

 Technology peripheralsAIDAMO-YOLO: an efficient target detection framework that takes into account both speed and accuracy
Technology peripheralsAIDAMO-YOLO: an efficient target detection framework that takes into account both speed and accuracy

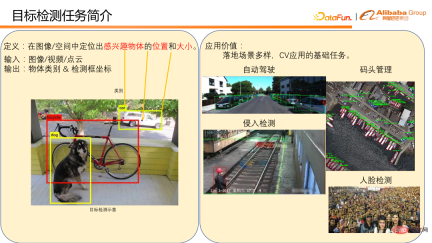
1. Introduction to target detection
The definition of target detection is to locate objects of interest in the image/space location and size.
# Generally, input an image, video or point cloud, and output the object category and detection frame coordinates. The picture on the lower left is an example of object detection on an image. There are many application scenarios for target detection, such as vehicle and pedestrian detection in autonomous driving scenarios, and berthing detection in dock management. Both of these are direct applications to object detection. Target detection is also a basic task for many CV applications, such as intrusion detection and face recognition used in factories. These require pedestrian detection and face detection as the basis to complete the detection task. It can be seen that target detection has many important applications in daily life, and its position in CV implementation is also very important, so this is a field with fierce competition.
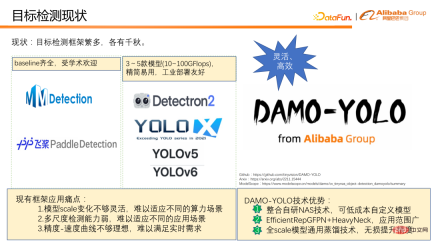
There are currently many target detection frameworks with their own characteristics. Based on our accumulated experience in actual use, we found that the current detection framework still has the following pain points in practical application:
① Insufficient change in model scale Flexible and difficult to adapt to different computing power scenarios. For example, the detection framework of the YOLO series generally only provides the calculation amount of 3-5 models, ranging from a dozen to more than a hundred Flops, making it difficult to cover different computing power scenarios.
② The multi-scale detection capability is weak, especially the small object detection performance is poor, which makes the model application scenarios very limited. For example, in drone detection scenarios, their results are often not ideal.
③ The speed/accuracy curve is not ideal enough, and speed and accuracy are difficult to be compatible at the same time.
In response to the above situation, we designed and open sourced DAMO-YOLO. DAMO-YOLO mainly focuses on industrial implementation. Compared with other target detection frameworks, it has three obvious technical advantages:
① It integrates self-developed NAS technology and can customize models at low cost, allowing users to fully utilize the chip computing power. .
② Combining Efficient RepGFPN and HeavyNeck model design paradigms can greatly improve the multi-scale detection capabilities of the model and expand the scope of model application.
#③ Proposed a full-scale universal distillation technology that can painlessly improve the accuracy of small, medium and large models.
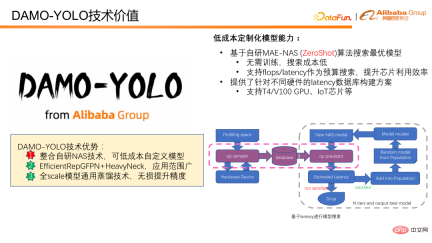
Below we will further analyze DAMO-YOLO from the value of 3 technical advantages.
2. DAMO-YOLO technical value
DAMO-YOLO realizes low-cost model customization based on its own The developed MAE-NAS algorithm. Models can be customized at low cost based on latency or FLOPS budget. It does not require model training or the participation of real data to provide model evaluation scores, and the model search cost is low. Targeting FLOPS can make full use of chip computing power. Searching with delay as the budget is very suitable for various scenarios that have strict requirements on delay. We also provide database construction solutions that support different hardware delay scenarios, making it easier for everyone to search using delay as a target.
The following figure shows how to use time delay for model search. First, sample the target chip or target device to obtain the delays of all possible operators, and then predict the delay of the model based on the delay data. If the predicted model magnitude meets the preset target, the model will enter subsequent model updates and score calculations. Finally, after iterative updating, the optimal model that meets the delay constraints is obtained.
