



2023 will be the year when AI artificial intelligence technology becomes fully popular.
AIGC large models represented by ChatGPT, GPT-4, and Wenxinyiyan integrate text writing, code development, poetry creation and other functions into one, showing strong content production capabilities and bringing People were greatly shocked.
As a communications veteran, in addition to the AIGC model itself, Xiao Zaojun is more concerned about the communications technology behind the model. What kind of powerful network is it that supports the operation of AIGC? In addition, what kind of changes will the AI wave bring to traditional networks?
█ AIGC, how much computing power does it need?
As we all know, data, algorithms and computing power are the three basic elements for the development of artificial intelligence.

The AIGC large models mentioned earlier are so powerful not only because of the massive amounts of data fed behind them, but also because the algorithms are constantly evolving and upgrading. More importantly, the scale of human computing power has developed to a certain extent. The powerful computing infrastructure can fully support the computing needs of AIGC.
With the development of AIGC, the training model parameters have soared from hundreds of billions to trillions. In order to complete such a large-scale training, the number of GPUs supported by the underlying layer has also reached the scale of 10,000 cards.
Take ChatGPT as an example. They used Microsoft's supercomputing infrastructure for training. It is said that 10,000 V100 GPUs were used to form a high-bandwidth cluster. One training session requires about 3640 PF-days of computing power (i.e. 1 quadrillion calculations per second, running for 3640 days).
The FP32 computing power of a V100 is 0.014 PFLOPS (computing power unit, equal to 1 quadrillion floating point operations per second). Ten thousand V100, that’s 140 PFLOPS.
In other words, if the GPU utilization is 100%, then it will take 3640÷140=26 (days) to complete a training session.
It is impossible for the GPU utilization to reach 100%. If calculated as 33% (the assumed utilization provided by OpenAI), that would be 26 times three times, which is equal to 78 days.
It can be seen that GPU computing power and GPU utilization have a great impact on the training of large models.
Then the question is, what is the biggest factor affecting GPU utilization?
The answer is: network.
Ten thousand or even tens of thousands of GPUs, as a computing cluster, require a huge amount of bandwidth to interact with the storage cluster. In addition, when the GPU cluster performs training calculations, they are not independent, but mixed and parallel. There is a large amount of data exchange between GPUs, which also requires huge bandwidth.
If the network is not strong and data transmission is slow, the GPU will have to wait for data, resulting in a decrease in utilization. As utilization decreases, training time will increase, costs will increase, and user experience will deteriorate.
The industry once made a model to calculate the relationship between network bandwidth throughput, communication delay and GPU utilization, as shown in the following figure:

As you can see, the stronger the network throughput capability, the higher the GPU utilization; the greater the communication dynamic delay, the lower the GPU utilization.
In a word, don’t play big models without a good network.
█ What kind of network can support the operation of AIGC?
In order to cope with the network adjustments caused by AI cluster computing, the industry has also thought of many ways.
There are three main traditional response strategies: Infiniband, RDMA, and modular switches. Let’s take a brief look at each of them.
Infiniband networking
Infiniband (literally translated as "infinite bandwidth" technology, abbreviated as IB) networking should be familiar to children engaged in data communications. .
# This is currently the best way to build a high-performance network, with extremely high bandwidth, which can achieve no congestion and low latency. What ChatGPT and GPT-4 use is said to be Infiniband networking.
If there is any shortcoming of Infiniband networking, it is one word - expensive. Compared with traditional Ethernet networking, the cost of Infiniband networking will be several times more expensive. This technology is relatively closed. There is currently only one mature supplier in the industry, and users have little choice.
- RDMA network

