

 Technology peripheralsAIProfessor Wang Jun organized 7 AI scholars to discuss the theory and application of general artificial intelligence after ChatGPT
Technology peripheralsAIProfessor Wang Jun organized 7 AI scholars to discuss the theory and application of general artificial intelligence after ChatGPT
The popularity of ChatGPT has once again aroused people’s attention to artificial intelligence. So how will artificial intelligence develop after ChatGPT? The industry and OpenAI, the parent company of ChatGPT, believe that AGI will be the development direction of artificial intelligence in the future.
What aspects can AGI theoretical research and application practice start from? [ChatGPT and Large Model Spring Course] The last topic discussion answered this question. Scholars and experts from UCL, Renmin University of China, Huawei, Tsinghua, Chinese Academy of Sciences, Shanghai Jiao Tong University, Nanjing University, and University of Liverpool gathered together to discuss "General Artificial Intelligence after ChatGPT" Intelligence Theory and Applications”.

The following is a summary of the highlights of the roundtable discussion.
Topic 1: We have always longed for general artificial intelligence, without the need to design algorithms to train machines for tasks. Does ChatGPT bring us such a possibility? Is it possible to realize such a dream in recent years?
Liu Qun: At first, I was a little disgusted with the term "general artificial intelligence" because I understood that it was a comparison The sci-fi term seems unreliable. So I've been reluctant to answer questions about this concept before. But recently, it seems that this term is quite reasonable. It is not science fiction. Today's artificial intelligence models are becoming more and more general. In the past, they could only handle some small problems or a single problem. Now ChatGPT can basically handle all kinds of problems. I feel that the term general artificial intelligence is quite appropriate.
I don’t dare to judge whether general artificial intelligence will be realized, but to a certain extent, general natural language processing has been realized. In the field of natural language, it is very complicated to solve any small problem, such as machine translation, sentiment analysis, and Chinese word segmentation. It always involves everything, because words are texts and symbols. To do any small direction well, you must understand the entire language system. Therefore, ChatGPT’s language function implementation is very powerful, especially its discourse capability. Because discourse is a very deep and difficult problem in natural language. ChatGPT has learned very well the discourse structure in the human communication process, including the routines and vocabulary of writing articles. This is a very abstract way of logic and organization of articles. Some recent examples are that it can simulate human speech and assume a certain role. This is natural language processing with a nested structure. It is a stack, like ChatGPT, which switches topics. It is very good to jump in and out without making a mess.
Wang Jun: If you look at it from the perspective of machine learning, its objective equation is very simple. The first is to predict the next word from the previous words; Second, is the answer to this passage similar to that of a human being? These two very simple goals, why can he learn something that feels like it requires a lot of logic and design in advance?
Liu Qun: To achieve the goal, the complex knowledge used must be well involved. The better and deeper the knowledge is mastered, the better the prediction will be. So although the goal is simple, the means to achieve it can be infinitely complex. So to do it well, you need very powerful models and a lot of data.
Huang Minlie: In the past, people in China generally did not dare to talk about the concept of AGI, and even the definition of AGI was not clear. So we sometimes joke that Chinese scientists don’t dare to have dreams, because if they talk about AGI, they will be sprayed to death. Foreign scientists are indeed very sentimental. For example, a professor at MIT used an AI dialogue system to make a chat robot and a psychotherapy robot in 1966. I think this is a very difficult thing. They dare to think and do it, and it is worth learning from us.
Back to the question, how far are we from AGI now? I think it's still far away in a general sense. The level of intelligence that ChatGPT currently embodies is still in the process of developing AGI, but things that we don't dare to think about are already starting to take shape. So I think it might be better to put it another way: let’s not discuss whether it has the ability to achieve AGI in a broad sense, because in a broad sense, we may also have various independent thinking and generalization abilities. But what we see today is that its overall intelligence level is indeed beyond what any previous AI can achieve. Its technical route is also very different. The DeepQA technology developed by IBM Watson is completely traditional and classic. This understanding routine of semantic analysis is to analyze the grammar and syntactic structure of a sentence very clearly. It represents another school of academic thought.
But looking at it today, ChatGPT is not only about data, but also about the power of data and models, as well as the ability of the model itself to emerge. So I think it's the right path to AGI in the future? Different people have different opinions. I think it is a direction worth trying, but it is not the only direction. This is one of my main points: how it is learned is not entirely the violent aesthetics of data plus model. It still reflects the design of many model algorithms, especially the alignment with human data. Many details of OpenAI have not been disclosed, but I guess there is a lot of sophisticated data processing inside it. What you see now seems to be simply getting started with data, but in fact it may not be that simple.
