

 Technology peripheralsAIThe dilemma of open source for large AI models: Monopoly, walls and the sorrow of computing power
Technology peripheralsAIThe dilemma of open source for large AI models: Monopoly, walls and the sorrow of computing powerThe dilemma of open source for large AI models: Monopoly, walls and the sorrow of computing power

This article is reprinted with the authorization of AI New Media Qubit (public account ID: QbitAI). Please contact the source for reprinting.
In June 2020, OpenAI released GPT-3. Its scale of hundreds of billions of parameters and amazing language processing capabilities have brought great shock to the domestic AI community. However, since GPT-3 is not open to the domestic market, when a number of commercial companies providing text generation services are born overseas, we can only look back and sigh.
In August this year, Stability AI, an open source company in London, released Stable Diffusion, a Vincent graph model, and open sourced the weights and code of the model for free, which quickly triggered the AI Painting applications are exploding around the world.
#It can be said that open source played a direct catalytic role in the AIGC boom in the second half of this year.
#And when large models become a game that everyone can participate in, it is not just AIGC that benefits.
01
Large model open source in progress
Four years ago, a project called BERT The language model came out and changed the game rules of AI models with 300 million parameters.
Today, the volume of AI models has jumped to the scale of one trillion, but the "monopoly" of large models has also become increasingly prominent:
Big companies, big computing power, strong algorithms, and big models, together they have built a wall that is difficult for ordinary developers and small and medium-sized enterprises to break through.
Technical barriers, as well as the computing resources and infrastructure required to train and use large models, hinder This marks our path from “refining” large models to “using” large models. Therefore, open source is urgent. Allowing more people to participate in the game of large models through open source and transforming large models from an emerging AI technology into a robust infrastructure is becoming the consensus of many large model creators.
# Also under this consensus, Alibaba Damo Academy launched the Chinese model open source community "ModelScope" at the Yunqi Conference not long ago. It has attracted great attention in the AI community. Currently, some domestic institutions have begun to contribute models to the community or establish their own open source model systems.
# Foreign large-model open source ecological construction is currently ahead of domestic ones. Stability AI was born as a private company but has its own open source genes. It has its own large developer community and has a stable profit model while being open source.
BLOOM, released in July this year, has 176 billion parameters and is currently the largest open source language model. The BigScience behind it perfectly fits the open source spirit. The toes reveal the momentum of competing with technology giants. BigScience is an open collaborative organization spearheaded by Huggingface and is not an officially established entity. The birth of BLOOM is the result of more than 1,000 researchers from more than 70 countries training on supercomputers for 117 days.
#In addition, technology giants are not uninvolved in the open source of large models. In May of this year, Meta open sourced the large model OPT with 175 billion parameters. In addition to allowing OPT to be used for non-commercial purposes, it also released its code and 100 pages of logs recording the training process. It can be said that the open source is very thorough.
The research team pointed out bluntly in the abstract of OPT's paper, "Considering the computational cost, these models are difficult to replicate without large amounts of funding. For The few models available through the API do not have access to full model weights, making them difficult to study." The full name of the model "Open Pre-trained Transformers" also shows Meta's open source attitude. This can be said to be an insinuation of GPT-3 released by OpenAI, which is not "Open" (only providing API paid services), and the 540 billion parameter large model PaLM (not open source) launched by Google in April this year.
Among large companies that have always had a strong sense of monopoly, Meta’s open source move is a breath of fresh air. Percy Liang, director of the Fundamental Model Research Center at Stanford University at the time, commented: "This is an exciting step toward opening up new opportunities for research. Generally speaking, we can think that greater openness will enable researchers to solve problems Deeper issues."
02
The imagination of large models should not stop at AIGC
Percy Liang’s words also answer the question of why large models must be open source from an academic level.
#The birth of original results requires open source to provide the soil.
A R&D team trains a large model. If it stops at publishing a paper at a top conference, then all other researchers will get are various aspects of the paper. This kind of "showing muscle" figures without seeing more details of the model training technology can only take time to reproduce, but it may not be successful. Reproducibility is a guarantee that scientific research results are reliable and credible. With open models, codes and data sets, scientific researchers can keep up with the most cutting-edge research in a more timely manner, and stand on the shoulders of giants to touch a star. Fruits from higher places can save a lot of time and cost and speed up technological innovation.
