



Detailed explanation of Redis Sentinel, Sentinel construction process, Sentinel operation process and election principle (subjective offline, objective offline, how to elect the Sentinel leader).

Redis Sentinel (sentinel)
What is a sentinel?
The whistleblower patrols and monitors whether the background master host is faulty. If it is faulty, it will automatically convert a slave database to a new master database based on the number of votes to continue external services. [Related recommendations: Redis video tutorial]
is commonly known as unattended operation and maintenance.
What to do?
- Master-slave monitoring: Monitor whether the master-slave redis library is running normally
- Message notification: Sentinel can send the failover results to the client
- Failover: Use one of the Slave as the new Master
- Configuration center: The client obtains the master node address of the current Redis service by connecting to the sentinel
Case
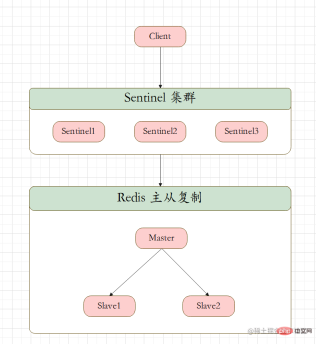
Architecture
3 Sentinels: Automatically monitor and maintain the cluster. It does not store data and is just a whistleblower.
1 Master 2 Slave : used to read and store data
Steps
-
Copy sentinel.conf in the redis installation path to the myredis directory
cp sentinel.conf /myredis/sentinel26379.conf
-
Modify the configuration file
vim sentinel26379.conf bind 0.0.0.0 # protected-mode yes 修改为 protected-mode no protected-mode no # daemonize no 修改为 daemonize yes daemonize yes # port port 26379 # pid文件名字,pidfile pidfile /var/run/redis_26379.pid # log文件名字,logfile(修改 logfile "" 为 logfile "/myredis/26379.log") logfile "/myredis/26379.log" # 指定当前的工作目录(修改 dir /temp 为 dir /myredis) dir /myredisSet the master server to be monitored
quorum: The minimum number of sentinels to confirm objective offline. Quorum of votes to approve failover.
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
Set the password to connect to the master service
# sentinel auth-pass <master-name> <password>
We know that the network is unreliable. Sometimes a sentinel will mistakenly think that it is a new one due to network congestion. Master redis is dead. In a sentinel cluster environment, multiple sentinels need to communicate with each other to confirm whether a master is really dead. The quorum parameter is a basis for objective offline, which means that at least quorum sentinels think this If the master fails, the master will be offline and failed over. Because sometimes, a sentinel node may be unable to connect to the master due to its own network reasons, but the master is not faulty at this time. Therefore, multiple sentinels need to agree that there is a problem with the master before proceeding to the next step. operation, which ensures fairness and high availability.
Install three linux
ip and port are
# sentinel00 192.168.157.112 26379 # sentinel01 192.168.157.113 26380 # sentinel02 192.168.157.118 26381
Configure three sentinels
sentinelxxxx.conf File
sentinel00
sentinel26379.conf
bind 0.0.0.0 daemonize yes protected-mode no port 26379 logfile "/myredis/sentinel26379.log" pidfile /var/run/redis-sentinel26379.pid dir /myredis sentinel monitor mymaster 192.168.157.115 6379 2 sentinel auth-pass mymaster 1234
sentinel01
sentinel26380.conf
bind 0.0.0.0 daemonize yes protected-mode no port 26380 logfile "/myredis/sentinel26380.log" pidfile /var/run/redis-sentinel26380.pid dir /myredis sentinel monitor mymaster 192.168.157.115 6379 2 sentinel auth-pass mymaster 1234
sentinel02
sentinel26381. conf
bind 0.0.0.0 daemonize yes protected-mode no port 26381 logfile "/myredis/sentinel26381.log" pidfile /var/run/redis-sentinel26381.pid dir /myredis sentinel monitor mymaster 192.168.157.115 6379 2 sentinel auth-pass mymaster 1234
Test
Based on the previous redis replication, start 1 master and 2 slaves to test whether the master-slave replication is normal, enter info replication to check whether it is normal
-
Start three sentries and complete monitoring
redis-sentinel /myredis/sentinel26379.conf --sentinel redis-sentinel /myredis/sentinel26380.conf --sentinel redis-sentinel /myredis/sentinel26381.conf --sentinel
Test master-slave replication, everything is fine
View log