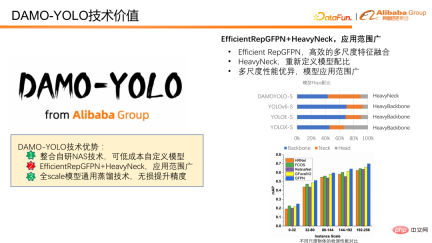
Next, we will introduce how to enhance the multi-scale detection capability of the model. DAMO-YOLO combines the proposed Efficient RepGFPN and the innovative HeavyNeck, which significantly improves multi-scale detection capabilities. Efficient RepGFPN can efficiently complete multi-scale feature fusion. The HeavyNeck paradigm refers to allocating a large number of FLOPS of the model to the feature fusion layer. Such as model FLOPS ratio table. Taking DAMO-YOLO-S as an example, the calculation amount of neck accounts for nearly half of the entire model, which is significantly different from other models that mainly place the calculation amount on the backbone.
Finally introduce the distillation model. Distillation refers to transferring the knowledge of a large model to a small model, improving the performance of the small model without incurring the burden of reasoning. Model distillation is a powerful tool to improve the efficiency of detection models, but exploration in academia and industry is mostly limited to large models, and there is a lack of distillation solutions for small models. DAMO-YOLO provides a set of distillations that are common to all-scale models. This solution can not only achieve significant improvements in full-scale models, but also has high robustness. It also uses dynamic weights without needing to adjust parameters, and distillation can be completed with one-click scripts. In addition, this scheme is also robust to heterogeneous distillation, which is of great significance for the low-cost custom model mentioned above. In the NAS model, the structural similarity between the small model and the large model obtained by search is not guaranteed. If there is a heterogeneously robust distillation, the advantages of NAS and distillation can be fully exploited. The figure below shows our performance on distillation. It can be seen that no matter on the T model, S model or M model, there is a stable improvement after distillation.

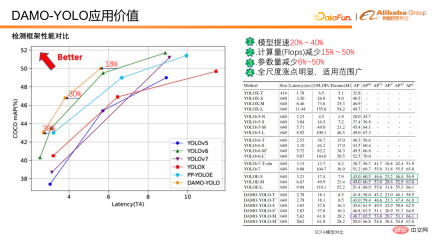
Based on the above technical value, how much application value can be converted? The following will introduce the comparison between DAMO-YOLO and other current SOTA detection frameworks.
DAMO-YOLO Compared with the current SOTA, the model speed is 20%-40% faster at the same accuracy, the calculation amount is reduced by 15%-50%, and the parameters are reduced by 6 %-50%, with obvious increase points in all scales and wide application range. In addition, there are obvious improvements on both small and large objects.
From the comparison of the above data, we can see that DAMO-YOLO is fast, has low Flops, and has a wide range of applications; it can also customize the model for computing power to improve the chip usage efficiency.
Relevant models have been launched on ModelScope. Inference and training can be performed through the configuration of three to five lines of code. You can experience the use. If you have any questions or problems during use, Comments are welcome in the comment area.
4. Introduction to the principle of DAMO-YOLO
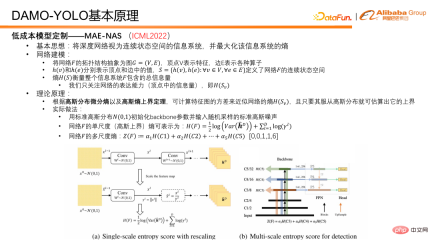
First introduce the key technology of low-cost model customization capability MAE-NAS. Its basic idea is to regard a deep network as an information system with a continuous state space and find the entropy that can maximize the information system.
The network modeling idea is as follows: abstract the topological structure of the network F into a graph G=(V,E), where the vertex V represents the feature and the edge E represents various operators. On this basis, h(v) and h(e) can be used to represent the values in vertices and edges respectively, and such a set S can be generated, which defines the continuous state space of the network, and the entropy of the set S can represent The total amount of information in the network or information system F. The information amount of the vertices measures the expressive ability of the network, and the information amount of the edges is also the entropy of the edges, which measures the complexity of the network. For the DAMO-YOLO object detection task, our main concern is to maximize the expressive ability of the network. In practical applications, only the entropy of network features is concerned. According to the Gaussian distribution differential entropy and the Gaussian entropy upper bound theorem, we use the variance of the feature map to approximate the upper bound of the network feature entropy.