The lack of originality in large model work in China is mainly reflected in blind pursuit of model size, but little innovation in the underlying architecture. This is the general consensus among industry experts engaged in large model research.
Associate Professor Liu Zhiyuan from the Department of Computer Science of Tsinghua University pointed out to AI Technology Review: There are some relatively innovative works on the architecture of large models in China, but basically they are all Still based on Transformer, China still lacks foundational architectures like Transformer and models like BERT and GPT-3 that can cause major changes in the field.
Dr. Zhang Jiaxing, chief scientist of the IDEA Research Institute (Guangdong-Hong Kong-Macao Greater Bay Area Digital Economy Research Institute), also told AI Technology Review that from tens of billions to hundreds of billions to Trillions, after we have overcome various system and engineering challenges, we should think about new model structures instead of simply making the model bigger.
On the other hand, for large models to make technological progress, a set of model evaluation standards is needed, and the generation of standards requires openness and transparency. Some recent research is trying to propose various evaluation metrics for many large models, but some excellent models are excluded due to inaccessibility. For example, Google's large model PaLM trained under its Pathways architecture has super language understanding capabilities. It can easily explain the punchline of a joke, and DeepMind's large language model Chinchilla is not open source.
#But whether it is from the excellent capabilities of the model itself or from the status of these major manufacturers, they should not be absent from such a fair playing field.
It is a sad fact that a recent study by Percy Liang and colleagues showed that compared to non-open source models, the current open source model has There are certain gaps in performance in many core scenes. Open source large models such as OPT-175B, BLOOM-176B and GLM-130B from Tsinghua University almost completely lost to non-open source large models in various tasks, including OpenAI's InstructGPT, Microsoft/NVIDIA's TNLG- 530B and so on (as shown below).

##Caption: Percy Liang et al. Holistic Evaluation of Language Models
To resolve this embarrassing situation, each leader needs to open source their own high-quality large models, so that the overall progress in the field of large models can reach a higher level faster.
In terms of industrial implementation of large models, open source is the only way to go.
If you take the release of GPT-3 as a starting point, the large model has been pursued for more than two years. In my opinion, the research and development technology is relatively mature, but on a global scale, the implementation of large models is still in the early stages. Although the large models developed by major domestic manufacturers have internal business implementation scenarios, they do not yet have mature commercialization models as a whole.
#When the implementation of large-scale models is gaining momentum, doing a good job in open source can lay the foundation for a large-scale implementation ecology in the future.
#The nature of large models determines the need for open source for implementation. Zhou Jingren, deputy director of Alibaba Damo Academy, told AI Technology Review, "Large models are abstractions and refinements of human knowledge systems, so the scenarios they can be applied to and the value they generate are huge." And only through open source, large models can be Application potential can be maximized by many creative developers.
#This is something that the API model that closes the internal technical details of the large model cannot do. First of all, this model is suitable for model users with low development capabilities. For them, the success or failure of large model implementation is equivalent to being completely in the hands of the R&D institution.
Take OpenAI, the biggest winner that provides large model API paid services, as an example. According to OpenAI statistics, more than 300 companies around the world have used GPT-3. Technology applications, but the premise of this fact is that OpenAI’s research and development strength is strong and GPT-3 is strong enough. If the model itself performs poorly, then such developers are helpless.
#More importantly, the capabilities that large models can provide through open APIs are limited, making it difficult to handle complex and diverse application requirements. At present, there are only some creative apps on the market, but overall they are still in a "toy" stage and are far from reaching the stage of large-scale industrialization.
"The value generated is not that great, and the cost cannot be recovered, so the application scenarios based on GPT-3 API are very limited. Many people in the industry In fact, I don’t agree with this approach,” Zhang Jiaxing said. Indeed, foreign companies such as copy.ai and Jasper choose to engage in AI-assisted writing business. The user market is relatively larger, so they can generate relatively large commercial value, while more applications are only small-scale.
#In contrast, open source does "teaching people how to fish."
