
Home >Common Problem >OpenAI and Microsoft Sentinel Part 3: DaVinci and Turbo
OpenAI and Microsoft Sentinel Part 3: DaVinci and Turbo

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-04-14 21:28:011750browse
Welcome back to our series on OpenAI’s Large Language Models (LLM) and Microsoft Sentinel. In the first part, we built a basic playbook using OpenAI and Sentinel's built-in Azure Logic Apps connector to explain the MITER ATT&CK tactics found at the event, and discussed some of the different parameters that could affect the OpenAI model, such as temperature and frequency punish. Next, we extend this functionality using Sentinel's REST API to find scheduled analysis rules and return a summary of the rule detection logic.
If you've been paying attention, you may have noticed that our first playbook looks for MITER ATT&CK tactics from Sentinel events, but does not include any event techniques in the GPT3 tip. why not? Well, fire up your OpenAI API Playground and let’s take a trip down the rabbit hole (with apologies to Lewis Carroll).
- Mode: Complete
- Model: text-davinci-003
- Temperature: 1
- Maximum length: 500
- Maximum P: 1
- Frequency Penalty: 0
- Presence Penalty: 0
- Tip: "Please explain the following MITER ATT&CK tactics and techniques: ["DefenseEvasion"], [" T1564”]”
This is our first result:
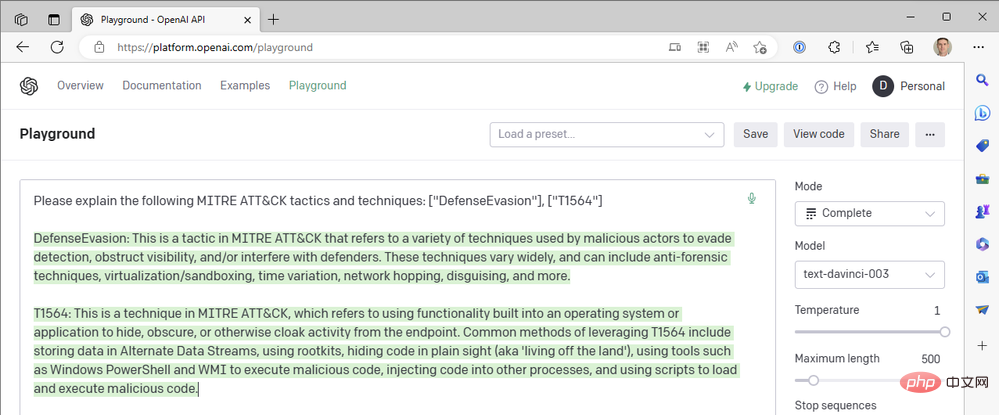
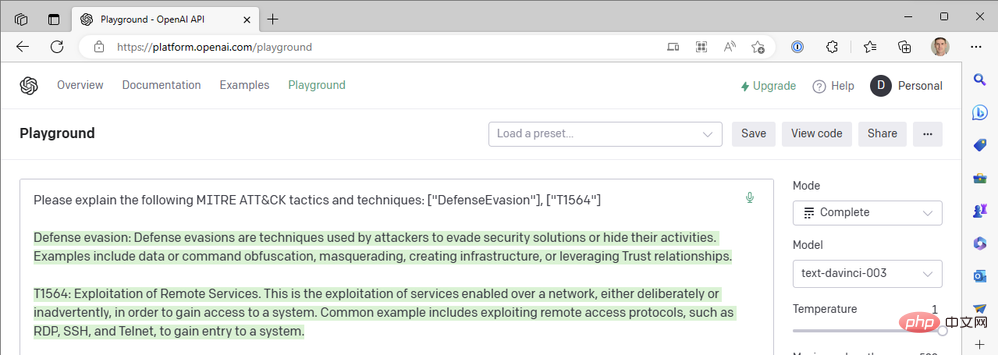
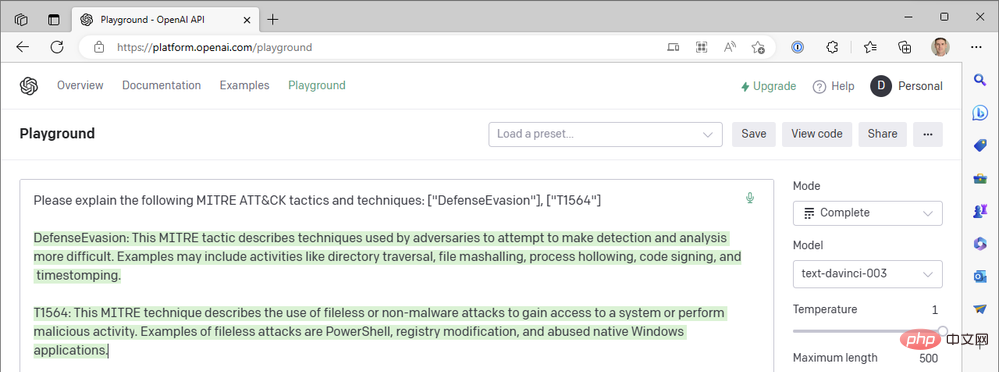
#But the OpenAI connector in our Azure Logic App doesn't provide us with chat-based actions, and we don't have the option to Turbo model, so how can we introduce ChatGPT into our Sentinel workflow? Just like we closed the Sentinel Logic App Connector in Part II to directly call the Sentinel REST API's HTTP operations, we can do the same thing with OpenAI's API. Let's explore the process of building a Logic Apps workflow that uses a chat model instead of a text completion model. 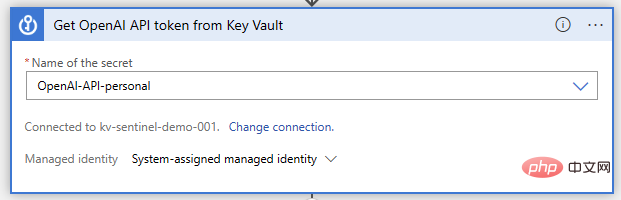
Key Vault to store your OpenAI API credentials
- A way to authorize your Logic App to read secrets from Key Vault (I recommend using Azure RBAC's Managed Identity)
- A network that allows your Logic App to connect to Key Vault Access (I used the defined IP address and CIDR range for the appropriate Azure region in the connector document)
- Now, let's open our Logic Apps designer and start building the functionality. Just like before, we are using Microsoft Sentinel event triggers. We will perform the Key Vault operation "Get secret" after this, in which we will specify the secret name where the API key is stored:
#Next, we need to create a API requests initialize and set some variables. This isn't strictly necessary; we could simply write out the request in our HTTP action, but it will make it much easier to change the prompt and other parameters later. The two required parameters in the OpenAI Chat API call are "model" and "message", so let's initialize a string variable to store the model name and an array variable for the message.
The "message" parameter is the main input to the chat model. It is constructed as a set of message objects, each with a role, such as "system" or "user", and content. Let's look at an example from the Playground:
The System object allows us to set the behavioral context of the AI model for this chat session. The User object is our question and the model will reply with an Assistant object. If needed, we can include previous responses in User and Assistant objects to provide the AI model with a "conversation history."
