

 Technology peripheralsAIThe NUS Chinese team releases the latest model: single-view 3D reconstruction, fast and accurate!
Technology peripheralsAIThe NUS Chinese team releases the latest model: single-view 3D reconstruction, fast and accurate!
3D reconstruction of 2D images has always been a highlight in the CV field.
Different models have been developed to try to overcome this problem.
Today, scholars from the National University of Singapore jointly published a paper and developed a new framework, Anything-3D, to solve this long-standing problem.

##Paper address: https://arxiv.org/pdf/2304.10261.pdf
With the help of Meta’s “divide everything” model, Anything-3D directly makes any divided object come alive.

In addition, by using the Zero-1-to-3 model, you can get corgis from different angles.

# Even 3D reconstruction of characters can be performed.


It can be said that this one is a real breakthrough.
Anything-3D!In the real world, various objects and environments are diverse and complex. Therefore, without restrictions, 3D reconstruction from a single RGB image faces many difficulties.
Here, researchers from the National University of Singapore combined a series of visual language models and SAM (Segment-Anything) object segmentation models to generate a multi-functional and reliable system— —Anything-3D.
The purpose is to complete the task of 3D reconstruction under the condition of a single perspective.
They use the BLIP model to generate texture descriptions, use the SAM model to extract objects in the image, and then use the text → image diffusion model Stable Diffusion to place the objects into Nerf (neural radiation field) .
In subsequent experiments, Anything-3D demonstrated its powerful three-dimensional reconstruction capabilities. Not only is it accurate, it is also applicable to a wide range of applications.
Anything-3D has obvious effects in solving the limitations of existing methods. The researchers demonstrated the advantages of this new framework through testing and evaluation on various data sets.

In the picture above, we can see, "The picture of Corgi sticking out his tongue and running for thousands of miles" and "The picture of the silver-winged goddess committing herself to a luxury car" , and "Image of a brown cow in a field wearing a blue rope on its head."
This is a preliminary demonstration that the Anything-3D framework can skillfully restore single-view images taken in any environment into a 3D form and generate textures.
This new framework consistently provides highly accurate results despite large changes in camera perspective and object properties.
You must know that reconstructing 3D objects from 2D images is the core of the subject in the field of computer vision, and has great implications for robotics, autonomous driving, augmented reality, virtual reality, and three-dimensional printing. Influence.
Although some good progress has been made in recent years, the task of single-image object reconstruction in an unstructured environment is still a very attractive problem that needs to be solved urgently. .
Currently, researchers are tasked with generating a three-dimensional representation of one or more objects from a single two-dimensional image, including point clouds, grids, or volume representations.
However, this problem is not fundamentally true.
It is impossible to unambiguously determine the three-dimensional structure of an object due to the inherent ambiguity produced by two-dimensional projection.
Coupled with the huge differences in shape, size, texture and appearance, reconstructing objects in their natural environment is very complex. In addition, objects in real-world images are often occluded, which hinders accurate reconstruction of occluded parts.
At the same time, variables such as lighting and shadows can also greatly affect the appearance of objects, and differences in angle and distance can also cause obvious changes in the two-dimensional projection.
Enough about the difficulties, Anything-3D is ready to play.
In the paper, the researchers introduced in detail this groundbreaking system framework, which integrates the visual language model and the object segmentation model to easily turn 2D objects into 3D of.
In this way, a system with powerful functions and strong adaptability becomes. Single view reconstruction? Easy.
Combining the two models, the researchers say, it is possible to retrieve and determine the three-dimensional texture and geometry of a given image.
Anything-3D uses the BLIP model (Bootstrapping language-image model) to pre-train the text description of the image, and then uses the SAM model to identify the distribution area of the object.
Next, use the segmented objects and text descriptions to perform the 3D reconstruction task.
In other words, this paper uses a pre-trained 2D text→image diffusion model to perform 3D synthesis of images. In addition, the researchers used fractional distillation to train a Nerf specifically for images.