When RDMA was first proposed, it was carried in the InfiniBand network. Now, RDMA is gradually transplanted to Ethernet.
Currently, the mainstream networking solution for high-performance networks is to build a network that supports RDMA based on the RoCE v2 (RDMA over Converged Ethernet, RDMA based on Converged Ethernet) protocol .
This solution has two important matching technologies, namely PFC (Priority Flow Control, priority-based flow control) and ECN (Explicit Congestion Notification, explicit congestion notification). They are technologies created to avoid congestion in the link. However, if they are triggered frequently, they will cause the sender to suspend sending or slow down sending, thereby reducing the communication bandwidth. (They will also be mentioned below)
- Framed switches
There are some overseas Internet companies hope to use modular switches (DNX chip VOQ technology) to meet the needs of building high-performance networks.
DNX: a chip series of broadcom (Broadcom)
VOQ: Virtual Output Queue, virtual output queue
This solution seems feasible, but it also faces the following challenges.
First of all, the expansion capabilities of modular switches are average. The size of the chassis limits the maximum number of ports. If you want to build a larger cluster, you need to expand horizontally across multiple chassis.
# Secondly, the equipment of modular switches consumes a lot of power. There are a large number of line card chips, fabric chips, fans, etc. in the chassis. The power consumption of a single device exceeds 20,000 watts, and some even exceed 30,000 watts. The requirements for the power supply capacity of the cabinet are too high.
#Third, modular switches have a large number of single device ports and a large fault domain.
#Based on the above reasons, modular switch equipment is only suitable for small-scale deployment of AI computing clusters.
█ What exactly is DDC
What I said before is all traditional plan. Since these traditional solutions don't work, of course we have to find new ways.
So, a new solution called DDC made its debut.
DDC, the full name is Distributed Disaggregated Chassis.
It is a "split version" of the previous modular switch. The expansion capability of modular switches is insufficient, so we can simply disassemble it and turn one device into multiple devices. Isn’t that OK?

Frame-type equipment is generally divided into switching network boards (backplanes) and business lines The two parts of the card (board card) are connected to each other with connectors.
#The DDC solution turns the switching network board into an NCF device and the service line card into an NCP device. Connectors become optical fibers. The management function of modular devices also becomes NCC in the DDC architecture.
NCF: Network Cloud Fabric (network cloud management control plane)
NCP: Network Cloud Packet Processing (network cloud packet processing)
NCC: Network Cloud Controller
After DDC changed from centralized to distributed, its scalability has been greatly enhanced. It can flexibly design the network scale according to the size of the AI cluster.
Let’s give two examples (single POD networking and multi-POD networking).
In a single POD network, 96 NCPs are used as access points. Among them, the NCP has a total of 18 400G downstream interfaces, which are responsible for connecting the network cards of the AI computing cluster. There are a total of 40 200G interfaces in the uplink, and a maximum of 40 NCFs can be connected. NCF provides 96 200G interfaces. The uplink and downlink bandwidth at this scale has an overspeed ratio of 1.1:1. The entire POD can support 1,728 400G network interfaces. Calculated based on a server equipped with 8 GPUs, it can support 216 AI computing servers.

Single POD networking
Multi-level POD networking, the scale can become bigger.
In a multi-level POD network, the NCF device must sacrifice half of the SerDes to connect to the second-level NCF. Therefore, at this time, a single POD uses 48 NCPs for access, with a total of 18 400G interfaces in the downlink.


##█ Technical characteristics of DDC
From the perspective of scale and bandwidth throughput, DDC can already meet the network needs of AI large model training.
#However, the operation process of the network is complex, and DDC also needs to improve in aspects such as delay combat, load balancing, and management efficiency.
The network is working During the process, burst traffic may occur, causing the receiving end to have no time to process it, causing congestion and packet loss.
#In order to deal with this situation, DDC adopts a forwarding mechanism based on VOQ Cell.

##After the sender receives the data packet from the network, it will be classified into VOQ (Virtual Output queue).
Before sending a data packet, NCP will first send a Credit message to determine whether the receiving end has enough buffer space to process these messages.
If the receiving end is OK, the data packet is fragmented into Cells (small slices of the data packet), and dynamically load balanced to the intermediate Fabric node (NCF).
#If the receiving end is temporarily unable to process the message, the message will be temporarily stored in the VOQ of the sending end and will not be directly forwarded to the receiving end.
At the receiving end, these Cells will be reorganized and stored, and then forwarded to the network.
The sliced Cells will be sent using a polling mechanism. It can fully utilize each uplink and ensure that the amount of data transmitted on all uplinks is approximately equal.
Polling mechanism
This mechanism makes full use of the cache , which can greatly reduce packet loss and even eliminate packet loss. Data retransmissions are reduced, and the overall communication delay is more stable and lower, which can improve bandwidth utilization and thus improve business throughput efficiency.
- PFC single-hop deployment to avoid deadlock
We mentioned earlier that PFC (priority-based traffic) was introduced in the RDMA lossless network control) technology for flow control.
Simply put, PFC is to create 8 virtual channels on an Ethernet link, and assign corresponding priorities to each virtual channel, allowing independent suspension and restart. Any one of the virtual channels allows traffic from other virtual channels to pass through without interruption.