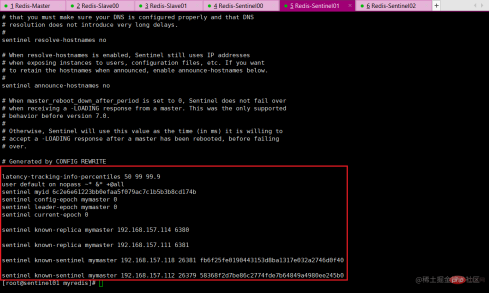
- ##View the configuration file sentinel.conf
> 后面为自动新增内容-Simulating master downtime
- master host
# 模拟宕机 shudown
Problem
- Is the data of the two slave machines normal? (yes)
- Will a new master be selected from the remaining two machines? (yes)
- Will the previous master take over again and become the master again after restarting? (no)
- salveGet data

- View new The master

- rewrite starts the original master and the master will not come back on.

file will be dynamically modified by sentinel during operation. After the master-slave master-slave relationship is switched, the content of the configuration file will automatically change.
- sentinel6379.conf file

- ##old master
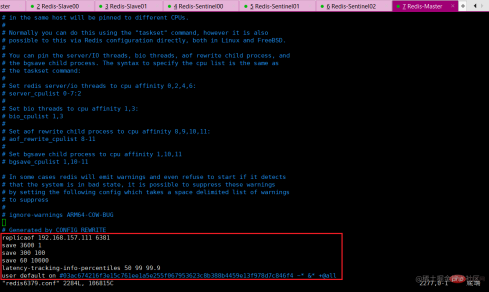
新master


哨兵运行流程和选举原理
当一个主从配置中的master失效后,sentinel可以选举出一个新的master用于自动替换原master的工作,主从配置中的其他redis服务自动指向新的master同步数据,一般建议sentinel采取奇数台,防止某一台sentinel无法连接到master导致误切换。
SDown主观下线(Subjectively Down)
SDOWN(主观不可用)是单个哨兵自己主观检测到的关于master的状态,从sentinel的角度来看,如果发送了PING心跳后,在一定时间内没有收到合法的回复,就到达了SDOQN的条件。
sentinel配置文件中的 down-after-milliseconds 设置了主观下线的时间长度(默认30秒)。
# sentinel down-after-milliseconds <masterName> <timeout> sentinel down-after-milliseconds mymaster 30000
ODown客观下线(Objectively Down)
ODOWN需要一定数量的sentinel,多个哨兵达成一致意见才能确认一个master客观上已经宕机了。
# sentinel monitor <master-name> <ip> <redis-port> <quorum> sentinel monitor mymaster 127.0.0.1 6379 2
选举出领导者哨兵
当主节点被判断客观下线后,各个哨兵节点会进行协商,先选举出一个领导者哨兵节点,并由该领导者哨兵节点进行failover(故障迁移)
领导者哨兵如何选出来的?
Raft算法
监视该主节点的所有哨兵都有可能被选为领导者,选举使用的算法是Raft算法;Raft算法的基本思路是先到先得,即在一轮选举中,哨兵A向B发送成为领导者的申请,如果B没有同意过其他哨兵,则会同意A成为领导者。

选新的master(im)
整个过程由sentinel自己独立完成,无需人工干涉。
新主登基
某一个slave被选中成为master
选出新的master的规则,剩余slave节点健康的前提下
- redis.conf文件中,优先级slave-priority或者replica-priority最高节点(数字越小优先级越高)
- 复制偏移量offset最大的从节点。
- 最小Run ID的从节点。