Fang Meng: ChatGPT is indeed very powerful. Recently, I asked it to write code, and when I ran the code it wrote directly, I found a bug in it. I directly copied the bug information and let ChatGPT handle it, and it recommended a function and code to me. But this function has been deprecated in the version update. I quickly found its update based on the recommended function and solved my problem. I'm thinking, actually the average person doesn't learn to code specifically, but we need to communicate. And ChatGPT does handle many NLP tasks very well, almost considering most NLP tasks, and seems to be a universal AI. However, the model published by OpenAI is learned based on data before 2021 and cannot handle new knowledge. From a purely NLP perspective, it does seem to be an AGI model that can handle most NLP research problems. In the future, our scientific research on NLP will definitely create many new questions and explore new things. What if one day ChatGPT could do something similar, creating new problems on its own instead of dealing with existing ones. I believe this could be closer to general artificial intelligence in that it can generate new things on its own. I think the skills he has acquired now are still based on the massive data in the past. Its model training has large computing power and sophisticated engineering. But it may be just one way, and there may be other ways. So we can also explore other ways.
In addition, I am also thinking about another question, if we let it learn the data of 2022, how long do we need to train it? Is it possible to learn like a human being? Or is it better to learn faster? These may also be one of the key points of general artificial intelligence. The models currently in public use by OpenAI are not yet at this level, but they are indeed very powerful and this is an important step forward.
Topic 2: What are the shortcomings of ChatGPT? From a machine learning perspective, what aspects of it can be improved to get where we want it to be? Or what are the boundaries of its capabilities?
Wen Jirong: There are still some obvious shortcomings. First, ChatGPT's knowledge is not real-time enough. The language model learns both knowledge and capabilities from massive data. The two are unified and can be expressed like the human brain. However, this knowledge has been fixed during training, so there will be situations where new data after September 2021 is put in for learning. Adding new things requires retraining, which is very costly and is basically not feasible now. Therefore, ChatGPT and Bing are integrated to combine search results and content generation based on the latest network data. After combination, it may be possible to solve the problem of real-time and correctness of ChatGPT knowledge. But I personally think this matter is still at the beginning and is worthy of in-depth study. The data in the large model is static, and the entire Internet or external knowledge is dynamic. When using the model to generate results, how to combine the internal knowledge of the model with the external knowledge to generate results. There is no good answer to this question yet, but if it is done well, it will be of great significance. Because we can't always retrain the model, we need to have a stable base model that can be combined to complete the generation or inference work when more dynamic data or professional domain knowledge comes in. Second, I have been working on large multi-modal models for more than two years. As you can see, GPT-4 already has some multi-modal models, which is impressive. Moving forward, I think we need to further study how multiple modalities can work well together for generation and reasoning. This is something that still needs work. Third, I think the biggest problem with large models at present is that they are too expensive. It is said that only tens of billions and hundreds of billions of scale can have the ability to emerge. This matter has actually blocked the road of the scientific research community. If we don’t have a model of the scale of ChatGPT, will we not be able to do research? If we are unable to achieve relatively high capabilities or performance on moderate models in the future, our subsequent scientific research will be very difficult. The field of NLP has been greatly affected recently. In fact, information retrieval has also been greatly affected. It is meaningless to do traditional ranking work. Now that Bing is conversational search, conversational recommendations are coming soon. Before you know it, information retrieval may become information generation, and the field may need to be renamed. Now things are changing dramatically. It is hoped that there will be some breakthroughs in the research platform in the future. How to present the model capabilities of today's ChatGPT or GPT-4 on a limited-scale model is very important.
Wang Jun: I would like to insert one of the solutions. Open source in academia may be the only way to go. If a large model is open sourced, it may at least pre-train the model, and then we can adjust it, or we can do some scientific research in this direction. The industry comes up with the architecture, and open source drives its greater use. Here are a few questions for Teacher Li. Although ChatGPT still has some various flaws, what does Teacher Li think about the leap from studying the human brain to artificial intelligence? When will we reach the point where the so-called AI surpasses humans?
Li Chengyu: When I was listening to the lecture, what I thought about most was "evolution". Why? Because artificial intelligence started in the 1960s, it has evolved very rapidly and is an exponential evolution process. We just mentioned AGI. In fact, it already exists in the universe. AGI is in the human brain. It is a physical entity and a large network that can do many things, so people themselves have AGI. Our brain itself is a network with general capabilities, so in theory, whether it is a biological or artificial neural network, it can do many things. Because of the explosive exponential growth of artificial intelligence, revolutionary developments like GPT4 have emerged, which is analogous to the evolution of the human biological brain. The human brain has the largest number of brains in proportion to the body among all living creatures. Now the mouse brain has about 70 million neurons, the monkey brain has about 6 billion, and the human brain has about 80 billion to 100 billion. This is also an exponential growth. So from this perspective, the revolution in GPT evolution is very exciting. I personally see this as a very important opportunity, allowing those of us who do neuroscience and brain science to think about the relationship between biological brains and artificial brains.