The above figure is the entire process of generating 3D images. The upper left corner is the 2D original image. It first goes through SAM to segment the corgi, then goes through BLIP to generate a text description, and then uses fractional distillation to create a Nerf.
Through rigorous experiments on different data sets, the researchers demonstrated the effectiveness and adaptability of this approach, while outperforming in accuracy, robustness, and generalization capabilities. existing methods.
The researchers also conducted a comprehensive and in-depth analysis of existing challenges in the reconstruction of 3D objects in natural environments, and explored how the new framework can solve such problems.
Ultimately, by integrating the zero-distance vision and language understanding capabilities in the basic model, the new framework can reconstruct objects from various real-world images and generate accurate, complex, and Widely applicable 3D representation.
It can be said that Anything-3D is a major breakthrough in the field of 3D object reconstruction.
Here are more examples:

## Porsche, bright orange excavator crane, little yellow rubber duck with green hat

# The cannon faded by the tears of the times, the cute little piggy Mini piggy bank, cinnabar red four-legged high stool
This new framework interactively identifies regions in single-view images and represents them in 2D with optimized text embeddings object. Ultimately, a 3D-aware fractional distillation model is used to efficiently generate high-quality 3D objects.In summary, Anything-3D demonstrates the potential of reconstructing natural 3D objects from single-view images. The researchers said that the quality of the 3D reconstruction of the new framework can be more perfect, and the researchers are constantly working hard to improve the quality of the generation. In addition, the researchers said that quantitative evaluations of 3D datasets such as new view synthesis and error reconstruction are not currently provided, but these will be included in future iterations of work. Meanwhile, the researchers’ ultimate goal is to expand this framework to accommodate more practical situations, including object recovery under sparse views. Wang is currently a tenure-track assistant professor in the ECE Department of the National University of Singapore (NUS). Before joining the National University of Singapore, he was an Assistant Professor in the CS Department of Stevens Institute of Technology. Prior to joining Stevens, I served as a postdoc in Professor Thomas Huang's image formation group at the Beckman Institute at the University of Illinois at Urbana-Champaign. Wang received his PhD from the Computer Vision Laboratory of the Ecole Polytechnique Fédérale de Lausanne (EPFL), supervised by Professor Pascal Fua, and received his Bachelor of Science with First Class Honors from the Department of Computer Science of the Hong Kong Polytechnic University in 2010 Bachelor of Science. About the author

The above is the detailed content of The NUS Chinese team releases the latest model: single-view 3D reconstruction, fast and accurate!. For more information, please follow other related articles on the PHP Chinese website!

