
 Technology peripheralsAIGoogle and MIT propose a unified framework MAGE: representation learning surpasses MAE, and unsupervised image generation surpasses Latent Diffusion
Technology peripheralsAIGoogle and MIT propose a unified framework MAGE: representation learning surpasses MAE, and unsupervised image generation surpasses Latent Diffusion
Recognition and generation are the two core tasks in the field of artificial intelligence. If they can be merged into a unified system, these two tasks should be complementary. In fact, in natural language processing, models like BERT [1] are not only able to generate high-quality text but also extract features from the text.
However, in the field of computer vision, current image generation models and recognition models are mostly trained separately, without fully utilizing the synergy of these two tasks. This is mainly due to the fact that the models of image generation and image recognition usually have essential structural differences: the input of image generation is low-dimensional features or noise, and the output is a high-dimensional original image; in contrast, the input of image recognition is high-dimensional. dimensional original image, while the output is low-dimensional features.
Recently, researchers from MIT and Google Research proposed a representation learning method based on image semantic masking, which for the first time achieved image generation and representation in a unified framework learned and achieved SOTA performance on multiple data sets. The research paper has been accepted by CVPR 2023, and the relevant code and pre-trained model have been open source.

- ##Paper address: https://arxiv.org/abs/2211.09117
- Code address: https://github.com/LTH14/mage
In CVPR 2022 On, MAE [2] proposed a representation learning method based on image masks (MIM) and achieved very good results on multiple subtasks. At a masking rate of up to 75%, MAE can reconstruct an image that closely matches the semantics of the original image, thereby allowing the network to self-supervisedly learn features in the image. However, as shown in Figure 1, although the image reconstructed by MAE has similar semantic information to the original image, serious blurring and distortion problems occur. Similar issues arise in all MIM-based representation learning methods. At the same time, current generative models, whether diffusion models or GANs, lack the ability to extract high-quality image features.

Figure 1: Comparison of MAE and MAGE reconstruction
Method OverviewIn response to the above problems, the author of this article proposed MAGE (Masked Generative Encoder), which for the first time realized a unified image generation and feature extraction model. Different from the masking method where MIM acts directly on the image, MAGE proposes a masked image token modeling method based on image semantic symbols. As shown in the figure, MAGE first uses the VQGAN [3] encoder to convert the original image into discrete semantic symbols. After that, MAGE randomly masks it and uses the transformer-based encoder-decoder structure to reconstruct the mask. The reconstructed semantic symbols can be used to generate the original image through the VQGAN decoder. By using different masking rates in training, MAGE can train both generative models (nearly 100% masking rate) and representation learning (50%-80% masking rate). As shown in Figure 1, the image reconstructed by MAGE not only has semantic information consistent with the original image, but can also ensure the diversity and authenticity of the generated image at the same time.

##Figure 2: MAGE Structure DiagramExperimental results
MAGE has reached or exceeded SOTA on multiple image generation and image recognition tasks.

In the unsupervised image generation task of ImageNet, the FID of MAGE dropped from the previous > 20 to 7.04, even reaching the level of supervised image generation (the FID of supervised Latent Diffusion on ImageNet is 3.60) :


picture 3: MAGE unsupervised image generation example
MAGE can also perform various image editing tasks, including image inpainting, outpainting, and uncropping:




#Figure 4: MAGE image editing sample
In In terms of representation learning, MAGE has greatly improved compared to the current MIM method in tasks such as ImageNet linear probing, few-shot learning, and transfer learning, and can reach or exceed the level of the current optimal self-supervised learning method.

This article aims to unify image generation and representation learning. To this end, the author of this article proposes MAGE, a self-supervised learning framework based on image semantic masking. This framework is simple and efficient, and for the first time reaches or exceeds SOTA performance in both image generation and representation learning. Interested readers can view the original text of the paper to learn more research details.
The above is the detailed content of Google and MIT propose a unified framework MAGE: representation learning surpasses MAE, and unsupervised image generation surpasses Latent Diffusion. For more information, please follow other related articles on the PHP Chinese website!

