


Welcome to our series about OpenAI and Microsoft Sentinel! Large language models, or LLMs, such as OpenAI’s GPT3 family, are taking over the public imagination with innovative use cases such as text summarization, human-like conversations, code parsing and debugging, and many other examples. We've seen ChatGPT write screenplays and poems, compose music, write essays, and even translate computer code from one language to another.
What if we could harness this incredible potential to help incident responders in security operations centers? Well, of course we can – and it’s easy! Microsoft Sentinel already includes a built-in connector for OpenAI GPT3 models that we can implement in our automation playbooks powered by Azure Logic Apps. These powerful workflows are easy to write and integrate into SOC operations. Today we'll take a look at the OpenAI connector and explore some of its configurable parameters using a simple use case: describing a MITER ATT&CK policy related to Sentinel events.
Before we get started, let’s cover some prerequisites:
- If you don’t have a Microsoft Sentinel instance yet, you can create one using your free Azure account and follow Get started with Sentinel Get started quickly.
- We will use pre-recorded data from the Microsoft Sentinel Training Lab to test our playbook.
- You will also need a personal OpenAI account with an API key for GPT3 connections.
- I also highly recommend checking out Antonio Formato's excellent blog on handling events with ChatGPT and Sentinel, where Antonio introduces a very useful all-purpose manual that has been implemented in almost all OpenAI models in Sentinel to date refer to.
We will start with a basic incident trigger playbook (Sentinel > Automation > Create > Playbook with incident trigger).

Select the subscription and resource group, add a playbook name, and move to the Connections tab. You should see Microsoft Sentinel with one or two authentication options - I'm using Managed Identity in this example - but if you don't have any connections yet, you can also add a Sentinel connection in the Logic Apps Designer .
View and create the playbook, after a few seconds the resource will be deployed successfully and take us to the Logic App Designer canvas:

Let's add our OpenAI connector. Click New Step and type "OpenAI" in the search box. You'll see the connector in the top pane, and two actions below it: "Create Image" and "GPT3 Complete Your Prompt":

Select "GPT3 Complete your prompt". You will then be asked to create a connection to the OpenAI API in the following dialog box. If you haven't already, create a key at https://platform.openai.com/account/api-keys and make sure to keep it in a safe location!
Make sure you follow the instructions exactly when adding the OpenAI API key - it requires the word "Bearer", followed by a space, and then the key itself:

success! We now have GPT3 text completion ready for our prompt. We want to have the AI model interpret MITER ATT&CK strategies and techniques related to Sentinel events, so let's write a simple prompt using dynamic content to insert event strategies from Sentinel.

We're almost done! Save your logic app and go to Microsoft Sentinel Events to test run it. I have test data from Microsoft Sentinel Training Lab in my instance, so I will run this playbook against events triggered by malicious inbox rule alerts.

You may be wondering why we didn’t configure a second action in our playbook to add a comment or task with a result. We'll get there - but first we want to make sure our prompts return good content from the AI model. Return to the Playbook and open the Overview in a new tab. You should see an item in your run history, hopefully with a green checkmark:

Click the item to view details about the logic app run. We can expand any operation block to view detailed input and output parameters:

Our GPT3 operation took just two seconds to complete successfully. Let's click on the action block to expand it and see the full details of its inputs and outputs:

Let's take a closer look at the Select field in the Outputs section . This is where GPT3 returns the text of its completion along with the completion status and any error codes. I've copied the full text of the Choices output into Visual Studio Code:

Looks good so far! GPT3 correctly expands the MITER definition of "defense evasion." Before we add a logical action to the playbook to create an event comment with this answer text, let's take another look at the parameters of the GPT3 action itself. There are a total of nine parameters in the OpenAI text completion action, not counting engine selection and prompts:

What do these mean, and how do we adjust them to get the best results? To help us understand the impact of each parameter on the results, let's go to the OpenAI API Playground. We can paste the exact prompt in the input field where the logic app runs, but before clicking Submit we want to make sure the parameters match. Here's a quick table comparing parameter names between Azure Logic App OpenAI Connector and OpenAI Playground:
| Azure Logic App Connector | OpenAIPlayground | Explanation |
| Engine | Model | will generate the completed model. We can select Leonardo da Vinci (new), Leonardo da Vinci (old), Curie, Babbage or Ada in the OpenAI connector, corresponding to 'text-davinci-003', 'text-davinci-002', 'text respectively -curie-001' , 'text-babbage-001' and 'text-ada-001' in Playground. |
| n | N/A | How many completions to generate for each prompt. It is equivalent to re-entering the prompt multiple times in the Playground. |
| Best | (Same) | Generate multiple completions and return the best one. Use with caution - this costs a lot of tokens! |
| Temperature | (Same) | Defines the randomness (or creativity) of the response. Set to 0 for highly deterministic, repeated prompt completion where the model will always return its most confident choice. Set to 1 for maximum creative responses with more randomness, or somewhere in between if desired. |
| Maximum Tokens | Maximum Length | The maximum length of the ChatGPT response, given in token form. A token is approximately equal to four characters. ChatGPT uses token pricing; at the time of writing, 1000 tokens cost $0.002. The cost of an API call will include the hinted token length along with the reply, so if you want to keep the lowest cost per response, subtract the hinted token length from 1000 to cap the reply. |
| Frequency Penalty | (Same) | A number ranging from 0 to 2. The higher the value, the less likely the model is to repeat the line verbatim (it will try to find synonyms or restatements of the line). |
| There is a penalty | (Same) | A number between 0 and 2. The higher the value, the less likely the model is to repeat topics that have already been mentioned in the response. |
| Top | (Same) | Another way to set the response to "creativity" if you are not using temperature. This parameter limits the possible answer tokens based on probability; when set to 1, all tokens are considered, but smaller values reduce the set of possible answers to the top X%. |
| User | Not applicable | Unique identifier. We don't need to set this parameter because our API key is already used as our identifier string. |
| Stop | Stop Sequence | Up to four sequences will end the model's response. |
Let’s use the following OpenAI API Playground settings to match our logic application actions:
- Model: text-davinci-003
- Temperature: 1
- Maximum length: 100
This is the result we get from the GPT3 engine.

It looks like the response is truncated in the middle of the sentence, so we should increase the max length parameter. Otherwise, this response looks pretty good. We are using the highest possible temperature value - what happens if we lower the temperature to get a more certain response? Take a temperature of zero as an example:

At temperature=0, no matter how many times we regenerate this prompt, we get almost the exact same result. This works well when we ask GPT3 to define technical terms; there shouldn't be much difference in what "defensive evasion" means as a MITER ATT&CK tactic. We can improve the readability of responses by adding a frequency penalty to reduce the model's tendency to reuse the same words ("technical like"). Let's increase the frequency penalty to a maximum of 2:

So far we've only used the latest da Vinci models to get things done quickly. What happens if we drop down to one of OpenAI’s faster and cheaper models, such as Curie, Babbage, or Ada? Let's change the model to "text-ada-001" and compare the results:

Well... not quite. Let's try Babbage:

Babbage doesn't seem to return the results we're looking for either. Maybe Curie would be better off?

Sadly, Curie also didn’t meet the standards set by Leonardo da Vinci. They're certainly fast, but our use case of adding context to security events doesn't rely on sub-second response times - the accuracy of the summary is more important. We continue to use the successful combination of da Vinci models, low temperature and high frequency punishment.
Back to our Logic App, let’s transfer the settings we discovered from the Playground to the OpenAI Action Block:

Our Logic App is also Need to be able to write reviews for our events. Click "New Step" and select "Add Comment to Event" from the Microsoft Sentinel Connector:

We just need to specify the event ARM identifier and compose our comment message . First, search for "Event ARM ID" in the dynamic content pop-up menu:

Next, find the "Text" we output in the previous step. You may need to click See More to see the output. The Logic App Designer automatically wraps our comment action in a "For each" logic block to handle cases where multiple completions are generated for the same prompt.

Our completed Logic App should look something like the following:

Let’s test it out again! Go back to that Microsoft Sentinel event and run the playbook. We should get another successful completion in our Logic App run history and a new comment in our event activity log.
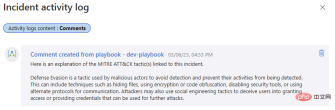
If you have been keeping in touch with us so far, you can now integrate OpenAI GPT3 with Microsoft Sentinel, which can add value to your security investigations . Stay tuned for our next installment, where we’ll discuss more ways to integrate OpenAI models with Sentinel, unlocking workflows that can help you get the most out of your security platform!
The above is the detailed content of Introduction to OpenAI and Microsoft Sentinel. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SublimeText3 English version
Recommended: Win version, supports code prompts!

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

