

 Technology peripheralsAIIs AI development ushering in unification in 70 years? Ma Yi, Cao Ying, Shen Xiangyang's latest AI review: exploring the basic principles and 'standard model' of intelligence generation
Technology peripheralsAIIs AI development ushering in unification in 70 years? Ma Yi, Cao Ying, Shen Xiangyang's latest AI review: exploring the basic principles and 'standard model' of intelligence generationIs AI development ushering in unification in 70 years? Ma Yi, Cao Ying, Shen Xiangyang's latest AI review: exploring the basic principles and 'standard model' of intelligence generation

Artificial intelligence has been developing for seventy years. Although technical indicators have been constantly refreshed, there is still no answer to what exactly "intelligence" is and how it appears and develops.
Recently, Professor Ma Yi teamed up with computer scientist Dr. Shen Xiangyang and neuroscientist Professor Cao Ying to publish a research review on the emergence and development of intelligence, hoping to theoretically put the research on intelligence into practice. Unify to improve the understanding and interpretability of artificial intelligence models.

Paper link: http://arxiv.org/abs/2207.04630
Introduced in the article Two basic principles: Parsimony and Self-consistency.
The author believes that this is the cornerstone of the rise of intelligence, artificial or natural. Although there are numerous discussions and elaborations on each of these two principles in classic literature, this article reinterprets these two principles in a completely measurable and calculable way.
Based on these two first principles, the authors derive an efficient computational framework: compressed closed-loop transcription, which unifies and explains modern deep networks and many artificial intelligence practices. evolution.
- What to learn: What to learn from data, and how to measure the quality of learning?
- How to learn: How do we achieve such a learning goal through an efficient and effective computing framework?
Regarding the first question of "what to learn", the principle of simplicity holds that:
The learning goal of an intelligent system is to learn from Find low-dimensional structures in observational data in the external world and reorganize and represent them in the most compact and structured way. This is the "Occam's razor" principle: don't add entities unless necessary.Without this principle, intelligence would not be possible! If the observation data of the external world has no low-dimensional structure, there will be nothing worth learning or remembering, and good generalization or prediction will not be possible.
Moreover, intelligent systems need to save resources as much as possible, such as energy, space, time and material. In some cases, this principle is also called the "compression principle". However, the parsimony of intelligence is not to achieve the best compression, but to obtain the most compact and structured expression of the observation data through efficient computing means.
So how to measure simplicity?
For general high-dimensional models, the computational cost of many commonly used mathematical or statistical "measures" is exponential, or for data distributions with low-dimensional structures. Said, even undefined, such as maximum likelihood, KL divergence, mutual information, Jensen-Shannon and Wasserstein distance, etc.
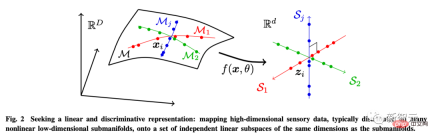
The author believes that the purpose of learning is actually to establish a mapping (usually nonlinear) to obtain a low-dimensional representation from the original high-dimensional input.

In this way, the distribution of the obtained feature z should be more compact and structured; compactness means more economical storage; Structure means more efficient access and use: linear structures, in particular, are ideal for interpolation or extrapolation.
For this purpose, the author introduces Linear Discriminant Representation (LDR) to achieve three sub-goals:
- Compression: Map high-dimensional sensory data x to low-dimensional representation z;
- Linearization: Map each type of object distributed in the nonlinear subsurface to a linear subspace;
- Sparsification: mapping different categories into mutually independent or least relevant subspaces.
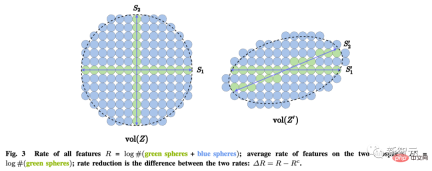
These goals can be achieved through maximum coding rate reduction (rate reduction) to ensure that all The learned LDR model has optimal parsimony performance.
Regarding the second question of "how to learn", the self-consistency principle holds that:
An autonomous intelligent system seeks the most self-consistent model for observations of the external world by minimizing the differences in internal representations of observed data and regenerated data.
The principle of parsimony alone does not ensure that the learned model captures all important information about the data about the external world. For example, mapping each category to a one-dimensional one-hot vector by minimizing cross-entropy can be seen as a form of parsimony.
It may learn a good classifier, but the learned features may also collapse into a singleton, also known as neural collapse. Such learned features will no longer contain enough information to regenerate the original data.
Even if we consider the more general LDR model, maximizing the coding rate difference alone cannot automatically determine the correct dimensions of the environment feature space.
If the dimensionality of the feature space is too low, the learned model will not match the data; if it is too high, the model may over-match.
More generally, we argue that perceptual learning is distinct from learning specific tasks. The goal of perception is to learn everything predictable about what is being perceived.
As Einstein once said: "Things should be kept simple, but not too simple."
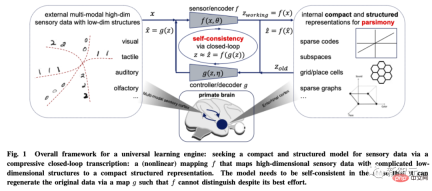
Universal Learning Engine
Based on these two principles, the article uses visual image data modeling as an example to derive the compressive closed-loop transcription framework.
It performs compressed closed-loop transcription of nonlinear data sub-flow patterns internally to achieve LDR by comparing and minimizing the differences in internal representations.
The chase-and-flight game between the encoder/sensor and the decoder/controller allows the distribution of data generated by the decoded representation to chase and match the observed real data distribution.
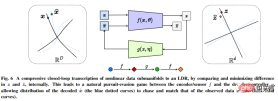
In addition, the author pointed out that compressed closed-loop transcription can effectively perform incremental learning.
An LDR model for a new data class can be learned through a constrained game between the encoder and the decoder: the memory of past learned classes can be naturally It is retained as a constraint in the game, that is, as a "fixed point" for closed-loop transcription.
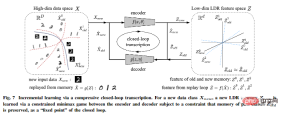
The article also puts forward more speculative ideas about the universality of this framework and extends it to three dimensions. Vision and reinforcement learning, and predicting its impact on neuroscience, mathematics, and advanced intelligence.