In actual operation, we first initialize the weights of the network backbone with a standard Gaussian distribution, and use a standard Gaussian noise image as input. After the Gaussian noise is fed into the network for forward pass, several features can be obtained. Then the single-scale entropy, or variance, of each scale feature is calculated, and then multi-scale entropy is obtained by weighting. In the weighting process, a priori coefficients are used to balance the expressive capabilities of features at different scales. This parameter is generally set to [0,0,1,1,6]. The reason why this is set is as follows: Because in the detection model, the general features are divided into five stages, that is, five different resolutions, from 1/2 to 1/32. In order to maintain efficient feature utilization, we only utilize the last three stages. So in fact, the first two stages do not participate in the prediction of the model, so they are 0 and 0. For the other three, we have conducted extensive experiments and found that 1, 1, and 6 are a better model ratio.
Based on the above core principles, we can use the multi-scale entropy of the network as a performance proxy, Using the purification algorithm as the basic framework to search the network structure, this constitutes a complete MAE-NAS. NAS has many advantages. First of all, it supports multiple inference budget restrictions, and can use FLOPS, parameter amount, latency and network layer number to conduct a model search. Secondly, it also supports a very large number of variations in fine-grained network structures. Because evolutionary algorithms are used here to perform network searches, the more variants of network structures are supported, the higher the degree of customization and flexibility during search. In addition, in order to facilitate users to customize the search process, we provide official tutorials. Finally, and most importantly, MAE-NAS is zero-short, that is, its search does not require any actual data participation and does not require any actual model training. It searches for tens of minutes on the CPU and can produce an optimal network result under the current constraints.
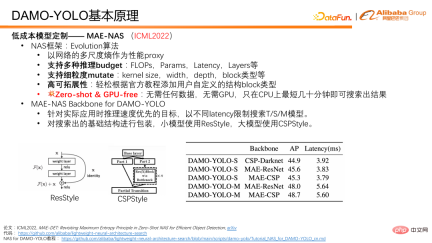
In DAMO-YOLO, we use MAE-NAS to search the backbone network of T/S/M model with different delays as search targets; The backbone network infrastructure is packaged, small models use ResStyle, and large models use CSPStyle.
As can be seen from the table below, CSP-Darknet is a manually designed network using the CSP structure. It has also achieved some results in YOLO v 5 /V6 Wide range of applications. We used MAE-NAS to generate a basic structure, and after packaging it with CSP, we found that the model was significantly improved in speed and accuracy. In addition, you can see the MAE-ResNet form on small models, which will have higher accuracy. There is a clear advantage in using the CPS structure on large models, which can reach 48.7.
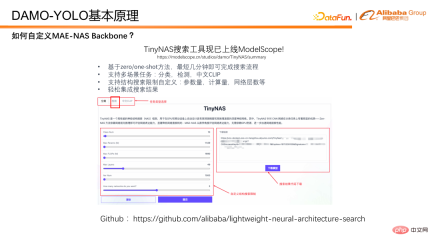
How to use MAE-NAS to search backbone? Here we introduce our TinyNAS toolbox, which is already online in ModelScope. You can easily get the desired model through visual configuration on the web page. At the same time, MAE-NAS has also been open sourced on github. Interested students can search for the desired model with greater freedom based on the open source code.
Next, we will introduce how DAMO-YOLO improves multi-scale detection capabilities, which relies on the fusion of different scale features of the network. In previous detection networks, the depth of features at different scales varies greatly. For example, large-resolution features are used to detect small objects, but their feature depth is shallow, which will affect the small object detection performance.
A work we proposed at ICLR2022 - GFPN, processes high-level semantic information and low-level spatial information at the same time with the same priority, and is very friendly to the fusion and complementation of multi-scale features. In the design of GFPN, we first introduced a skip layer in order to enable GFPN to be designed deeper. We use a log2n-link to reuse features and reduce redundancy.
Queen fusion is to increase the interactive fusion of features of different scales and features of different depths. In addition to receiving different scale features diagonally above and below it, each node in Queen fusion also receives different scale features at the same feature depth, which greatly increases the amount of information during feature fusion and promotes multi-scale information at the same depth. fusion on.