PFC can implement queue-based flow control, but it also has a problem, That's a deadlock.
The so-called deadlock is that congestion occurs at the same time between multiple switches due to loops and other reasons (the cache consumption of each port exceeds the threshold), and they are all waiting. The other party releases resources, resulting in a "stalemate" (the data flow of all switches is permanently blocked).
#With DDC networking, there is no PFC deadlock problem. Because, from the perspective of the entire network, all NCPs and NCFs can be regarded as one device. For the AI server, the entire DDC is just a switch, and there are no multi-level switches. Therefore, there is no deadlock.

- Distributed OS, improve reliability
##█ Commercial progress of DDC
In summary, relatively Compared with traditional networking, DDC has significant advantages in terms of network scale, scalability, reliability, cost, and deployment speed. It is the product of network technology upgrades and provides an idea to subvert the original network architecture, which can realize the decoupling of network hardware, the unification of network architecture, and the expansion of forwarding capacity.
#The industry has used the OpenMPI test suite to conduct comparative simulation tests between frame-type equipment and traditional networking equipment. The test conclusion is: in the All-to-All scenario, compared with traditional networking, the bandwidth utilization of frame-type devices is increased by about 20% (corresponding to an increase in GPU utilization of about 8%).
It is precisely because of DDC’s significant capability advantages that this technology has now become the key development direction of the industry. For example, Ruijie Networks took the lead in launching two deliverable DDC products, namely the 400G NCP switch-RG-S6930-18QC40F1 and the 200G NCF switch-RG-X56-96F1.

RG-S6930-18QC40F1 switch is 2U in height and provides 18 400G panels port, 40 200G Fabric inline ports, 4 fans and 2 power supplies.
The RG-X56-96F1 switch is 4U in height and provides 96 200G Fabric inline ports, 8 fans and 4 power supplies.
It is reported that Ruijie Networks will continue to develop and launch products in the form of 400G ports.
The above is the detailed content of What are the characteristics of a network suitable for driving AIGC?. For more information, please follow other related articles on the PHP Chinese website!