In the open source model, enterprises rely on the open source code to conduct training and secondary training that meet their own business needs based on the existing basic framework. Development, which can give full play to the versatility advantages of large models, release productivity far beyond the current level, and ultimately bring about the true implementation of large model technology in the industry.
#As the most clearly visible track for the commercialization of large models at present, the take-off of AIGC has confirmed the success of the large model open source model. However, In other application scenarios, the open source of large models is still in the minority, both at home and abroad. Lan Zhenzhong, head of the Deep Learning Laboratory of West Lake University, once told AI Technology Review that although there are many results on large models, there are very few open sources, and ordinary researchers have limited access, which is very regrettable.
Contribution, participation, collaboration, open source with these keywords as its core can bring together a large number of passionate developers to jointly create a potentially transformative The large model project allows large models to move from the laboratory to industry faster.
03
Unbearable weight: computing power
The importance of open source for large models This is a consensus, but there is still a huge roadblock on the road to open source: computing power.
This is also the biggest challenge facing the current implementation of large models. Even though Meta has open sourced OPT, so far it does not seem to have made a big ripple in the application market. Ultimately, the cost of computing power is still unbearable for small developers, let alone fine-tuning large models. , secondary development, just reasoning is very difficult.
Because of this, under the wave of reflection on parameters, many R&D institutions have turned to the idea of making lightweight models and controlling the parameters of the model to Between hundreds of millions to several billions. The "Mencius" model launched by Lanzhou Technology and the "Fengshen Bang" series of models open sourced by IDEA Research Institute are both domestic representatives of this route. They split the various capabilities of very large models into models with relatively smaller parameters, and have proven their ability to surpass hundreds of billions of models in some single tasks.
#But there is no doubt that the road to large models will not stop here. Many industry experts have told AI Technology Review that the parameters of large models are still There is room for improvement, and someone must continue to explore larger-scale models. So we have to face the dilemma of open source large models. So, what are the solutions?
We first consider it from the perspective of computing power itself. The construction of large-scale computer clusters and computing power centers will definitely be a trend in the future. After all, the computing resources on the end cannot meet the demand. But now Moore's Law has slowed down, and there is no shortage of arguments in the industry that Moore's Law is coming to an end. If you simply place your hope on the improvement of computing power, you will not be able to quench your short-term thirst.
"Now one card can run (in terms of reasoning) a billion models. According to the current growth rate of computing power, when one The card can run a 100 billion model, which means that it may take ten years to increase the computing power a hundred times." Zhang Jiaxing explained.
#We can’t wait so long for the big model to be launched.
Another direction is to make a fuss about training technology to speed up large model inference, reduce computing power costs, and reduce energy consumption, so as to improve large models ease of use.
For example, Meta’s OPT (compared to GPT-3) only requires 16 NVIDIA v100 GPUs to train and deploy the complete model code base. This number is One seventh of GPT-3. Recently, Tsinghua University and Zhipu AI jointly opened up the bilingual large model GLM-130B. Through fast inference methods, the model has been compressed to the point where it can be used for stand-alone inference on an A100 (40G*8) or V100 (32G*8) server. .
# Of course it makes sense to work hard in this direction. The self-evident reason why major manufacturers are unwilling to open source large models is the high training cost. Experts have previously estimated that tens of thousands of Nvidia v100 GPUs were used to train GPT-3, with a total cost of up to US$27.6 million. If an individual wants to train a PaLM, it will cost US$9 to 17 million. If the training cost of large models can be reduced, their willingness to open source will naturally increase.
#But in the final analysis, this can only alleviate the constraints on computing resources from an engineering perspective, but is not the ultimate solution. Although many large-scale models with hundreds of billions and trillions of levels have begun to promote their "low energy consumption" advantages, the computing power wall is still too high.
#In the end, we still have to go back to the large model itself to find a breakthrough point. A very promising direction is the sparse dynamic large model.
# Sparse large models are characterized by very large capacities, but only certain parts for a given task, sample, or label are activated. In other words, this sparse dynamic structure can allow large models to jump up a few levels in parameter quantity without having to pay huge computational costs, killing two birds with one stone. This is a huge advantage compared to dense large models like GPT-3, which require activating the entire neural network to complete even the simplest tasks, which is a huge waste of resources.