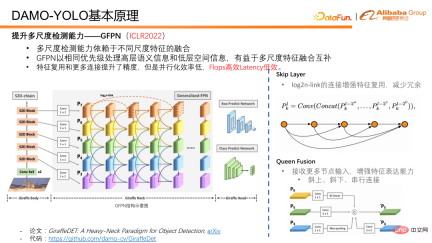
Although GFPN’s feature reuse and unique connection design have brought improvements in model accuracy. Since our skip layer and our Queen fusion bring fusion operations on multi-scale feature nodes, as well as upsampling and downsampling operations, they greatly increase the time-consuming inference and make it difficult to meet the implementation requirements of the industry. So in fact, GFPN is a FLOPS efficient, but delay inefficient structure. In view of some defects of GFPN, we analyzed and attributed the reasons as follows:
① First of all, features of different scales actually share the number of channels, and there are many Features are redundant and network configuration is not flexible enough.
② Second, there are upsampling and downsampling connections in the Queen feature, and the time consumption of the upsampling and downsampling operators is significantly improved.
③ Third, when nodes are stacked, serial connections at the same feature depth reduce the parallel efficiency of the GPU, and each stack brings The growth of serial paths has been significant.
#To address these problems, we have made corresponding optimizations and proposed Efficient RepGFPN.
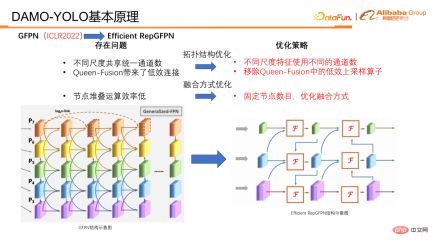
##In optimization, it is mainly divided into two categories. One is the optimization of topology structure. , the other category is the optimization of fusion methods.
In terms of topology optimization, Efficient RepGFPN uses different channel numbers for different scale features, so that it can flexibly control high-level features and low-level features under the constraints of lightweight calculations. expressive ability. In the case of FLOPS and delay approximation, flexible configuration can achieve the best accuracy and speed efficiency. In addition, we also conducted an efficiency analysis on a connection in queen fusion and found that the upsampling operator has a huge burden, but the accuracy improvement is small, which is far lower than the benefit of the downsampling operator. So we removed the upsampling connection in the queen fusion. As can be seen in the table, the ticks diagonally downward are actually upsampling, and the ticks diagonally upward are downsampling. You can compare it with the picture on the left to see that small resolutions gradually become larger resolutions downwards, and the connections to the lower right represent The purpose is to upsample small-resolution features, connect them to large-resolution features, and fuse them into large-resolution features. The final conclusion is that the downsampling operator has higher returns, while the upsampling operator has very low returns, so we removed the upsampling connection in the Queen feature to improve the efficiency of the entire GFPN.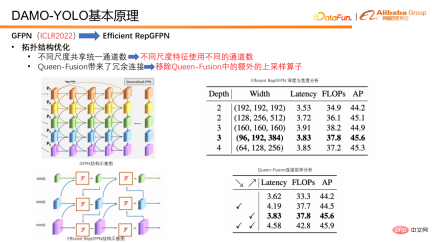
In terms of integration methods, we have also made some optimizations. First, fix the number of fusion nodes so that only two fusions are performed in each model instead of continuously stacking fusions to create a deeper GFPN as before. This avoids the parallel efficiency caused by the continuous growth of serial links. reduce. In addition, we specially designed a fusion block for feature fusion. In fusion block, we introduce technologies such as heavy parameterization mechanism and multi-layer aggregation connection to further improve the fusion effect.
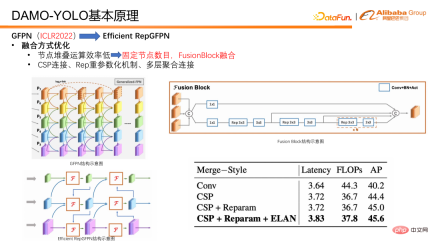
In addition to Neck, the detection head Head is also an important part of the detection model. It takes the features output by Neck as input and is responsible for outputting regression and classification results. We designed experiments to verify the trade off between Efficient RepGFPN and Head, and found that when the model latency is strictly controlled, the deeper the Efficient RepGFPN, the better. Therefore, in the network design, the calculation amount is mainly allocated to Efficient RepGFPN, while only one layer of linear projection is reserved in the Head part for classification and regression tasks. We call the Head that has only one layer of classification and one layer of regression non-linear mapping layer ZeroHead. A design pattern that allocates this computational load mainly to Neck is called the HeavyNeck paradigm.