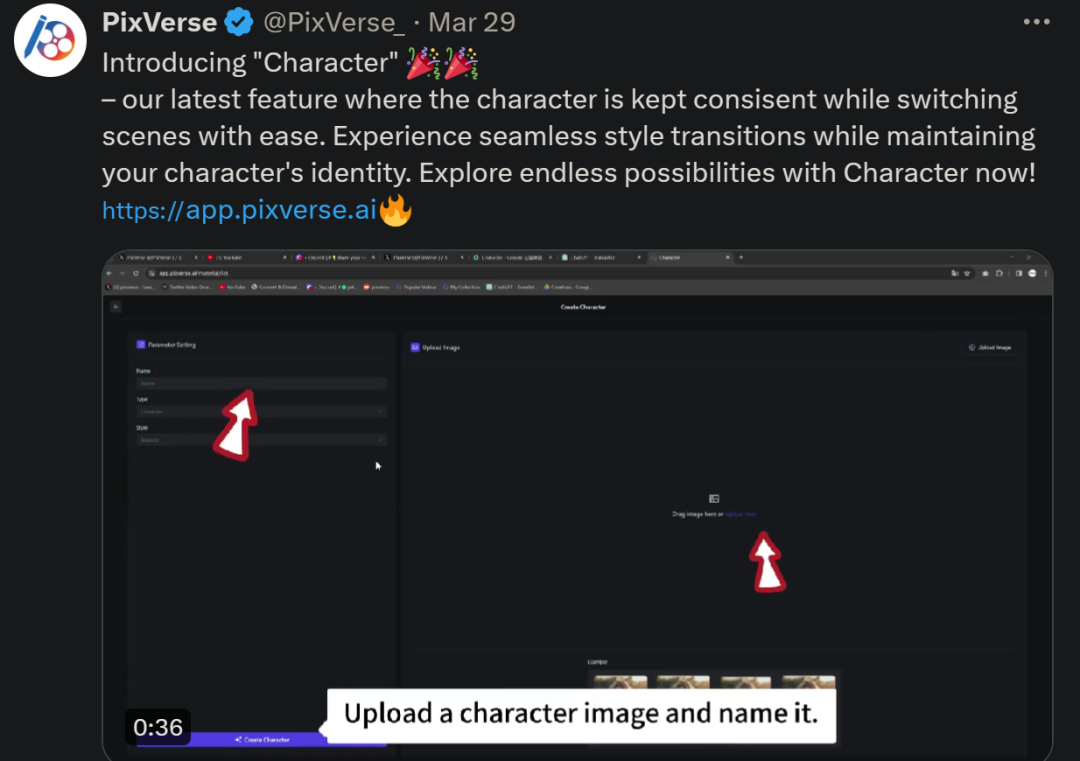 统一角色、百变场景,视频生成神器PixVerse被网友玩出了花,超强一致性成「杀招」Apr 01, 2024 pm 02:11 PM
统一角色、百变场景,视频生成神器PixVerse被网友玩出了花,超强一致性成「杀招」Apr 01, 2024 pm 02:11 PM又双叒叕是一个新功能的亮相。你是否会遇见过想要给图片角色换个背景,但是AI总是搞出「物非人也非」的效果。即使在Midjourney、DALL・E这样成熟的生成工具中,保持角色一致性还得有些prompt技巧,不然人物就会变来变去,根本达不到你想要的结果。不过,这次算是让你遇着了。AIGC工具PixVerse的「角色-视频」新功能可以帮你实现这一切。不仅如此,它能生成动态视频,让你的角色更加生动。输入一张图,你就能够得到相应的动态视频结果,在保持角色一致性的基础上,丰富的背景元素和角色动态让生成结果
 ChatGPT克星,介绍五款免费又好用的AIGC检测工具May 22, 2023 pm 02:38 PM
ChatGPT克星,介绍五款免费又好用的AIGC检测工具May 22, 2023 pm 02:38 PM简介ChatGPT推出后,犹如潘多拉魔盒被打开了。我们现在正观察到许多工作方式的技术转变。人们正在使用ChatGPT创建网站、应用程序,甚至写小说。随着AI生成工具的大肆宣传和引入,我们也已经看到了不良行为者的增加。如果你关注最新消息,你一定曾听说ChatGPT已经通过了沃顿商学院的MBA考试。迄今为止,ChatGPT通过的考试涵盖了从医学到法律学位等多个领域。除了考试之外,学生们正在用它来提交作业,作家们正在提交生成性内容,而研究人员只需输入提示语就能产生高质量的论文。为了打击生成性内容的滥用
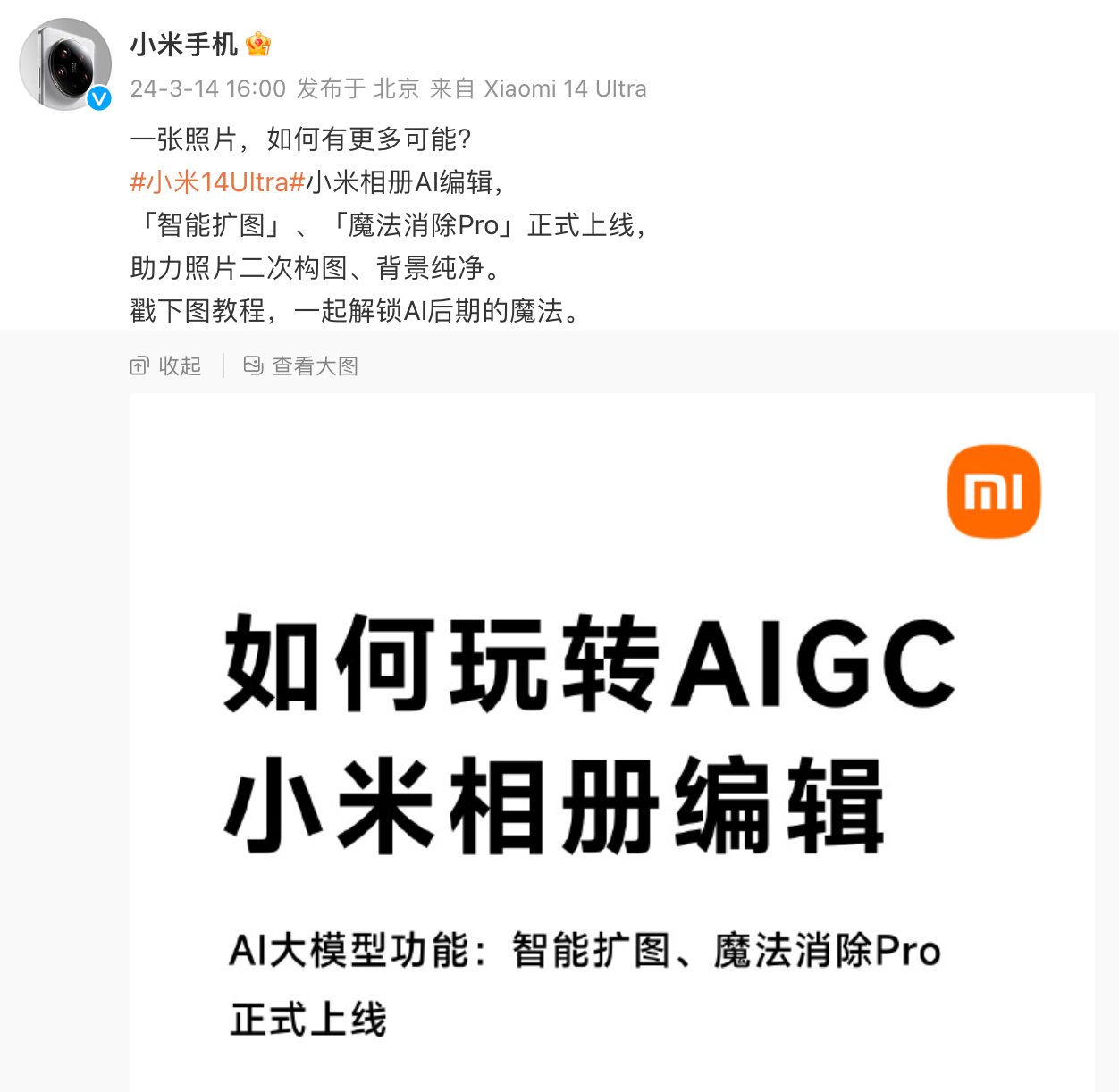 小米相册 AIGC 编辑功能正式上线:支持智能扩图、魔法消除 ProMar 14, 2024 pm 10:22 PM
小米相册 AIGC 编辑功能正式上线:支持智能扩图、魔法消除 ProMar 14, 2024 pm 10:22 PM3月14日消息,小米官方今日宣布,小米相册AIGC编辑功能正式上线小米14Ultra手机,并将在本月内全量上线小米14、小米14Pro和RedmiK70系列手机。AI大模型为小米相册带来两个新功能:智能扩图与魔法消除Pro。AI智能扩图支持对构图不好的图片进行扩展和自动构图,操作方式为:打开相册编辑-进入裁切旋转-点击智能扩图。魔法消除Pro能够对游客照中的路人进行无痕消除,使用方式为:打开相册编辑-进入魔法消除-点击右上角的Pro。目前,小米14Ultra机器已经上线智能扩图与魔法消除Pro功
