructional visual-verbal data. Empirical studies verify the effectiveness of LMM instruction tuning using generated data and provide practical suggestions for building a general instruction-following visual agent. With GPT 4, the research team achieved state-of-the-art performance on the Science QA multi-modal inference dataset.
Open source. The research team released the following to the public: the generated multimodal instruction data, a code library for data generation and model training, model checkpoints, and a visual chat demonstration.
Result Display

It can be seen that LLaVA can handle all kinds of problems, and the answers generated are both comprehensive and logical.
LLaVA shows some multi-modal capabilities close to the level of GPT-4, with a GPT-4 relative score of 85% in terms of visual chat.
In terms of reasoning question and answer, LLaVA even reached the new SoTA-92.53%, defeating the multi-modal thinking chain.
The above is the detailed content of University of Wisconsin-Madison and others jointly issued a post! The latest multi-modal large model LLaVA is released, and its level is close to GPT-4. For more information, please follow other related articles on the PHP Chinese website!

 从VAE到扩散模型:一文解读以文生图新范式Apr 08, 2023 pm 08:41 PM
从VAE到扩散模型:一文解读以文生图新范式Apr 08, 2023 pm 08:41 PM1 前言在发布DALL·E的15个月后,OpenAI在今年春天带了续作DALL·E 2,以其更加惊艳的效果和丰富的可玩性迅速占领了各大AI社区的头条。近年来,随着生成对抗网络(GAN)、变分自编码器(VAE)、扩散模型(Diffusion models)的出现,深度学习已向世人展现其强大的图像生成能力;加上GPT-3、BERT等NLP模型的成功,人类正逐步打破文本和图像的信息界限。在DALL·E 2中,只需输入简单的文本(prompt),它就可以生成多张1024*1024的高清图像。这些图像甚至
 找不到中文语音预训练模型?中文版 Wav2vec 2.0和HuBERT来了Apr 08, 2023 pm 06:21 PM
找不到中文语音预训练模型?中文版 Wav2vec 2.0和HuBERT来了Apr 08, 2023 pm 06:21 PMWav2vec 2.0 [1],HuBERT [2] 和 WavLM [3] 等语音预训练模型,通过在多达上万小时的无标注语音数据(如 Libri-light )上的自监督学习,显著提升了自动语音识别(Automatic Speech Recognition, ASR),语音合成(Text-to-speech, TTS)和语音转换(Voice Conversation,VC)等语音下游任务的性能。然而这些模型都没有公开的中文版本,不便于应用在中文语音研究场景。 WenetSpeech [4] 是
 普林斯顿陈丹琦:如何让「大模型」变小Apr 08, 2023 pm 04:01 PM
普林斯顿陈丹琦:如何让「大模型」变小Apr 08, 2023 pm 04:01 PM“Making large models smaller”这是很多语言模型研究人员的学术追求,针对大模型昂贵的环境和训练成本,陈丹琦在智源大会青源学术年会上做了题为“Making large models smaller”的特邀报告。报告中重点提及了基于记忆增强的TRIME算法和基于粗细粒度联合剪枝和逐层蒸馏的CofiPruning算法。前者能够在不改变模型结构的基础上兼顾语言模型困惑度和检索速度方面的优势;而后者可以在保证下游任务准确度的同时实现更快的处理速度,具有更小的模型结构。陈丹琦 普