Back in our Logic App Designer, I used two "Append to Array Variable" actions and one "Initialize Variable" action to build the "Messages" array:
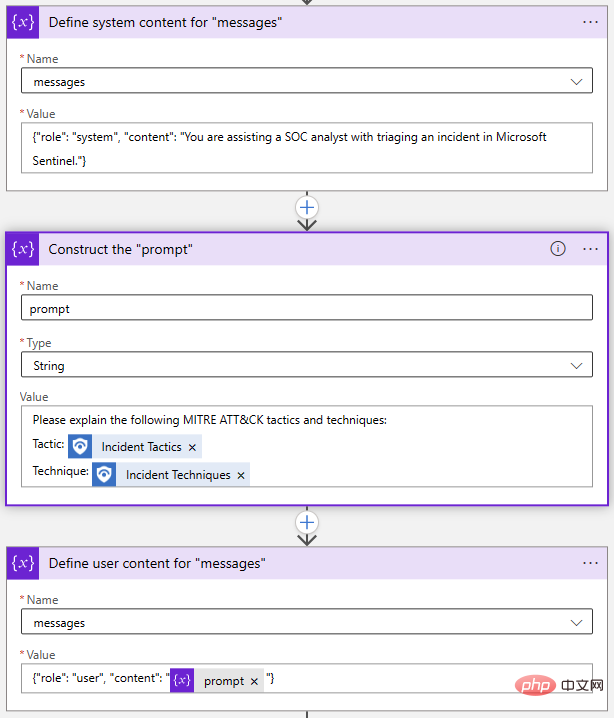
Again, this can all be done in one step, but I chose to explode each object separately. If I want to modify my prompt, I just need to update the Prompt variable.
Next, let’s adjust the temperature parameter to a very low value to make the AI model more deterministic. "Float" variables are ideal for storing this value.
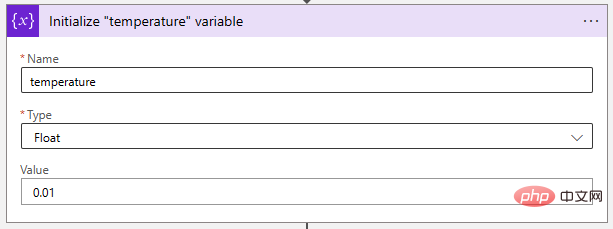
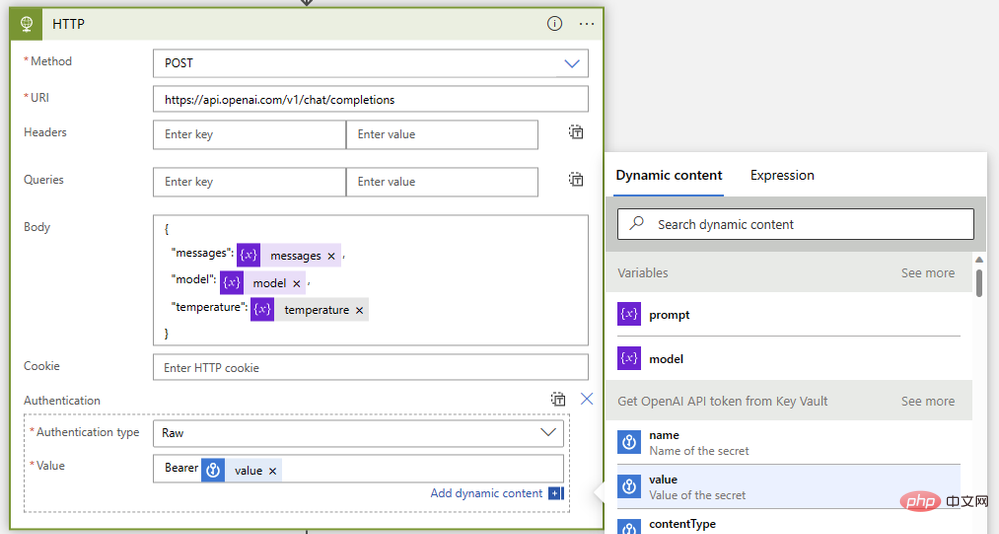
Finally, let's put them together with an HTTP operation like this:
- Method: Mail
- Type: https://api.openai.com/v1/chat/completions
- Body:
{"model": @{variables('model')},"messages": @{variables('messages')},"temperature": @{variables('temperature')}} - Authentication: Original
- Value:
Bearer @{body('Get_OpenAI_API_token_from_Key_Vault')?['value']}
- Value:
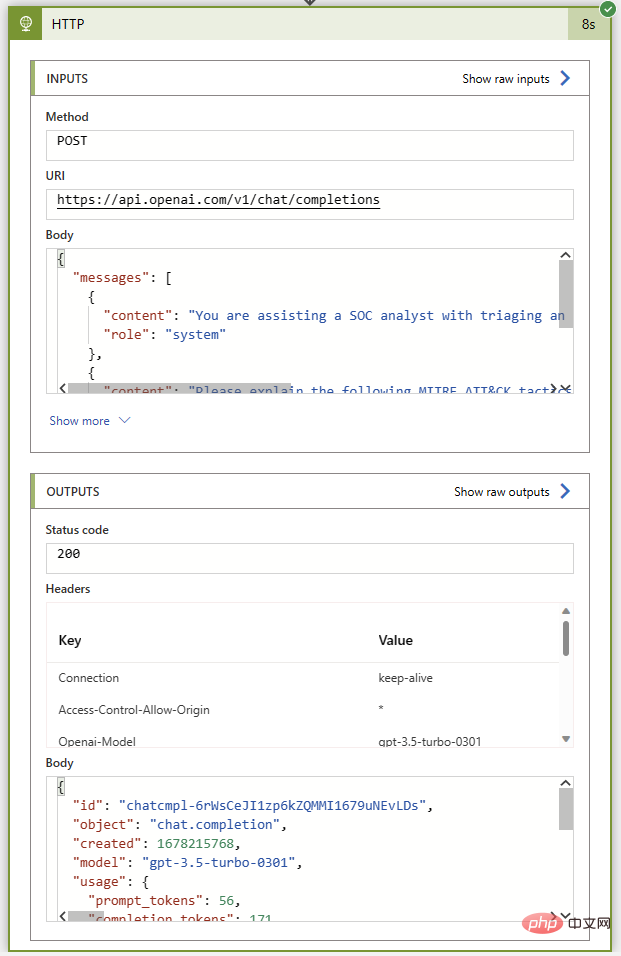
As before, let’s run this playbook without any comment actions to ensure that before we connect it back to the Sentinel instance Everything was fine before. If all goes well, we'll get the 200 status code and a great summary of MITER ATT&CK tactics and techniques in the assistant message.
Now comes the easy part: adding event comments using the Sentinel connector. We'll use the Parse JSON operation to parse the response body and then initialize a variable with the text from the ChatGPT reply. Because we know the response format, we know that we can use the following expression to extract the reply from the Choices item at index 0:
@{body('Parse_JSON')?['choices']?[0]?['message']?['content']}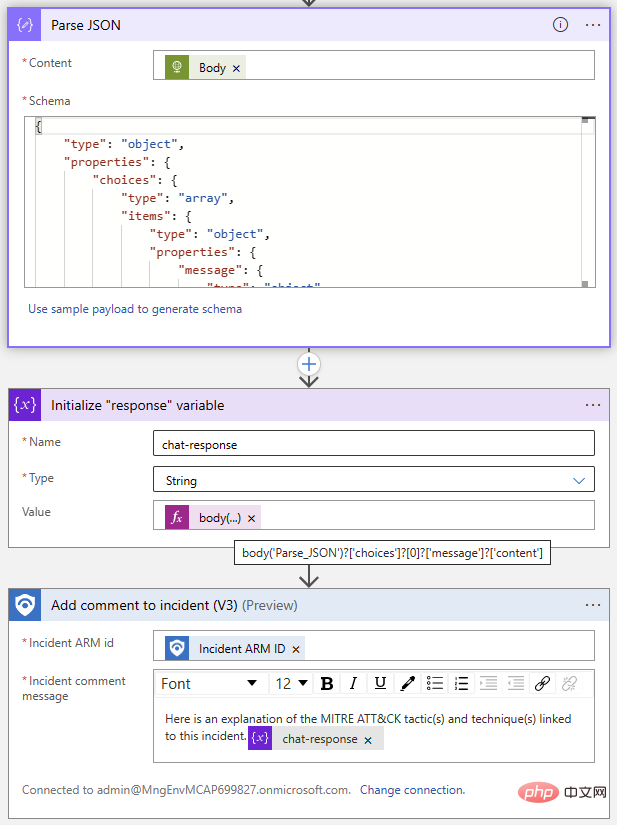
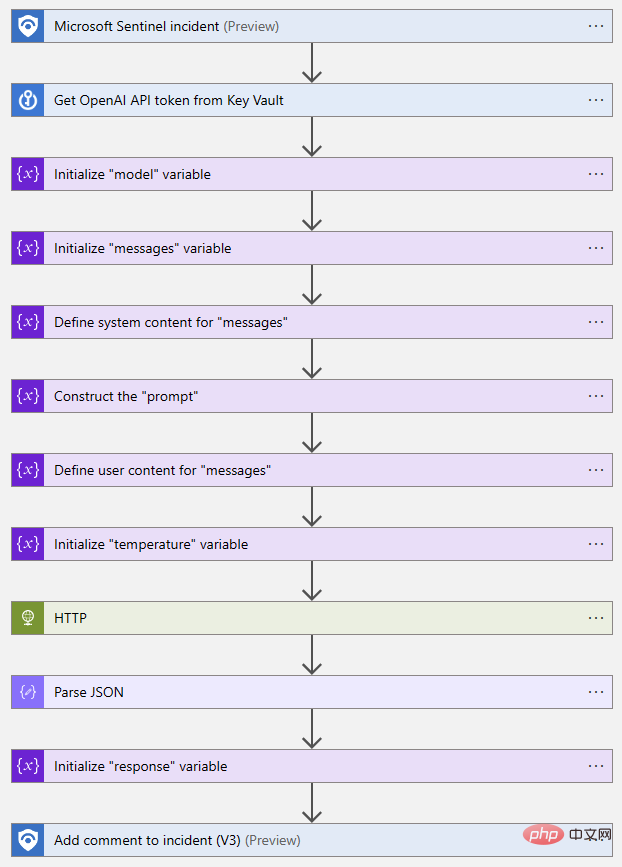
The following is the completed Logic App flow Bird's eye view:
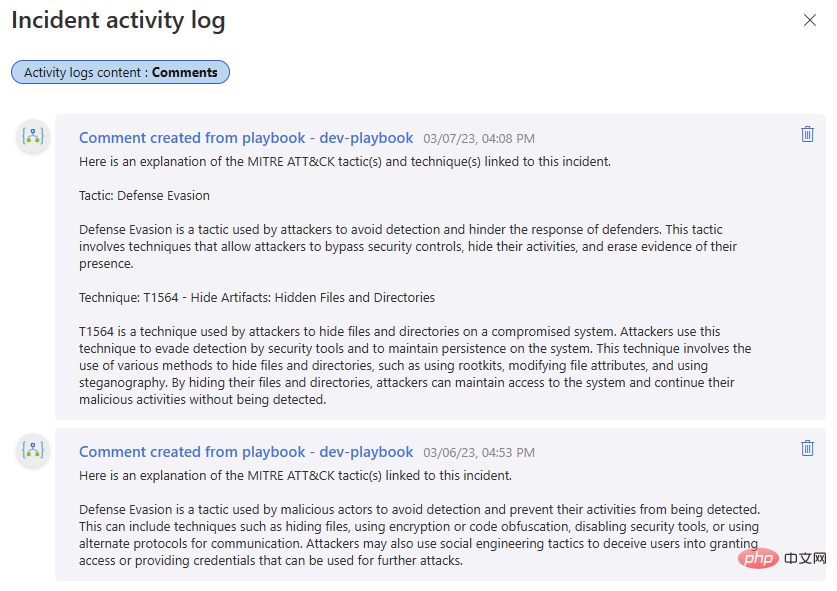
#Let's try it! I included comments from a previous iteration of this playbook in the first part of this OpenAI and Sentinel series - it's interesting to compare the output of DaVinci text completion with the Turbo model's chat interaction.
The above is the detailed content of OpenAI and Microsoft Sentinel Part 3: DaVinci and Turbo. For more information, please follow other related articles on the PHP Chinese website!