The final model structure of DAMO-YOLO is shown in the figure below.
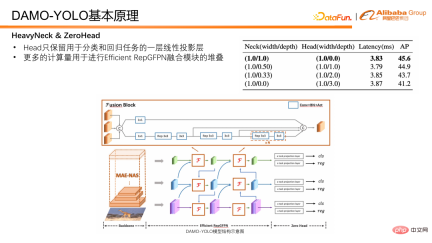
The above are some thoughts on in model design. Finally, let’s introduce the distillation scheme.
Take the output features of Efficient RepGFPN from DAMO-YOLO for distillation. The student feature will first pass through the alignmodule to align its channel number to the teacher. In order to remove the bias of the model itself, the features of the student and teacher will be normalized by unbiased BN, and then the distillation loss calculation will be performed. During distillation, we observed that excessive loss will hinder the convergence of the student's own classification branch. So we chose to use a dynamic weight that decays with training. From the experimental results, the dynamic uniform distillation weight is robust to T/S/M models.
The distillation chain of DAMO-YOLO is, L distillation M, M distillation S. It is worth mentioning that when M distills S, M uses CSP packaging, while S uses Res packaging. Structurally speaking, M and S are isomers. However, when using the DAMO-YOLO distillation scheme, M distills S, there can also be an improvement of 1.2 points after distillation, indicating that our distillation scheme is also robust to isomerism. So in summary, DAMO-YOLO’s distillation scheme has free parameters, supports a full range of models, and is heterogeneous and robust.
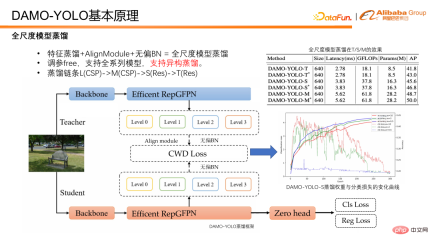
##Finally, let’s summarize DAMO-YOLO . DAMO-YOLO combines MAE-NAS technology to enable low-cost model customization and fully utilizes chip computing power. Combined with Efficient RepGFPN and HeavyNeck paradigms, it improves multi-scale detection capabilities and has a wide range of model applications. With the full-scale distillation scheme, it can Further improve model efficiency.

5. DAMO-YOLO Development Plan
DAMO-YOLO has just been released, and there are still many things that need to be improved and improved Optimization place. We plan to improve the deployment tools and support ModelScope in the short term. In addition, more application examples will be provided based on the competition champion solutions within the group, such as UAV small target detection and rotating target detection. It is also planned to launch more example models, including the Nano model for the device and the Large model for the cloud. Finally, I hope everyone will pay attention and provide positive feedback.
The above is the detailed content of DAMO-YOLO: an efficient target detection framework that takes into account both speed and accuracy. For more information, please follow other related articles on the PHP Chinese website!