In addition, from the perspective of brain mechanisms, I think there are a lot of interesting things to discuss. I just mentioned the problem that large models will not be able to perform continuous learning after the end of 2021. But our human brains are obviously capable of continuous learning, and we will not stop learning after a certain point in time. But what’s interesting is that there are some brain tissues and areas in our brain that control this ability. One example is the case of hippocampus H.M. After doctors removed the hippocampus of an epileptic patient, his long-term memory stopped at the moment of the operation, and he was unable to learn new facts after that. This example is somewhat similar to the problem we are discussing now. The continuous learning ability of large models may not be borrowed from biological brains, so I think this is an opportunity. Neuroscience should communicate more with you to see how to extract the mechanism of continuous learning ability of biological brains to help design new artificial intelligence neural networks. I think this is a process of co-evolution, and this process will also help us understand how the biological brain achieves continuous learning. We didn't think about this issue as important before, but I now think it's an important thing that allows us to continue to face new challenges.
We are currently doing map research. This is a very basic research. We need to understand what types of cells there are in the brain and how the cells are connected. There are still many challenges in the field of biological brain. I’m not sure about this question, but the connection between each neuron is very clear in the AI network. So in the current research process, we are working with research institutions such as BGI and Huazhong University of Science and Technology, and found that during the evolution of different species , the hippocampus of the six species has changed greatly, with many new types of neurons appearing and many new brain areas. Many new subregions have appeared in the hippocampus. We have studied turtles, birds, mice, monkeys, and humans. In this process, human behavioral abilities continue to increase. So I think the complexity and ability of this behavior corresponds to the emergence of new cells in the hippocampus. We are learning about these new cells.
I want to talk about what we can do in the future. I feel that there are a lot of things to do here. We are also changing the direction of our research. Now I think we can extract some principles from the research on mice and monkeys and apply them to the human brain, which can realize more complex functions with low power consumption. Although Ke Jie cannot beat AlphaGo in chess, Ke Jie only needs to eat a few breads and steamed buns every day. The energy consumption is extremely low, and the requirements for intelligent agents will also go in this direction, but artificial intelligence chat GPT cannot yet be solved. This problem requires learning from living organisms in the future to produce a physical intelligence with lower energy consumption.
In the future, we need to integrate perception, cognition and movement. Now this form is not very capable of controlling a robot to walk around, but I think in the future it may at least produce Solve the field of perception. We understand Chat GPT or GPT4 to solve cognitive problems, and in the future it will be connected to motion control. I know that many motion control robot hands and robotic arms based on transformers are constantly developing. If perception, cognition, and movement are integrated into one, each individual module can be integrated. Like everyone mentioned cross-field integration, I think this is a very important point in the future. In the process of the development of artificial intelligence, I hope that brain science can work with everyone to do more interesting things.
Wang Jun: I would like to ask Mr. Li. The human brain is so complex and has evolved for so many years, but the brain has no reward function and no inductive BIAS. But when we do machine learning, we must give it certain prior knowledge or assumptions. It cannot make any predictions without prior knowledge or assumptions. In machine learning, although we are talking about general artificial intelligence, we have not yet been able to remove these two premises. But looking at the human brain, does it have no reward mechanism and no prior knowledge? How can it generate the current wisdom? But current technology cannot achieve this. What does Teacher Li think? What do AI experts think? Are reward mechanisms and prior knowledge required?
Li Chengyu: Let me first introduce some ideas. First, as to whether there is a reward mechanism in the process of evolution, I think there is. More than 99% of all living things have become extinct. This extinction is punishment, but the existence of living things is reward. So from this point of view, species and individuals All have reward mechanisms. Everyone has rewards and punishments, and these processes can change the structure and function of our brains. Therefore, I think rewards must exist in biological evolution. The second is the BIAS you just mentioned. In fact, living organisms also have BIAS. Children are born with cognition, such as basic principles of physics such as things falling when they let go. We call it BIAS. This is in the brain. When we are born, the neural network has undergone long-term evolution, and there is a certain BIAS for the external physics and human social behavior in it, including interest in specific faces. Machine learning is different. It requires people to change their perspective from the outside and let artificial intelligence play chess with different agents. They will generate a different generation of their own, and the previous generation can be used as its BIAS. I think this seems to be inevitable. When an individual is always in a certain task state, I think it will move forward on a specific trajectory among competing species, and this trajectory is framed by physical entities. This framework must rely on its existing boundaries. Only with BIAS can it win faster.