 谷歌三件套指的是哪三个软件Sep 30, 2022 pm 01:54 PM
谷歌三件套指的是哪三个软件Sep 30, 2022 pm 01:54 PM谷歌三件套指的是:1、google play商店,即下载各种应用程序的平台,类似于移动助手,安卓用户可以在商店下载免费或付费的游戏和软件;2、Google Play服务,用于更新Google本家的应用和Google Play提供的其他第三方应用;3、谷歌服务框架(GMS),是系统软件里面可以删除的一个APK程序,通过谷歌平台上架的应用和游戏都需要框架的支持。
 为什么中国不卖google手机Mar 30, 2023 pm 05:31 PM
为什么中国不卖google手机Mar 30, 2023 pm 05:31 PM中国不卖google手机的原因:谷歌已经全面退出中国市场了,所以不能在中国销售,在国内是没有合法途径销售。在中国消费市场中,消费者大都倾向于物美价廉以及功能实用的产品,所以竞争实力本就因政治因素大打折扣的谷歌手机主体市场一直不在中国大陆。
 谷歌超强AI超算碾压英伟达A100!TPU v4性能提升10倍,细节首次公开Apr 07, 2023 pm 02:54 PM
谷歌超强AI超算碾压英伟达A100!TPU v4性能提升10倍,细节首次公开Apr 07, 2023 pm 02:54 PM虽然谷歌早在2020年,就在自家的数据中心上部署了当时最强的AI芯片——TPU v4。但直到今年的4月4日,谷歌才首次公布了这台AI超算的技术细节。论文地址:https://arxiv.org/abs/2304.01433相比于TPU v3,TPU v4的性能要高出2.1倍,而在整合4096个芯片之后,超算的性能更是提升了10倍。另外,谷歌还声称,自家芯片要比英伟达A100更快、更节能。与A100对打,速度快1.7倍论文中,谷歌表示,对于规模相当的系统,TPU v4可以提供比英伟达A100强1.
 谷歌并未放弃TensorFlow,将于2023年发布新版,明确四大支柱Apr 12, 2023 am 11:52 AM
谷歌并未放弃TensorFlow,将于2023年发布新版,明确四大支柱Apr 12, 2023 am 11:52 AM2015 年,谷歌大脑开放了一个名为「TensorFlow」的研究项目,这款产品迅速流行起来,成为人工智能业界的主流深度学习框架,塑造了现代机器学习的生态系统。从那时起,成千上万的开源贡献者以及众多的开发人员、社区组织者、研究人员和教育工作者等都投入到这一开源软件库上。然而七年后的今天,故事的走向已经完全不同:谷歌的 TensorFlow 失去了开发者的拥护。因为 TensorFlow 用户已经开始转向 Meta 推出的另一款框架 PyTorch。众多开发者都认为 TensorFlow 已经输掉
 LLM之战,谷歌输了!越来越多顶尖研究员跳槽OpenAIApr 07, 2023 pm 05:48 PM
LLM之战,谷歌输了!越来越多顶尖研究员跳槽OpenAIApr 07, 2023 pm 05:48 PM前几天,谷歌差点遭遇一场公关危机,Bert一作、已跳槽OpenAI的前员工Jacob Devlin曝出,Bard竟是用ChatGPT的数据训练的。随后,谷歌火速否认。而这场争议,也牵出了一场大讨论:为什么越来越多Google顶尖研究员跳槽OpenAI?这场LLM战役它还能打赢吗?知友回复莱斯大学博士、知友「一堆废纸」表示,其实谷歌和OpenAI的差距,是数据的差距。「OpenAI对LLM有强大的执念,这是Google这类公司完全比不上的。当然人的差距只是一个方面,数据的差距以及对待数据的态度才
 参数少量提升,性能指数爆发!谷歌:大语言模型暗藏「神秘技能」Apr 11, 2023 pm 11:16 PM
参数少量提升,性能指数爆发!谷歌:大语言模型暗藏「神秘技能」Apr 11, 2023 pm 11:16 PM由于可以做一些没训练过的事情,大型语言模型似乎具有某种魔力,也因此成为了媒体和研究员炒作和关注的焦点。当扩展大型语言模型时,偶尔会出现一些较小模型没有的新能力,这种类似于「创造力」的属性被称作「突现」能力,代表我们向通用人工智能迈进了一大步。如今,来自谷歌、斯坦福、Deepmind和北卡罗来纳大学的研究人员,正在探索大型语言模型中的「突现」能力。解码器提示的 DALL-E神奇的「突现」能力自然语言处理(NLP)已经被基于大量文本数据训练的语言模型彻底改变。扩大语言模型的规模通常会提高一系列下游N
 四分钟对打300多次,谷歌教会机器人打乒乓球Apr 10, 2023 am 09:11 AM
四分钟对打300多次,谷歌教会机器人打乒乓球Apr 10, 2023 am 09:11 AM让一位乒乓球爱好者和机器人对打,按照机器人的发展趋势来看,谁输谁赢还真说不准。机器人拥有灵巧的可操作性、腿部运动灵活、抓握能力出色…… 已被广泛应用于各种挑战任务。但在与人类互动紧密的任务中,机器人的表现又如何呢?就拿乒乓球来说,这需要双方高度配合,并且球的运动非常快速,这对算法提出了重大挑战。在乒乓球比赛中,首要的就是速度和精度,这对学习算法提出了很高的要求。同时,这项运动具有高度结构化(具有固定的、可预测的环境)和多智能体协作(机器人可以与人类或其他机器人一起对打)两大特点,使其成为研究人
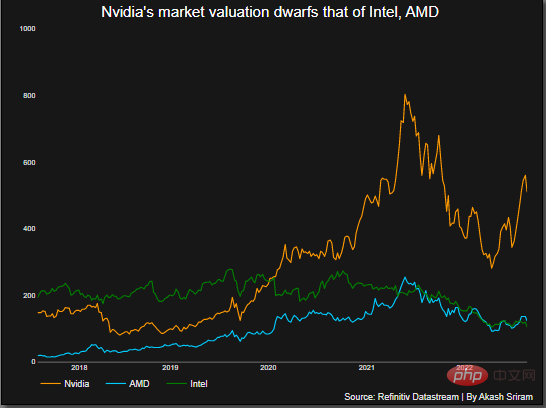 超5800亿美元!微软谷歌神仙打架,让英伟达市值飙升,约为5个英特尔Apr 11, 2023 pm 04:31 PM
超5800亿美元!微软谷歌神仙打架,让英伟达市值飙升,约为5个英特尔Apr 11, 2023 pm 04:31 PMChatGPT在手,有问必答。你可知,与它每次对话的计算成本简直让人泪目。此前,分析师称ChatGPT回复一次,需要2美分。要知道,人工智能聊天机器人所需的算力背后烧的可是GPU。这恰恰让像英伟达这样的芯片公司豪赚了一把。2月23日,英伟达股价飙升,使其市值增加了700多亿美元,总市值超5800亿美元,大约是英特尔的5倍。在英伟达之外,AMD可以称得上是图形处理器行业的第二大厂商,市场份额约为20%。而英特尔持有不到1%的市场份额。ChatGPT在跑,英伟达在赚随着ChatGPT解锁潜在的应用案


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

Dreamweaver CS6
Visual web development tools

WebStorm Mac version
Useful JavaScript development tools