 营销效果大幅提升,AIGC视频创作就该这么用Jun 25, 2024 am 12:01 AM
营销效果大幅提升,AIGC视频创作就该这么用Jun 25, 2024 am 12:01 AM经过一年多的发展,AIGC已经从文字对话、图片生成逐步向视频生成迈进。回想四个月前,Sora的诞生让视频生成赛道经历了一场洗牌,大力推动了AIGC在视频创作领域的应用范围和深度。在人人都在谈论大模型的时代,我们一方面惊讶于视频生成带来的视觉震撼,另一方面又面临着落地难问题。诚然,大模型从技术研发到应用实践还处于一个磨合期,仍需结合实际业务场景进行调优,但理想与现实的距离正在被逐步缩小。营销作为人工智能技术的重要落地场景,成为了很多企业及从业者想要突破的方向。掌握了恰当方法,营销视频的创作过程就会
 AIGC革新客户服务,维音构建“1+5”生成式AI智能产品矩阵Sep 15, 2023 am 11:57 AM
AIGC革新客户服务,维音构建“1+5”生成式AI智能产品矩阵Sep 15, 2023 am 11:57 AM由自然语言处理、语音识别、语音合成、机器学习等技术组成的人工智能技术,应用于各行各业获得广泛认可。置身于AI应用的前沿,从2022年底开始,维音不断见证AIGC技术所带来的惊喜,也有幸参与到这场覆盖全球的技术浪潮。经过训练、测试、调优和应用,维音将其丰富的客户服务行业经验与强大的大模型能力相结合,开发出了适用于坐席端和业务端的生成式AI客服机器人。同时,维音还将底层能力与维音Vision系列智能产品相互连接,最终形成了“1+5”维音生成式AI智能产品矩阵其中,“1”是维音自主训练的大模型服务平台
 实测7款「Sora级」视频生成神器,谁有本事登上「铁王座」?Aug 05, 2024 pm 07:19 PM
实测7款「Sora级」视频生成神器,谁有本事登上「铁王座」?Aug 05, 2024 pm 07:19 PM机器之能报道编辑:杨文谁能成为AI视频圈的King?美剧《权力的游戏》中,有一把「铁王座」。传说,它由巨龙「黑死神」熔掉上千把敌人丢弃的利剑铸成,象征着无上的权威。为了坐上这把铁椅子,各大家族展开了一场场争斗和厮杀。而自Sora出现以来,AI视频圈也掀起了一场轰轰烈烈的「权力的游戏」,这场游戏的玩家主要有大洋彼岸的RunwayGen-3、Luma,国内的快手可灵、字节即梦、智谱清影、Vidu、PixVerseV2等。今天我们就来测评一下,看看究竟谁有资格登上AI视频圈的「铁王座」。-1-文生视频