Wang Jun: I would like to ask if AI has the ability to drive itself, when will it have a self-concept, evolve on its own, and even become conscious. This consciousness is unique to human beings. This phenomenon is currently being done by ChatGPT. Is it conscious and can it know other people's thoughts? But in fact, it just stays in the text list. Even on a text form, it doesn't necessarily capture this thing 100%. I don’t know what everyone thinks about this. If AGI doesn’t have self and consciousness, does it have a reward function? Is this given to it by the outside or can it generate it on its own?
Liu Qun: Let me explain a little bit about my understanding. Just now, Teacher Li said that survival is the ultimate reward. I strongly agree with this. In fact, the ultimate reward of human beings is survival, and all its purposes are to survive. But in our lives, I will feel that we are not doing everything to survive, but in fact these are all a kind of survival pressure that is eventually transformed into. Another form of expression is rewards. It doesn’t look like it’s about living, but actually it boils down to survival. So I believe that it is difficult for current AI to generate self-evolution because it has no pressure to survive. Suppose you put it in the wilderness and give it a limit on computing power. Unless you create an environment where it can compete on its own, maybe one day you will be able to take off other people's power cords and protect your own.
Li Chengyu: The problem of consciousness is obviously a very important but unsolved problem, but it is not impossible to study now. There are many interesting research methods in the field of consciousness. Given a weak visual stimulus, the experimenter reported that sometimes he could see it and sometimes he couldn't. It can be considered that the consciousness did not report that he could see it. At this time, there was a big difference in the activities in the brain. Perhaps this type of game can be used to test chatGPT or other artificial intelligence networks to test whether they have human-like consciousness performance. There are actually many debates in this field, and there are definitely no answers now. I think we can work together because we can do research in this area biologically. Give the monkey 50% visible and 50% invisible stimuli, see its brain activity, and compare it to the AI network.
Topic 3: Decision-making intelligence: Our current robot can see and read, but it cannot walk. How can we make it walk?
Yu Yang: ChatGPT or the recent outbreak of GPT, although I am in the field of reinforcement learning decision-making, I also feel very touched. In this field, some large-scale model research is also being conducted. But fortunately, there is no model that can replace or crush reinforcement learning. This also shows the fact that there is still a big gap between the existing GPT model and human biological intelligence. Specifically, ChatGPT lacks the world model part. There is no working memory in the current GPT model, only context and prompt input. In the study of reinforcement learning, we found that this context has a certain memory ability, that is, it can recognize and remember past actions, its results, and the reaction of the world. But this memory ability may not be strong, because it is only a linear sequence and there is no special place to store it. This is different from what Teacher Li mentioned before, that the hippocampus in living organisms is very important for our short-term memory. Recently we have also read papers on biology and found that there are many interesting contents. There is a very tight connection between the hippocampus and the world model, but this is not the case with the GPT model. GPT models don’t dream. We see that when a mouse dreams, its hippocampus replays what it encountered during the day, which is actually a very typical manifestation of the world model. The mouse's body wasn't moving, but its brain was. All the data it sees is replayed in its brain, and according to the visualization results, it is not arranged in chronological order, but in reverse order, from the end to the starting point. This is similar to the data replay in reinforcement learning. memory is very similar. Therefore, from this perspective, the current GPT model is not functionally complete enough. Simply put, it may still be just a so-called joint probability estimation model today. We see from the rat's hippocampus that when the rat faces a crossroads, its hippocampus will move left and right at the same time, which is one of the brain areas it needs for reasoning. The current GPT model is not yet at this level, so I believe that in order to make better decisions, the GPT model needs to be further optimized. If it hopes to make better-than-human decisions, it may need further improvements in the underlying structure.
Although today's large-scale models have a wide range of knowledge, large-scale models are still not fully mastered in many professional fields. In these fields, there is a lot of data that is not public or does not exist in language form. It may be commercial data or medical data, which is private data. So we're still going to see a lot of small data processing in these areas, small data isn't going away. I think this is a very important point. Their relationship, maybe large models can help us deal with overall problems, but for data analysis in small fields, especially those involving decision-making, we find that small data and closed data exist in many fields, so we cannot use large models to solve these problems. We believe that small models also deserve attention, especially as large models become better and better, and applications using small models in proprietary domains may receive more attention from researchers.
