
Home >Java >javaTutorial >How to generate ID through handwritten distributed snowflake SnowFlake in Java
How to generate ID through handwritten distributed snowflake SnowFlake in Java

- PHPzforward
- 2023-04-24 21:34:161179browse
SnowFlake Algorithm
The result of the SnowFlake algorithm generating id is a 64-bit integer. Its structure is as follows:
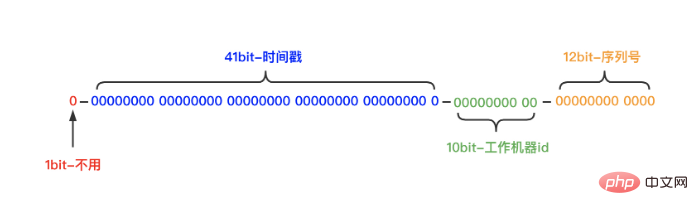
It is divided into four sections:
First paragraph: Bit 1 is unused and is always fixed at 0.
(Because the highest bit in binary is the sign bit, 1 represents a negative number, and 0 represents a positive number. The generated ID is generally a positive integer, so the highest bit is fixed to 0)
Second Segment: 41 bits is millisecond time (the length of 41 bits can be used for 69 years)
The third segment: 10 bits is workerId (the length of 10 bits supports the deployment of up to 1024 nodes)
(The 10 digits here are divided into two parts. The 5 digits in the first part represent the data center ID (0-31) and the 5 digits in the second part represent the machine ID (0-31))
Fourth paragraph: 12 digits Counting within milliseconds (the 12-bit counting sequence number supports each node generating 4096 ID serial numbers every millisecond)
Code implementation:
import java.util.HashSet;
import java.util.concurrent.atomic.AtomicLong;
public class SnowFlake {
//时间 41位
private static long lastTime = System.currentTimeMillis();
//数据中心ID 5位(默认0-31)
private long datacenterId = 0;
private long datacenterIdShift = 5;
//机房机器ID 5位(默认0-31)
private long workerId = 0;
private long workerIdShift = 5;
//随机数 12位(默认0~4095)
private AtomicLong random = new AtomicLong();
private long randomShift = 12;
//随机数的最大值
private long maxRandom = (long) Math.pow(2, randomShift);
public SnowFlake() {
}
public SnowFlake(long workerIdShift, long datacenterIdShift){
if (workerIdShift < 0 ||
datacenterIdShift < 0 ||
workerIdShift + datacenterIdShift > 22) {
throw new IllegalArgumentException("参数不匹配");
}
this.workerIdShift = workerIdShift;
this.datacenterIdShift = datacenterIdShift;
this.randomShift = 22 - datacenterIdShift - workerIdShift;
this.maxRandom = (long) Math.pow(2, randomShift);
}
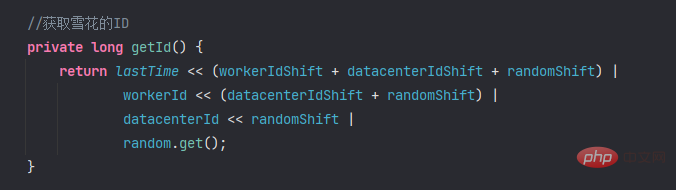
//获取雪花的ID
private long getId() {
return lastTime << (workerIdShift + datacenterIdShift + randomShift) |
workerId << (datacenterIdShift + randomShift) |
datacenterId << randomShift |
random.get();
}
//生成一个新的ID
public synchronized long nextId() {
long now = System.currentTimeMillis();
//如果当前时间和上一次时间不在同一毫秒内,直接返回
if (now > lastTime) {
lastTime = now;
random.set(0);
return getId();
}
//将最后的随机数,进行+1操作
if (random.incrementAndGet() < maxRandom) {
return getId();
}
//自选等待下一毫秒
while (now <= lastTime) {
now = System.currentTimeMillis();
}
lastTime = now;
random.set(0);
return getId();
}
//测试
public static void main(String[] args) {
SnowFlake snowFlake = new SnowFlake();
HashSet<Long> set = new HashSet<>();
for (int i = 0; i < 10000; i++) {
set.add(snowFlake.nextId());
}
System.out.println(set.size());
}
}The method of obtaining the id in the code is implemented using bit operations
## 1 | 41 1011 1110 10001001 01011100 00|00000|0 0000|0000 00000000 / /41-digit time 0|0000000 00000000 00000000 00000000 00000000 00|10001|0 0000|0000 00000000 //5-digit data center ID 0|0000000 00000000 00000000 00000000 00000000 00|00000|1 1001|0000 00000000 //5-digit machine IDor 0|0000000 00000000 00000000 00000000 00000000 00|00000|0 0000|0000 00000000 //12 digits sequenceAll generated ids are distributed according to the time trend increase the entire distribution Duplicate IDs will not be generated in the system (because there are datacenterId and workerId to distinguish) SnowFlake shortcomings: Since SnowFlake strongly relies on timestamps, changes in time will cause errors in SnowFlake's algorithm.-------------------------------------------------- -------------------------------------------------- 0 |0001100 10100010 10111110 10001001 01011100 00|10001|1 1001|0000 00000000 //Result: 910499571847892992
SnowFlake advantages:
The above is the detailed content of How to generate ID through handwritten distributed snowflake SnowFlake in Java. For more information, please follow other related articles on the PHP Chinese website!