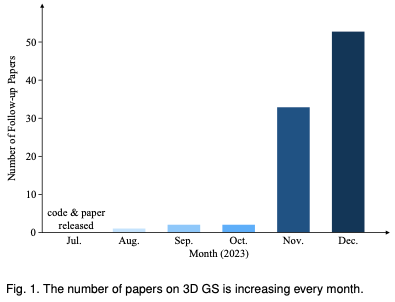 为何在自动驾驶方面Gaussian Splatting如此受欢迎,开始放弃NeRF?Jan 17, 2024 pm 02:57 PM
为何在自动驾驶方面Gaussian Splatting如此受欢迎,开始放弃NeRF?Jan 17, 2024 pm 02:57 PM写在前面&笔者的个人理解三维Gaussiansplatting(3DGS)是近年来在显式辐射场和计算机图形学领域出现的一种变革性技术。这种创新方法的特点是使用了数百万个3D高斯,这与神经辐射场(NeRF)方法有很大的不同,后者主要使用隐式的基于坐标的模型将空间坐标映射到像素值。3DGS凭借其明确的场景表示和可微分的渲染算法,不仅保证了实时渲染能力,而且引入了前所未有的控制和场景编辑水平。这将3DGS定位为下一代3D重建和表示的潜在游戏规则改变者。为此我们首次系统地概述了3DGS领域的最新发展和关
 了解 Microsoft Teams 中的 3D Fluent 表情符号Apr 24, 2023 pm 10:28 PM
了解 Microsoft Teams 中的 3D Fluent 表情符号Apr 24, 2023 pm 10:28 PM您一定记得,尤其是如果您是Teams用户,Microsoft在其以工作为重点的视频会议应用程序中添加了一批新的3DFluent表情符号。在微软去年宣布为Teams和Windows提供3D表情符号之后,该过程实际上已经为该平台更新了1800多个现有表情符号。这个宏伟的想法和为Teams推出的3DFluent表情符号更新首先是通过官方博客文章进行宣传的。最新的Teams更新为应用程序带来了FluentEmojis微软表示,更新后的1800表情符号将为我们每天
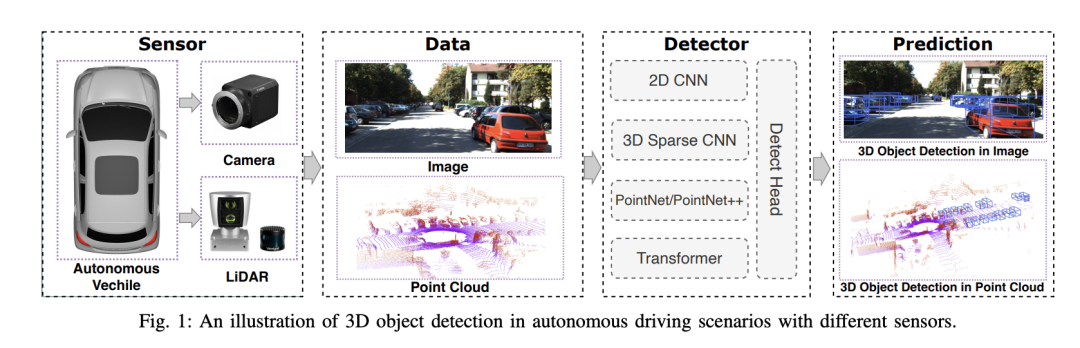 选择相机还是激光雷达?实现鲁棒的三维目标检测的最新综述Jan 26, 2024 am 11:18 AM
选择相机还是激光雷达?实现鲁棒的三维目标检测的最新综述Jan 26, 2024 am 11:18 AM0.写在前面&&个人理解自动驾驶系统依赖于先进的感知、决策和控制技术,通过使用各种传感器(如相机、激光雷达、雷达等)来感知周围环境,并利用算法和模型进行实时分析和决策。这使得车辆能够识别道路标志、检测和跟踪其他车辆、预测行人行为等,从而安全地操作和适应复杂的交通环境.这项技术目前引起了广泛的关注,并认为是未来交通领域的重要发展领域之一。但是,让自动驾驶变得困难的是弄清楚如何让汽车了解周围发生的事情。这需要自动驾驶系统中的三维物体检测算法可以准确地感知和描述周围环境中的物体,包括它们的位置、
 Windows 11中的Paint 3D:下载、安装和使用指南Apr 26, 2023 am 11:28 AM
Windows 11中的Paint 3D:下载、安装和使用指南Apr 26, 2023 am 11:28 AM当八卦开始传播新的Windows11正在开发中时,每个微软用户都对新操作系统的外观以及它将带来什么感到好奇。经过猜测,Windows11就在这里。操作系统带有新的设计和功能更改。除了一些添加之外,它还带有功能弃用和删除。Windows11中不存在的功能之一是Paint3D。虽然它仍然提供经典的Paint,它对抽屉,涂鸦者和涂鸦者有好处,但它放弃了Paint3D,它提供了额外的功能,非常适合3D创作者。如果您正在寻找一些额外的功能,我们建议AutodeskMaya作为最好的3D设计软件。如
 单卡30秒跑出虚拟3D老婆!Text to 3D生成看清毛孔细节的高精度数字人,无缝衔接Maya、Unity等制作工具May 23, 2023 pm 02:34 PM