 美图公司AIGC落地B端新场景,“AI海报”进一步提升设计效率May 25, 2023 pm 09:11 PM
美图公司AIGC落地B端新场景,“AI海报”进一步提升设计效率May 25, 2023 pm 09:11 PM5月16日,美图公司旗下美图设计室上线“AI海报”功能,该功能旨在降低设计门槛,提高制作效率。在AIGC的加持下,让更多非专业人士也能轻松制作出高质量海报。传统的海报制作方式包括使用Photoshop专业设计工具和使用海报模板这类便捷设计工具。PS需要专业设计师才能熟练操作,但即使是专业设计师,也需要花费较多时间不断调整尺寸、配色等细节,耗费大量时间和精力。没有设计基础的人只能使用现成的海报模板来完成设计,但选择模板、替换图片、替换文本同样消耗时间,而且即便用户花了大量时间,有时候也无法达到理想
 AI在用 | 川普魂穿《黑神话》,3D「魔改」悟空……一只黑猴勾起多少种AI玩法?Aug 21, 2024 pm 10:50 PM
AI在用 | 川普魂穿《黑神话》,3D「魔改」悟空……一只黑猴勾起多少种AI玩法?Aug 21, 2024 pm 10:50 PM机器之能报道编辑:杨文以大模型、AIGC为代表的人工智能浪潮已经在悄然改变着我们生活及工作方式,但绝大部分人依然不知道该如何使用。因此,我们推出了「AI在用」专栏,通过直观、有趣且简洁的人工智能使用案例,来具体介绍AI使用方法,并激发大家思考。我们也欢迎读者投稿亲自实践的创新型用例。投稿邮箱:content@jiqizhixin.com这两天被一只黑猴子刷了屏。这热度高得有多离谱?抖音、微博、公众号,只要一划拉,全在聊这款国产游戏《黑神话:悟空》,甚至官媒都下场开直播。还有公司直接放假,让员工在


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

Atom editor mac version download
The most popular open source editor

Dreamweaver Mac version
Visual web development tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 English version
Recommended: Win version, supports code prompts!