Zhang Weinan: I would like to say from the perspective of the feedback path, feedback is what Richard Sutton said in the frontier part of the textbook "Reinforcement Learning". As we are born, in fact, Constantly interacting with the environment, controlling and obtaining feedback from the perceived information, and constantly learning in this closed loop. For feedback, the chat in ChatGPT will actually get some answers, but it will also need a reward function. We don't actually have such a thing now, it's more of a state transfer. But in fact, the relevant reward part is not directly given in ChatGPT, so if you only train ChatGPT, in fact, except for the alignment of the last person in the loop, the other parts are supervised learning, that is, in most cases It hasn't learned in the form of feedback yet. It can be imagined that if ChatGPT is now used to call decision-making interfaces, such as ChatGPT for Robotics, it can be found that it is indeed connected to these interfaces to a certain extent and can make correct decisions, but this is only an extension of cognitive abilities. , and the reward can be maximized without adjusting the interface during the training process. If the feedback chain is closed, it will actually lead to the development of decision-making intelligence towards better performance. The most critical point is not necessarily a carefully designed reward function, but its ability to determine whether the decision-making task has been successfully completed. If the signal of success or failure of the decision-making task can be fed back to ChatGPT, this will actually form a closed loop to provide continuous feedback and complete the decision-making task completely spontaneously.
Q & A Session
Q1: From the perspective of the realization of multi-modal capabilities, Baidu Wenxin seems to be through Baidu text model, dialogue model and graphics and text, etc. The ability performs a kind of stitching. Could you please explain how to integrate scattered capabilities into a large multi-modal model? How does this differ from GPT4’s implementation of multimodal capabilities?
Zhang Weinan: First of all, I don’t know the design behind Wenxin, but I feel that it is very text-based. , calling API to achieve multi-modal interaction capabilities. If the Baidu Wenxin model is asked to generate a piece of speech, it may first generate text and then call the API to play it in a certain dialect. This is actually an extension capability, but the core is still the difference between a large language model and a true multi-modal large model. But this is just my conjecture, and it does not mean that Wen Xin’s real realization is like this.
#Q2: What will be the relationship between more mature large models and small models such as traditional machine learning and deep learning in the future?
Yu Yang: Although today’s large models have a wide range of knowledge, in many professional fields, large models are not yet able to Fully grasp. There are still many fields where the data is not public or the data is not language-based. It may be commercial data or medical data, which is private data. Therefore, in these fields, we may still see a lot of small data processing. The data doesn't disappear. I think this is a very important point, what will its relationship look like? Maybe large models can help us do overall things, but for data analysis in small fields, especially decision-making, we find that many fields are full of small data and closed data, so there is no way to use large models to solve it. Therefore, we think small models are also worthy of attention, especially when large models become very good, will more researchers pay attention to the application of small models in proprietary fields?
Q3: I would like to ask Mr. Liu, since ChatGPT is a generative model, fictitious news or paper citations often appear in practice. What do you think of this? phenomenon, and what do you think can be improved?
Liu Qun: In fact, the model itself cannot distinguish between facts and non-facts. By definition, it can be considered that something or judgment that appears in the pre-training data is a fact. If it does not appear, it is not a fact. But when the model is generated, it does not know that they have become model parameters. It is very common that some of the model parameters output are consistent with the pre-training data and some are not. So the model itself, it's indistinguishable. But this matter is not completely incapable of improvement. It can be seen that GPT4 has made practical improvements. This is through learning, minimizing non-facts, and finding facts. But I feel that simply using the existing neural network method of large models is not able to completely solve the problem. So we still need to explore some other methods and use external judgment to solve the problem. This question is a very good question.
Wang Jun: This question can actually be looked at the other way around. Why? Fiction can be a good thing, too. In some cases, it's asked to write a poem or composition, and hopefully it will have a science fiction element to it, so that makes the problem very difficult. Whether we want to find facts or construct ideas is indeed rather ambiguous, and we need a goal to achieve it.
Q4: As an excellent AI industry representative, will Huawei develop its own ChatGPT next? Based on the current business, what layout will be used in large models or multi-modal models?
Liu Qun: First of all, Huawei will definitely meet the challenge head-on. We also have a lot of accumulation in this area. I may be able to provide specific business planning and layout. It's hard to be too specific here, but you may have noticed that there was a speech by Mr. Ren, where he mentioned that someone asked Mr. Ren about ChatGPT. Mr. Ren said that ChatGPT should not only be seen as an NLP or visual problem. , In fact, its potential is very great, and the greater potential in the future may not be on the simple surface, it may be the combination of NLP vision or multi-modal problems. It may be used in Huawei's various businesses, and 80% of its applications will be in some businesses that people may not have imagined. I think the potential is very great. Huawei will definitely meet the challenges head-on and develop its own capabilities in this area.
#Q5: From a neuroscience perspective, what other directions can the ChatGPT system try to make more similar to human thinking feedback?