Through this framework derived from first principles: information encoding theory, closed-loop feedback control, optimization/depth The concepts of network and game theory are organically integrated and become an essential part of a complete, autonomous intelligent system.

It is worth mentioning that compressed closed-loop architecture is ubiquitous in all intelligent creatures in nature and at different scales : From the brain (compressed sensory information), to spinal circuits (compressed muscle movements), to DNA (compressed protein functional information) and so on.
So the author believes that compressive closed-loop transcription should be the "universal learning engine" behind all intelligent behaviors. It enables natural or artificial intelligence systems to discover and refine low-dimensional structures from seemingly complex sensory data, converting them into concise and regular internal expressions to facilitate correct judgment and prediction of the external world in the future.
This is the calculation basis and mechanism for the occurrence and development of all intelligence.
Reference: http://arxiv.org/abs/2207.04630
The above is the detailed content of Is AI development ushering in unification in 70 years? Ma Yi, Cao Ying, Shen Xiangyang's latest AI review: exploring the basic principles and 'standard model' of intelligence generation. For more information, please follow other related articles on the PHP Chinese website!

 Gemma Scope: Google's Microscope for Peering into AI's Thought ProcessApr 17, 2025 am 11:55 AM
Gemma Scope: Google's Microscope for Peering into AI's Thought ProcessApr 17, 2025 am 11:55 AMExploring the Inner Workings of Language Models with Gemma Scope Understanding the complexities of AI language models is a significant challenge. Google's release of Gemma Scope, a comprehensive toolkit, offers researchers a powerful way to delve in
 Who Is a Business Intelligence Analyst and How To Become One?Apr 17, 2025 am 11:44 AM
Who Is a Business Intelligence Analyst and How To Become One?Apr 17, 2025 am 11:44 AMUnlocking Business Success: A Guide to Becoming a Business Intelligence Analyst Imagine transforming raw data into actionable insights that drive organizational growth. This is the power of a Business Intelligence (BI) Analyst – a crucial role in gu
 How to Add a Column in SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AM
How to Add a Column in SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AMSQL's ALTER TABLE Statement: Dynamically Adding Columns to Your Database In data management, SQL's adaptability is crucial. Need to adjust your database structure on the fly? The ALTER TABLE statement is your solution. This guide details adding colu
 Business Analyst vs. Data AnalystApr 17, 2025 am 11:38 AM
Business Analyst vs. Data AnalystApr 17, 2025 am 11:38 AMIntroduction Imagine a bustling office where two professionals collaborate on a critical project. The business analyst focuses on the company's objectives, identifying areas for improvement, and ensuring strategic alignment with market trends. Simu
 What are COUNT and COUNTA in Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AM
What are COUNT and COUNTA in Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AMExcel data counting and analysis: detailed explanation of COUNT and COUNTA functions Accurate data counting and analysis are critical in Excel, especially when working with large data sets. Excel provides a variety of functions to achieve this, with the COUNT and COUNTA functions being key tools for counting the number of cells under different conditions. Although both functions are used to count cells, their design targets are targeted at different data types. Let's dig into the specific details of COUNT and COUNTA functions, highlight their unique features and differences, and learn how to apply them in data analysis. Overview of key points Understand COUNT and COU
 Chrome is Here With AI: Experiencing Something New Everyday!!Apr 17, 2025 am 11:29 AM
Chrome is Here With AI: Experiencing Something New Everyday!!Apr 17, 2025 am 11:29 AMGoogle Chrome's AI Revolution: A Personalized and Efficient Browsing Experience Artificial Intelligence (AI) is rapidly transforming our daily lives, and Google Chrome is leading the charge in the web browsing arena. This article explores the exciti
 AI's Human Side: Wellbeing And The Quadruple Bottom LineApr 17, 2025 am 11:28 AM
AI's Human Side: Wellbeing And The Quadruple Bottom LineApr 17, 2025 am 11:28 AMReimagining Impact: The Quadruple Bottom Line For too long, the conversation has been dominated by a narrow view of AI’s impact, primarily focused on the bottom line of profit. However, a more holistic approach recognizes the interconnectedness of bu
 5 Game-Changing Quantum Computing Use Cases You Should Know AboutApr 17, 2025 am 11:24 AM
5 Game-Changing Quantum Computing Use Cases You Should Know AboutApr 17, 2025 am 11:24 AMThings are moving steadily towards that point. The investment pouring into quantum service providers and startups shows that industry understands its significance. And a growing number of real-world use cases are emerging to demonstrate its value out


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SublimeText3 English version
Recommended: Win version, supports code prompts!

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