Google is the pioneer of sparse dynamic structures. They first proposed MoE (Sparsely-Gated Mixture-of-Experts Layer, sparsely gated expert mixing layer) in 2017, and launched 16,000 of them last year. The billion-parameter large model Switch Transformers incorporates a MoE-style architecture, and the training efficiency is increased by 7 times compared with their previous dense model T5-Base Transformer.
The Pathways unified architecture on which this year’s PaLM is based is a model of sparse dynamic structure: the model can dynamically learn what specific parts of the network are good at. For tasks, we can call small paths through the network as needed, without activating the entire neural network to complete a task.
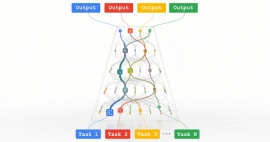
Note: Pathways architecture
This is essentially similar to how the human brain operates. There are tens of billions of neurons in the human brain, but only neurons with specific functions are activated when performing specific tasks. Otherwise, the huge energy consumption will be unbearable.
Large, versatile, and efficient, this large model route is undoubtedly very attractive.
"With the support of sparse dynamics in the future, the calculation cost will not be so high, but the model Parameters will definitely become larger and larger, and sparse dynamic structures may open up a new world for large models. It will be no problem to go to 10 trillion or 100 billions." Zhang Jiaxing believes that sparse dynamic structures will be the solution to the problem of large model size and computing power. The ultimate path to conflict between costs. But he also added that when this kind of model structure is not yet popular, it does not make much sense to blindly continue to make the model bigger.
#At present, there are relatively few domestic attempts in this direction, and they are not as thorough as Google. Exploration and innovation in large model structures and open source promote each other, and we need more open source to stimulate changes in large model technology.
# What hinders the open source of large models is not only the low availability caused by the computing power cost of large models, but also security issues.
Regarding large models, especially the risks of abuse brought about by open-sourcing large models, there seem to be more concerns from abroad and a lot of controversy. This has become Many institutions choose not to open source the credentials of large models, but that may also be an excuse for them to resist generosity.
#OpenAI has attracted a lot of criticism for this. When they released GPT-2 in 2019, they claimed that the model's text generation capability was too powerful and might cause ethical harm, making it unsuitable for open source. When GPT-3 was released a year later, it only provided an API trial. The current open source version of GPT-3 is actually reproduced by the open source community itself.
#In fact, restricting access to large models will be detrimental to large models in improving their robustness and reducing bias and toxicity. When Joelle Pineau, the head of Meta AI, talked about the decision to open source OPT, she sincerely stated that her own team alone cannot solve all problems, such as ethical bias and malicious words that may arise during the text generation process. They believe that if enough homework is done, large models can be made publicly accessible responsibly.
# Maintaining open access and adequate transparency while guarding against the risk of abuse is no easy task. As the person who opened "Pandora's Box", Stability AI has enjoyed a good reputation brought by active open source, but it has also recently encountered the backlash brought by open source, causing controversy in aspects such as copyright ownership.
The ancient dialectical proposition of "freedom and security" behind open source has been around for a long time. There may not be an absolutely correct answer, but at the beginning of the big model As we move toward implementation, a clear fact is: we have not done enough to open source large models.
More than two years have passed, and we already have our own trillion-level large-scale model. In the subsequent transformation process of large-scale models from "reading thousands of books" to "traveling thousands of miles", open source It is an inevitable choice.
Recently, GPT-4 is about to come out, and everyone has great expectations for its leap in capabilities, but we don’t know what it will be like in the future. How much productivity will be released for how many people?
The above is the detailed content of The dilemma of open source for large AI models: Monopoly, walls and the sorrow of computing power. For more information, please follow other related articles on the PHP Chinese website!