 特斯拉自动驾驶算法和模型解读Apr 11, 2023 pm 12:04 PM
特斯拉自动驾驶算法和模型解读Apr 11, 2023 pm 12:04 PM特斯拉是一个典型的AI公司,过去一年训练了75000个神经网络,意味着每8分钟就要出一个新的模型,共有281个模型用到了特斯拉的车上。接下来我们分几个方面来解读特斯拉FSD的算法和模型进展。01 感知 Occupancy Network特斯拉今年在感知方面的一个重点技术是Occupancy Network (占据网络)。研究机器人技术的同学肯定对occupancy grid不会陌生,occupancy表示空间中每个3D体素(voxel)是否被占据,可以是0/1二元表示,也可以是[0, 1]之间的
 基于因果森林算法的决策定位应用Apr 08, 2023 am 11:21 AM
基于因果森林算法的决策定位应用Apr 08, 2023 am 11:21 AM译者 | 朱先忠审校 | 孙淑娟在我之前的博客中,我们已经了解了如何使用因果树来评估政策的异质处理效应。如果你还没有阅读过,我建议你在阅读本文前先读一遍,因为我们在本文中认为你已经了解了此文中的部分与本文相关的内容。为什么是异质处理效应(HTE:heterogenous treatment effects)呢?首先,对异质处理效应的估计允许我们根据它们的预期结果(疾病、公司收入、客户满意度等)选择提供处理(药物、广告、产品等)的用户(患者、用户、客户等)。换句话说,估计HTE有助于我
 Mango:基于Python环境的贝叶斯优化新方法Apr 08, 2023 pm 12:44 PM
Mango:基于Python环境的贝叶斯优化新方法Apr 08, 2023 pm 12:44 PM译者 | 朱先忠审校 | 孙淑娟引言模型超参数(或模型设置)的优化可能是训练机器学习算法中最重要的一步,因为它可以找到最小化模型损失函数的最佳参数。这一步对于构建不易过拟合的泛化模型也是必不可少的。优化模型超参数的最著名技术是穷举网格搜索和随机网格搜索。在第一种方法中,搜索空间被定义为跨越每个模型超参数的域的网格。通过在网格的每个点上训练模型来获得最优超参数。尽管网格搜索非常容易实现,但它在计算上变得昂贵,尤其是当要优化的变量数量很大时。另一方面,随机网格搜索是一种更快的优化方法,可以提供更好的
 因果推断主要技术思想与方法总结Apr 12, 2023 am 08:10 AM
因果推断主要技术思想与方法总结Apr 12, 2023 am 08:10 AM导读:因果推断是数据科学的一个重要分支,在互联网和工业界的产品迭代、算法和激励策略的评估中都扮演者重要的角色,结合数据、实验或者统计计量模型来计算新的改变带来的收益,是决策制定的基础。然而,因果推断并不是一件简单的事情。首先,在日常生活中,人们常常把相关和因果混为一谈。相关往往代表着两个变量具有同时增长或者降低的趋势,但是因果意味着我们想要知道对一个变量施加改变的时候会发生什么样的结果,或者说我们期望得到反事实的结果,如果过去做了不一样的动作,未来是否会发生改变?然而难点在于,反事实的数据往往是
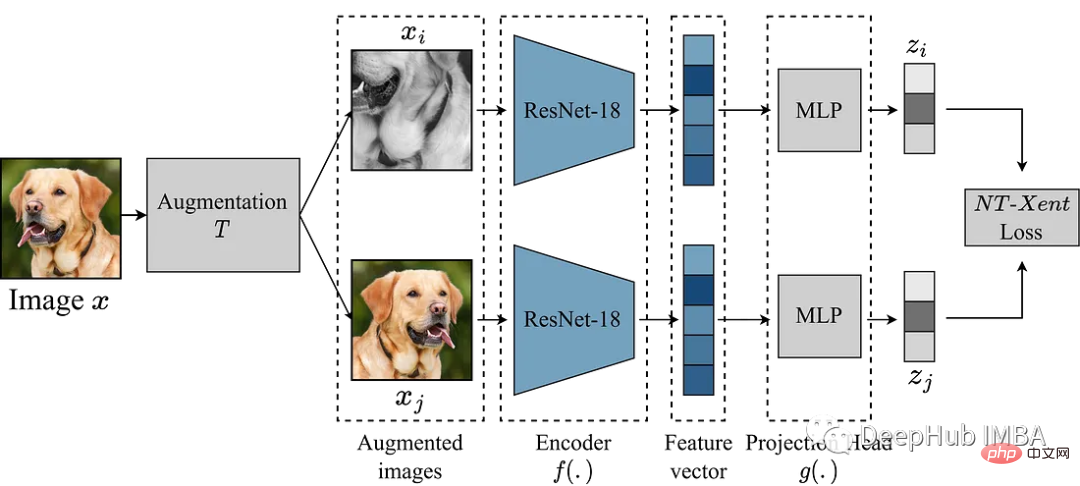 使用Pytorch实现对比学习SimCLR 进行自监督预训练Apr 10, 2023 pm 02:11 PM
使用Pytorch实现对比学习SimCLR 进行自监督预训练Apr 10, 2023 pm 02:11 PMSimCLR(Simple Framework for Contrastive Learning of Representations)是一种学习图像表示的自监督技术。 与传统的监督学习方法不同,SimCLR 不依赖标记数据来学习有用的表示。 它利用对比学习框架来学习一组有用的特征,这些特征可以从未标记的图像中捕获高级语义信息。SimCLR 已被证明在各种图像分类基准上优于最先进的无监督学习方法。 并且它学习到的表示可以很容易地转移到下游任务,例如对象检测、语义分割和小样本学习,只需在较小的标记