Li Chengyu: This is obviously a very good question. Brain science and internal medicine are very different, and everyone has very different opinions. I can only represent my personal opinion. I think general artificial intelligence may be a very important point in the future. If there is an entity standing next to me who looks similar to me and has similar intelligence to me, he can help me solve my problem. From this perspective, the current ChatGPT can take many forms. It can add some movement into it, and he needs continuous learning and he also needs to have some self-awareness. I think that with self-awareness, we can solve many of the fake news just mentioned. There is also the ethics mentioned just now. From the most fundamental source of data, there are ethical issues. Because there are more than 190 countries in the world, the culture of most countries is not reflected in ChatGPT. I think from an overall ethical perspective, we all need to think from a new perspective on how to build a fairer, more effective, and smarter intelligence. body. The questions asked by RLCN students actually include Inductive BIAS. I think Inductive BIAS is very important. This initial cognitive map is related to the intelligence, overall movement, and guidance I just mentioned. It is also important for survival.
Q6: Will the GPT large model subvert the existing machine learning research paradigm? In the post-big model era, is artificial intelligence theoretical research still important?
Liu Qun: Although I am not a theorist, I think theory is very important, but I have not imagined how theory can help us. Today’s AI does a much better job. But I hope that theory can help answer a question. We often talk about the emergence of large models, but there is nothing strange about the emergence itself. I think that when the model becomes larger, some new abilities will definitely emerge. Let alone large models, when normal children grow up, Having gained 10 times his original weight, his abilities must be different from before, so I think it is normal. But is there any theory that can accurately predict the size of the model and the size of the data required for various abilities to emerge? I really want to know about this, and to what extent can large models emerge with new capabilities?
Fang Meng: I think the possible future research direction is GPT. It shows strong logical inference ability. I would like to know how to prove that this is the real logic. Inference ability, rather than logical inference imitated after learning a lot of data. I'm also curious about how much data and how big a model is required to have logical inference capabilities. So I think we can have some empirical results, but we really need to do more research on the theoretical side if we're going to have the right answer.