单卡30秒跑出虚拟3D老婆!Text to 3D生成看清毛孔细节的高精度数字人,无缝衔接Maya、Unity等制作工具May 23, 2023 pm 02:34 PMChatGPT给AI行业注入一剂鸡血,一切曾经的不敢想,都成为如今的基操。正持续进击的Text-to-3D,就被视为继Diffusion(图像)和GPT(文字)后,AIGC领域的下一个前沿热点,得到了前所未有的关注度。这不,一款名为ChatAvatar的产品低调公测,火速收揽超70万浏览与关注,并登上抱抱脸周热门(Spacesoftheweek)。△ChatAvatar也将支持从AI生成的单视角/多视角原画生成3D风格化角色的Imageto3D技术,受到了广泛关注现行beta版本生成的3D模型,
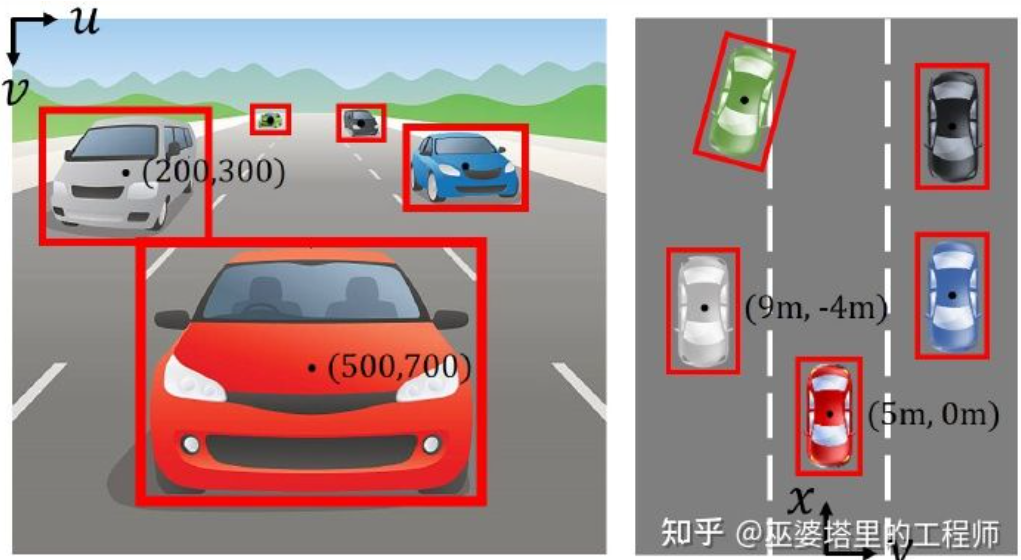 自动驾驶3D视觉感知算法深度解读Jun 02, 2023 pm 03:42 PM
自动驾驶3D视觉感知算法深度解读Jun 02, 2023 pm 03:42 PM对于自动驾驶应用来说,最终还是需要对3D场景进行感知。道理很简单,车辆不能靠着一张图像上得到感知结果来行驶,就算是人类司机也不能对着一张图像来开车。因为物体的距离和场景的和深度信息在2D感知结果上是体现不出来的,而这些信息才是自动驾驶系统对周围环境作出正确判断的关键。一般来说,自动驾驶车辆的视觉传感器(比如摄像头)安装在车身上方或者车内后视镜上。无论哪个位置,摄像头所得到的都是真实世界在透视视图(PerspectiveView)下的投影(世界坐标系到图像坐标系)。这种视图与人类的视觉系统很类似,
 《原神》:知名原神3d同人作者被捕Feb 15, 2024 am 09:51 AM
《原神》:知名原神3d同人作者被捕Feb 15, 2024 am 09:51 AM一些原神“奇怪”的关键词,在这两天很有关注度,明明搜索指数没啥变化,却不断有热议话题蹦窜。例如了龙王、钟离等“转变”立绘激增,虽在网络上疯传了一阵子,但是经过追溯发现这些是合理、常规的二创同人。如果单是这些,倒也翻不起多大的热度。按照一部分网友的说法,除了原神自身就有热度外,发现了一件格外醒目的事情:原神3d同人作者shirakami已经被捕。这引发了不小的热议。为什么被捕?关键词,原神3D动画。还是越过了线(就是你想的那种),再多就不能明说了。经过多方求证,以及新闻报道,确实有此事。自从去年发
 跨模态占据性知识的学习:使用渲染辅助蒸馏技术的RadOccJan 25, 2024 am 11:36 AM
跨模态占据性知识的学习:使用渲染辅助蒸馏技术的RadOccJan 25, 2024 am 11:36 AM原标题:Radocc:LearningCross-ModalityOccupancyKnowledgethroughRenderingAssistedDistillation论文链接:https://arxiv.org/pdf/2312.11829.pdf作者单位:FNii,CUHK-ShenzhenSSE,CUHK-Shenzhen华为诺亚方舟实验室会议:AAAI2024论文思路:3D占用预测是一项新兴任务,旨在使用多视图图像估计3D场景的占用状态和语义。然而,由于缺乏几何先验,基于图像的场景


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

SublimeText3 English version
Recommended: Win version, supports code prompts!

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