 盒马供应链算法实战Apr 10, 2023 pm 09:11 PM
盒马供应链算法实战Apr 10, 2023 pm 09:11 PM一、盒马供应链介绍1、盒马商业模式盒马是一个技术创新的公司,更是一个消费驱动的公司,回归消费者价值:买的到、买的好、买的方便、买的放心、买的开心。盒马包含盒马鲜生、X 会员店、盒马超云、盒马邻里等多种业务模式,其中最核心的商业模式是线上线下一体化,最快 30 分钟到家的 O2O(即盒马鲜生)模式。2、盒马经营品类介绍盒马精选全球品质商品,追求极致新鲜;结合品类特点和消费者购物体验预期,为不同品类选择最为高效的经营模式。盒马生鲜的销售占比达 60%~70%,是最核心的品类,该品类的特点是用户预期时
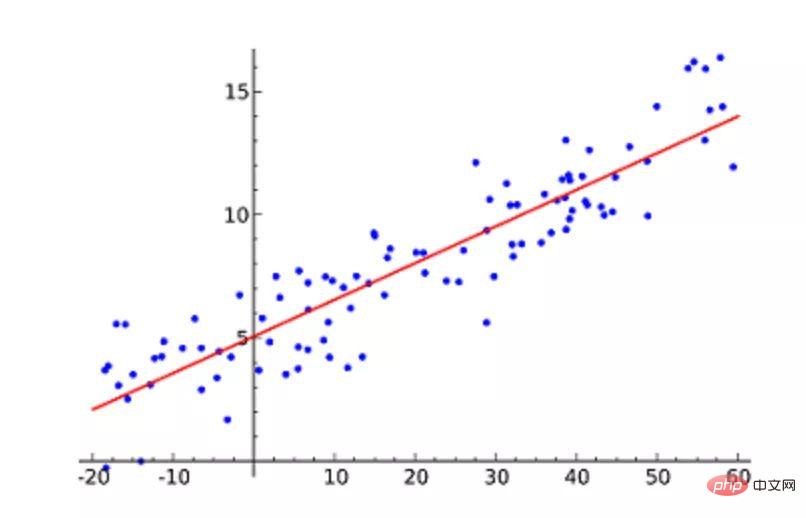 机器学习必知必会十大算法!Apr 12, 2023 am 09:34 AM
机器学习必知必会十大算法!Apr 12, 2023 am 09:34 AM1.线性回归线性回归(Linear Regression)可能是最流行的机器学习算法。线性回归就是要找一条直线,并且让这条直线尽可能地拟合散点图中的数据点。它试图通过将直线方程与该数据拟合来表示自变量(x 值)和数值结果(y 值)。然后就可以用这条线来预测未来的值!这种算法最常用的技术是最小二乘法(Least of squares)。这个方法计算出最佳拟合线,以使得与直线上每个数据点的垂直距离最小。总距离是所有数据点的垂直距离(绿线)的平方和。其思想是通过最小化这个平方误差或距离来拟合模型。例如
 人类反超 AI:DeepMind 用 AI 打破矩阵乘法计算速度 50 年记录一周后,数学家再次刷新Apr 11, 2023 pm 01:16 PM
人类反超 AI:DeepMind 用 AI 打破矩阵乘法计算速度 50 年记录一周后,数学家再次刷新Apr 11, 2023 pm 01:16 PM10 月 5 日,AlphaTensor 横空出世,DeepMind 宣布其解决了数学领域 50 年来一个悬而未决的数学算法问题,即矩阵乘法。AlphaTensor 成为首个用于为矩阵乘法等数学问题发现新颖、高效且可证明正确的算法的 AI 系统。论文《Discovering faster matrix multiplication algorithms with reinforcement learning》也登上了 Nature 封面。然而,AlphaTensor 的记录仅保持了一周,便被人类


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Dreamweaver CS6
Visual web development tools

Zend Studio 13.0.1
Powerful PHP integrated development environment

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

SublimeText3 English version
Recommended: Win version, supports code prompts!

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