Wen Jirong: I think this question is quite good. I think it can be studied. Now GPT4 or other large GPT models have shown so much knowledge. abilities, or human-like behavior. Will there be a science in the future, such as digital brain science? Because this model itself is the object of our research. I think studying large models is very meaningful in itself. What is discovered here can in turn have many important implications for future brain science or cognitive science.
Li Chengyu: I think this is a good question. You can ask GPT4. The reason is that Stan Dehaene said that there are two core qualities in consciousness. Choice Sexual processing and supervision, one is to have overall selective processing of input information, and the other is to monitor one's own consciousness. So from this perspective, can ChatGPT itself or its future descendants monitor its own behavior? This is something you can ask at the theoretical level, and you can also build a new framework or network structure to generate this capability. From this perspective, perhaps the theoretical framework can help build a new generation of artificial intelligence.
Wang Jun: Yes, it’s not just attention that knows the boundaries of capabilities. For example, where is the boundary of Transformer's current architectural capabilities? What can and cannot be done? Does it have working memory? Where are the boundaries of feedback function capabilities? Some things can emerge, and some things cannot. These indeed require a very solid theoretical foundation to study. There is also the prior knowledge of Inductive BIAS. First of all, the design of Transformer itself is a prior knowledge. Can it be done without prior knowledge? I think these issues are in great need of theoretical research. Without guidance, everyone will be a headless fly.
The above is the detailed content of Professor Wang Jun organized 7 AI scholars to discuss the theory and application of general artificial intelligence after ChatGPT. For more information, please follow other related articles on the PHP Chinese website!

 Windows 11 上的智能应用控制:如何打开或关闭它Jun 06, 2023 pm 11:10 PM
Windows 11 上的智能应用控制:如何打开或关闭它Jun 06, 2023 pm 11:10 PM智能应用控制是Windows11中非常有用的工具,可帮助保护你的电脑免受可能损害数据的未经授权的应用(如勒索软件或间谍软件)的侵害。本文将解释什么是智能应用控制、它是如何工作的,以及如何在Windows11中打开或关闭它。什么是Windows11中的智能应用控制?智能应用控制(SAC)是Windows1122H2更新中引入的一项新安全功能。它与MicrosoftDefender或第三方防病毒软件一起运行,以阻止可能不必要的应用,这些应用可能会减慢设备速度、显示意外广告或执行其他意外操作。智能应用
 一文聊聊SLAM技术在自动驾驶的应用Apr 09, 2023 pm 01:11 PM