 解锁CNN和Transformer正确结合方法,字节跳动提出有效的下一代视觉TransformerApr 09, 2023 pm 02:01 PM
解锁CNN和Transformer正确结合方法,字节跳动提出有效的下一代视觉TransformerApr 09, 2023 pm 02:01 PM由于复杂的注意力机制和模型设计,大多数现有的视觉 Transformer(ViT)在现实的工业部署场景中不能像卷积神经网络(CNN)那样高效地执行。这就带来了一个问题:视觉神经网络能否像 CNN 一样快速推断并像 ViT 一样强大?近期一些工作试图设计 CNN-Transformer 混合架构来解决这个问题,但这些工作的整体性能远不能令人满意。基于此,来自字节跳动的研究者提出了一种能在现实工业场景中有效部署的下一代视觉 Transformer——Next-ViT。从延迟 / 准确性权衡的角度看,
 Stable Diffusion XL 现已推出—有什么新功能,你知道吗?Apr 07, 2023 pm 11:21 PM
Stable Diffusion XL 现已推出—有什么新功能,你知道吗?Apr 07, 2023 pm 11:21 PM3月27号,Stability AI的创始人兼首席执行官Emad Mostaque在一条推文中宣布,Stable Diffusion XL 现已可用于公开测试。以下是一些事项:“XL”不是这个新的AI模型的官方名称。一旦发布稳定性AI公司的官方公告,名称将会更改。与先前版本相比,图像质量有所提高与先前版本相比,图像生成速度大大加快。示例图像让我们看看新旧AI模型在结果上的差异。Prompt: Luxury sports car with aerodynamic curves, shot in a
 什么是Transformer机器学习模型?Apr 08, 2023 pm 06:31 PM
什么是Transformer机器学习模型?Apr 08, 2023 pm 06:31 PM译者 | 李睿审校 | 孙淑娟近年来, Transformer 机器学习模型已经成为深度学习和深度神经网络技术进步的主要亮点之一。它主要用于自然语言处理中的高级应用。谷歌正在使用它来增强其搜索引擎结果。OpenAI 使用 Transformer 创建了著名的 GPT-2和 GPT-3模型。自从2017年首次亮相以来,Transformer 架构不断发展并扩展到多种不同的变体,从语言任务扩展到其他领域。它们已被用于时间序列预测。它们是 DeepMind 的蛋白质结构预测模型 AlphaFold
 五年后AI所需算力超100万倍!十二家机构联合发表88页长文:「智能计算」是解药Apr 09, 2023 pm 07:01 PM
五年后AI所需算力超100万倍!十二家机构联合发表88页长文:「智能计算」是解药Apr 09, 2023 pm 07:01 PM人工智能就是一个「拼财力」的行业,如果没有高性能计算设备,别说开发基础模型,就连微调模型都做不到。但如果只靠拼硬件,单靠当前计算性能的发展速度,迟早有一天无法满足日益膨胀的需求,所以还需要配套的软件来协调统筹计算能力,这时候就需要用到「智能计算」技术。最近,来自之江实验室、中国工程院、国防科技大学、浙江大学等多达十二个国内外研究机构共同发表了一篇论文,首次对智能计算领域进行了全面的调研,涵盖了理论基础、智能与计算的技术融合、重要应用、挑战和未来前景。论文链接:https://spj.scien
 AI模型告诉你,为啥巴西最可能在今年夺冠!曾精准预测前两届冠军Apr 09, 2023 pm 01:51 PM
AI模型告诉你,为啥巴西最可能在今年夺冠!曾精准预测前两届冠军Apr 09, 2023 pm 01:51 PM说起2010年南非世界杯的最大网红,一定非「章鱼保罗」莫属!这只位于德国海洋生物中心的神奇章鱼,不仅成功预测了德国队全部七场比赛的结果,还顺利地选出了最终的总冠军西班牙队。不幸的是,保罗已经永远地离开了我们,但它的「遗产」却在人们预测足球比赛结果的尝试中持续存在。在艾伦图灵研究所(The Alan Turing Institute),随着2022年卡塔尔世界杯的持续进行,三位研究员Nick Barlow、Jack Roberts和Ryan Chan决定用一种AI算法预测今年的冠军归属。预测模型图


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SublimeText3 Chinese version
Chinese version, very easy to use

Dreamweaver Mac version
Visual web development tools

WebStorm Mac version
Useful JavaScript development tools

Notepad++7.3.1
Easy-to-use and free code editor

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