 The AI Skills Gap Is Slowing Down Supply ChainsApr 26, 2025 am 11:13 AM
The AI Skills Gap Is Slowing Down Supply ChainsApr 26, 2025 am 11:13 AMThe term "AI-ready workforce" is frequently used, but what does it truly mean in the supply chain industry? According to Abe Eshkenazi, CEO of the Association for Supply Chain Management (ASCM), it signifies professionals capable of critic
 How One Company Is Quietly Working To Transform AI ForeverApr 26, 2025 am 11:12 AM
How One Company Is Quietly Working To Transform AI ForeverApr 26, 2025 am 11:12 AMThe decentralized AI revolution is quietly gaining momentum. This Friday in Austin, Texas, the Bittensor Endgame Summit marks a pivotal moment, transitioning decentralized AI (DeAI) from theory to practical application. Unlike the glitzy commercial
 Nvidia Releases NeMo Microservices To Streamline AI Agent DevelopmentApr 26, 2025 am 11:11 AM
Nvidia Releases NeMo Microservices To Streamline AI Agent DevelopmentApr 26, 2025 am 11:11 AMEnterprise AI faces data integration challenges The application of enterprise AI faces a major challenge: building systems that can maintain accuracy and practicality by continuously learning business data. NeMo microservices solve this problem by creating what Nvidia describes as "data flywheel", allowing AI systems to remain relevant through continuous exposure to enterprise information and user interaction. This newly launched toolkit contains five key microservices: NeMo Customizer handles fine-tuning of large language models with higher training throughput. NeMo Evaluator provides simplified evaluation of AI models for custom benchmarks. NeMo Guardrails implements security controls to maintain compliance and appropriateness
 AI Paints A New Picture For The Future Of Art And DesignApr 26, 2025 am 11:10 AM
AI Paints A New Picture For The Future Of Art And DesignApr 26, 2025 am 11:10 AMAI: The Future of Art and Design Artificial intelligence (AI) is changing the field of art and design in unprecedented ways, and its impact is no longer limited to amateurs, but more profoundly affecting professionals. Artwork and design schemes generated by AI are rapidly replacing traditional material images and designers in many transactional design activities such as advertising, social media image generation and web design. However, professional artists and designers also find the practical value of AI. They use AI as an auxiliary tool to explore new aesthetic possibilities, blend different styles, and create novel visual effects. AI helps artists and designers automate repetitive tasks, propose different design elements and provide creative input. AI supports style transfer, which is to apply a style of image
 How Zoom Is Revolutionizing Work With Agentic AI: From Meetings To MilestonesApr 26, 2025 am 11:09 AM
How Zoom Is Revolutionizing Work With Agentic AI: From Meetings To MilestonesApr 26, 2025 am 11:09 AMZoom, initially known for its video conferencing platform, is leading a workplace revolution with its innovative use of agentic AI. A recent conversation with Zoom's CTO, XD Huang, revealed the company's ambitious vision. Defining Agentic AI Huang d
 The Existential Threat To UniversitiesApr 26, 2025 am 11:08 AM
The Existential Threat To UniversitiesApr 26, 2025 am 11:08 AMWill AI revolutionize education? This question is prompting serious reflection among educators and stakeholders. The integration of AI into education presents both opportunities and challenges. As Matthew Lynch of The Tech Edvocate notes, universit
 The Prototype: American Scientists Are Looking For Jobs AbroadApr 26, 2025 am 11:07 AM
The Prototype: American Scientists Are Looking For Jobs AbroadApr 26, 2025 am 11:07 AMThe development of scientific research and technology in the United States may face challenges, perhaps due to budget cuts. According to Nature, the number of American scientists applying for overseas jobs increased by 32% from January to March 2025 compared with the same period in 2024. A previous poll showed that 75% of the researchers surveyed were considering searching for jobs in Europe and Canada. Hundreds of NIH and NSF grants have been terminated in the past few months, with NIH’s new grants down by about $2.3 billion this year, a drop of nearly one-third. The leaked budget proposal shows that the Trump administration is considering sharply cutting budgets for scientific institutions, with a possible reduction of up to 50%. The turmoil in the field of basic research has also affected one of the major advantages of the United States: attracting overseas talents. 35
 All About Open AI's Latest GPT 4.1 Family - Analytics VidhyaApr 26, 2025 am 10:19 AM
All About Open AI's Latest GPT 4.1 Family - Analytics VidhyaApr 26, 2025 am 10:19 AMOpenAI unveils the powerful GPT-4.1 series: a family of three advanced language models designed for real-world applications. This significant leap forward offers faster response times, enhanced comprehension, and drastically reduced costs compared t


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