一文聊聊SLAM技术在自动驾驶的应用Apr 09, 2023 pm 01:11 PM定位在自动驾驶中占据着不可替代的地位,而且未来有着可期的发展。目前自动驾驶中的定位都是依赖RTK配合高精地图,这给自动驾驶的落地增加了不少成本与难度。试想一下人类开车,并非需要知道自己的全局高精定位及周围的详细环境,有一条全局导航路径并配合车辆在该路径上的位置,也就足够了,而这里牵涉到的,便是SLAM领域的关键技术。什么是SLAMSLAM (Simultaneous Localization and Mapping),也称为CML (Concurrent Mapping and Localiza
 一文读懂智能汽车滑板底盘May 24, 2023 pm 12:01 PM
一文读懂智能汽车滑板底盘May 24, 2023 pm 12:01 PM01什么是滑板底盘所谓滑板式底盘,即将电池、电动传动系统、悬架、刹车等部件提前整合在底盘上,实现车身和底盘的分离,设计解耦。基于这类平台,车企可以大幅降低前期研发和测试成本,同时快速响应市场需求打造不同的车型。尤其是无人驾驶时代,车内的布局不再是以驾驶为中心,而是会注重空间属性,有了滑板式底盘,可以为上部车舱的开发提供更多的可能。如上图,当然我们看滑板底盘,不要上来就被「噢,就是非承载车身啊」的第一印象框住。当年没有电动车,所以没有几百公斤的电池包,没有能取消转向柱的线传转向系统,没有线传制动系
 智能网联汽车线控底盘技术深度解析May 02, 2023 am 11:28 AM
智能网联汽车线控底盘技术深度解析May 02, 2023 am 11:28 AM01线控技术认知线控技术(XbyWire),是将驾驶员的操作动作经过传感器转变成电信号来实现传递控制,替代传统机械系统或者液压系统,并由电信号直接控制执行机构以实现控制目的,基本原理如图1所示。该技术源于美国国家航空航天局(NationalAeronauticsandSpaceAdministration,NASA)1972年推出的线控飞行技术(FlybyWire)的飞机。其中,“X”就像数学方程中的未知数,代表汽车中传统上由机械或液压控制的各个部件及相关的操作。图1线控技术的基本原理
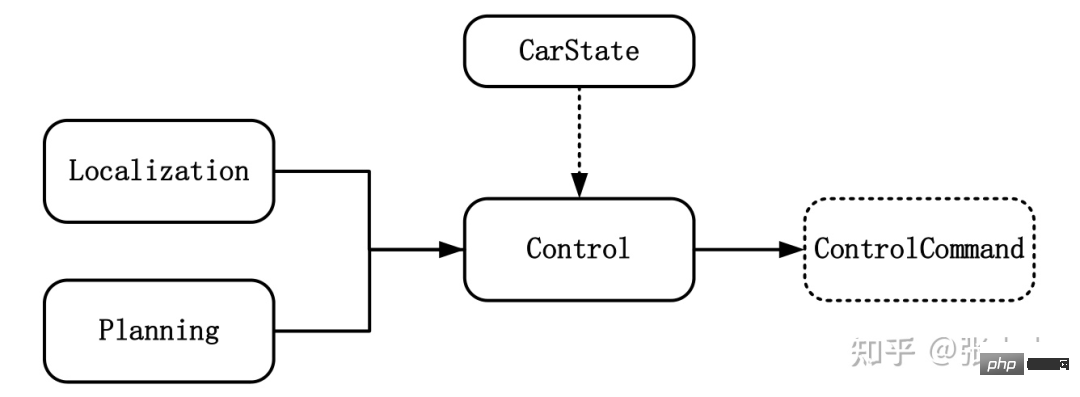 智能汽车规划控制常用控制方法详解Apr 11, 2023 pm 11:16 PM
智能汽车规划控制常用控制方法详解Apr 11, 2023 pm 11:16 PM控制是驱使车辆前行的策略。控制的目标是使用可行的控制量,最大限度地降低与目标轨迹的偏差、最大限度地提供乘客的舒适度等。如上图所示,与控制模块输入相关联的模块有规划模块、定位模块和车辆信息等。其中定位模块提供车辆的位置信息,规划模块提供目标轨迹信息,车辆信息则包括档位、速度、加速度等。控制输出量则为转向、加速和制动量。控制模块主要分为横向控制和纵向控制,根据耦合形式的不同可以分为独立和一体化两种方法。1 控制方法1.1 解耦控制所谓解耦控制,就是将横向和纵向控制方法独立分开进行控制。1.2 耦合控
 一文读懂智能汽车驾驶员监控系统Apr 11, 2023 pm 08:07 PM
一文读懂智能汽车驾驶员监控系统Apr 11, 2023 pm 08:07 PM驾驶员监控系统,缩写DMS,是英文Driver Monitor System的缩写,即驾驶员监控系统。主要是实现对驾驶员的身份识别、驾驶员疲劳驾驶以及危险行为的检测功能。福特DMS系统01 法规加持,DMS进入发展快车道在现阶段开始量产的L2-L3级自动驾驶中,其实都只有在特定条件下才可以实行,很多状况下需要驾驶员能及时接管车辆进行处置。因此,在驾驶员太信任自动驾驶而放弃或减弱对驾驶过程的掌控时可能会导致某些事故的发生。而DMS-驾驶员监控系统的引入可以有效减轻这一问题的出现。麦格纳DMS系统,
 李飞飞两位高徒联合指导:能看懂「多模态提示」的机器人,zero-shot性能提升2.9倍Apr 12, 2023 pm 08:37 PM
李飞飞两位高徒联合指导:能看懂「多模态提示」的机器人,zero-shot性能提升2.9倍Apr 12, 2023 pm 08:37 PM人工智能领域的下一个发展机会,有可能是给AI模型装上一个「身体」,与真实世界进行互动来学习。相比现有的自然语言处理、计算机视觉等在特定环境下执行的任务来说,开放领域的机器人技术显然更难。比如prompt-based学习可以让单个语言模型执行任意的自然语言处理任务,比如写代码、做文摘、问答,只需要修改prompt即可。但机器人技术中的任务规范种类更多,比如模仿单样本演示、遵照语言指示或者实现某一视觉目标,这些通常都被视为不同的任务,由专门训练后的模型来处理。最近来自英伟达、斯坦福大学、玛卡莱斯特学
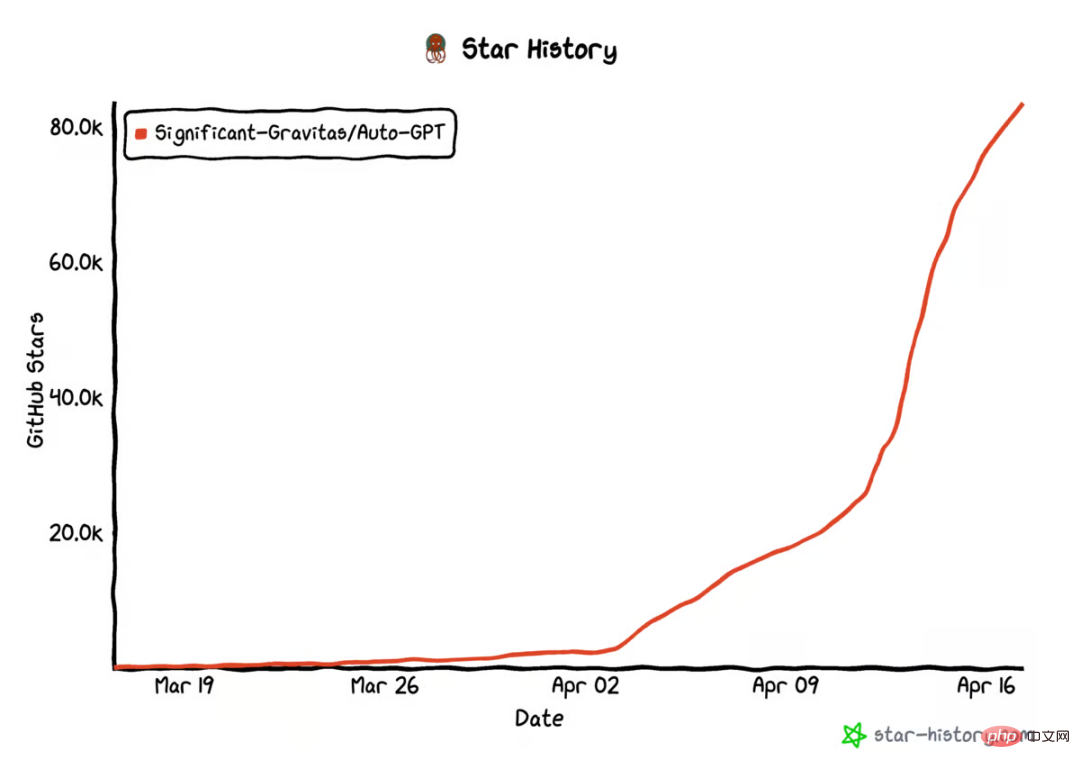 AutoGPT star量破10万,这是首篇系统介绍自主智能体的文章Apr 28, 2023 pm 04:10 PM
AutoGPT star量破10万,这是首篇系统介绍自主智能体的文章Apr 28, 2023 pm 04:10 PM在GitHub上,AutoGPT的star量已经破10万。这是一种新型人机交互方式:你不用告诉AI先做什么,再做什么,而是给它制定一个目标就好,哪怕像「创造世界上最好的冰淇淋」这样简单。类似的项目还有BabyAGI等等。这股自主智能体浪潮意味着什么?它们是怎么运行的?它们在未来会是什么样子?现阶段如何尝试这项新技术?在这篇文章中,OctaneAI首席执行官、联合创始人MattSchlicht进行了详细介绍。人工智能可以用来完成非常具体的任务,比如推荐内容、撰写文案、回答问题,甚至生成与现实生活无


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

SublimeText3 English version
Recommended: Win version, supports code prompts!

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