群臣俯首
执行 slaveof no one 命令让选出来的从节点成为新的主节点,并通过 slaveof 命令让其他节点成为其从节点。
sentinel leader 会对选举出来的新 master 执行 slaveof no one,将其提升为master节点
sentinel leader 向其他slave发送命令,让剩余的slave成为新的master节点的slave。
旧主拜服
- 将之前的已经下线的旧master设置为新选出的新master的从节点,当旧master重新上线后,它会成为新master的从节点
- sentinel leader 会让原来的master降级为slave并恢复正常工作。
哨兵使用建议
- 哨兵节点数量应该为多个,哨兵本身应该为集群,保证高可用
- 哨兵节点数量应该是奇数
- 各个哨兵节点的配置应该一致
- 如果哨兵节点部署在docker等容器里面,尤其要注意端口的正确映射
- 哨兵集群 + 主从复制,并不能保证数据零丢失
更多编程相关知识,请访问:编程视频!!
The above is the detailed content of Understand the sentinel in Redis in depth. For more information, please follow other related articles on the PHP Chinese website!

 Redis: Identifying Its Primary FunctionApr 12, 2025 am 12:01 AM
Redis: Identifying Its Primary FunctionApr 12, 2025 am 12:01 AMThe core function of Redis is a high-performance in-memory data storage and processing system. 1) High-speed data access: Redis stores data in memory and provides microsecond-level read and write speed. 2) Rich data structure: supports strings, lists, collections, etc., and adapts to a variety of application scenarios. 3) Persistence: Persist data to disk through RDB and AOF. 4) Publish subscription: Can be used in message queues or real-time communication systems.
 Redis: A Guide to Popular Data StructuresApr 11, 2025 am 12:04 AM
Redis: A Guide to Popular Data StructuresApr 11, 2025 am 12:04 AMRedis supports a variety of data structures, including: 1. String, suitable for storing single-value data; 2. List, suitable for queues and stacks; 3. Set, used for storing non-duplicate data; 4. Ordered Set, suitable for ranking lists and priority queues; 5. Hash table, suitable for storing object or structured data.
 How to implement redis counterApr 10, 2025 pm 10:21 PM
How to implement redis counterApr 10, 2025 pm 10:21 PMRedis counter is a mechanism that uses Redis key-value pair storage to implement counting operations, including the following steps: creating counter keys, increasing counts, decreasing counts, resetting counts, and obtaining counts. The advantages of Redis counters include fast speed, high concurrency, durability and simplicity and ease of use. It can be used in scenarios such as user access counting, real-time metric tracking, game scores and rankings, and order processing counting.
 How to use the redis command lineApr 10, 2025 pm 10:18 PM
How to use the redis command lineApr 10, 2025 pm 10:18 PMUse the Redis command line tool (redis-cli) to manage and operate Redis through the following steps: Connect to the server, specify the address and port. Send commands to the server using the command name and parameters. Use the HELP command to view help information for a specific command. Use the QUIT command to exit the command line tool.
 How to build the redis cluster modeApr 10, 2025 pm 10:15 PM
How to build the redis cluster modeApr 10, 2025 pm 10:15 PMRedis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to read redis queueApr 10, 2025 pm 10:12 PM
How to read redis queueApr 10, 2025 pm 10:12 PMTo read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to use redis cluster zsetApr 10, 2025 pm 10:09 PM
How to use redis cluster zsetApr 10, 2025 pm 10:09 PMUse of zset in Redis cluster: zset is an ordered collection that associates elements with scores. Sharding strategy: a. Hash sharding: Distribute the hash value according to the zset key. b. Range sharding: divide into ranges according to element scores, and assign each range to different nodes. Read and write operations: a. Read operations: If the zset key belongs to the shard of the current node, it will be processed locally; otherwise, it will be routed to the corresponding shard. b. Write operation: Always routed to shards holding the zset key.
 How to clear redis dataApr 10, 2025 pm 10:06 PM
How to clear redis dataApr 10, 2025 pm 10:06 PMHow to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

SublimeText3 Chinese version
Chinese version, very easy to use

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

