


Reference paper summary "NEURAL VOLUME RENDERING: NERF AND BEYOND", January 2021, co-authored by Georgia Tech and MIT.

Neural Rendering is defined as:
“A depth image or video generation method that allows explicit or implicit control of the scene Properties such as lighting, camera parameters, pose, geometry, appearance and semantic structure”.
It is a new data-driven solution that solves the long-standing problem of realistic rendering of virtual worlds in computer graphics.
Neural volume rendering refers to a method of generating images or videos by tracing rays into a scene and performing some kind of integration along the length of the rays. Typically, a neural network like a multilayer perceptron encodes functions from the 3D coordinates of light to density and color, etc., and integrates them to generate an image.
The direct pioneer work of neural volume rendering is the method of defining implicit surface representation using neural networks. Many 3D-aware image generation methods use voxels, grids, point clouds, or other representations, often based on convolutional architectures. But at CVPR 2019, at least three papers introduced the use of neural networks as scalar function approximations to define occupancy and/or signed distance functions (SDF).
- Occupancy networks introduce coordinate-based implicit occupancy learning. A network composed of 5 ResNet blocks, using feature vectors and 3D points as input, predicts binary occupancy.
- IM-NET uses a 6-layer MLP decoder to predict binary occupancy given feature vectors and 3D coordinates. Can be used for automatic encoding, shape generation (GAN-style) and single-view reconstruction.
- DeepSDF extracts the signed distance function directly from a 3D coordinate and a latent code. It uses an 8-layer MPL with hop connections to layer 4.
- PIFu shows that by reprojecting 3D points into pixel-aligned feature representations, particularly detailed implicit models can be learned. This is repeated in PixelNeRF, and the effect is very good.
Other approaches to employing implicit functions are:
- Structured Implicit Functions (2019) shows that it is possible to combine these implicit representations, for example, to simply sum.
- CvxNet (2020) combines signed distance functions by adopting pointwise Max (3D).
- The BSP Network (2020) is similar to CvxNet in many ways, but uses binary space partitioning at its core, resulting in a method of locally outputting polygonal meshes rather than through expensive meshing methods.
- Deep Local Shapes (2020) stores deep SDF latent codes in voxel grids to represent larger extended scenes.
- Scene Representation Networks (2019), or SRN, is very similar in architecture to DeepSDF, but adds a differentiable ray marching algorithm to find the nearest intersection point of the learned implicit surface, and adds MLP regression color, able to learn from multiple poses Learn from images.
- Differentiable Volumetric Rendering (2019) showed that implicit scene representations can be combined with differentiable renderers that can be trained from images, similar to SRN. The term "volume renderer" is used, but the real main contribution is a clever trick that makes the depth calculation of implicit surfaces differentiable: not integrating over the volume.
- Implicit Differentiable Renderer (2020) offers similar techniques but with a more sophisticated surface light field representation, showing that it can optimize camera poses during training.
- Neural Articulated Shape Approximation (2020) or NASA, composed of implicit functions to represent joint targets, such as the human body.
Not entirely out of thin air, although still warped voxel-based representation, the Neural Volumes paper introduces volume rendering for view synthesis, returning density and color to 3D volumes . The latent code is decoded into a 3D volume, and a new image is obtained through volume rendering.
It proposes using a volume representation composed of opacity and color at each position in 3D space, where rendering is achieved through integral projection. During the optimization process, this semi-transparent geometric representation disperses gradient information along the integration ray, effectively extending the convergence range and thus enabling the discovery of good solutions.
The paper that aroused everyone's discussion is the Neural Radiation Field NeRF paper (2020). Essentially, a deep SDF architecture is used, but instead of regressing the signed distance function (SDF), density and color are returned. Then, a (easily differentiable) numerical integration method is used to approximate the real volume rendering step.
The NeRF model stores the volume scene representation as the weights of the MLP and is trained on many images with known poses. New views are rendered by integrating density and color at regular intervals along each viewing ray.
One of the reasons for NeRF's very detailed rendering is the use of periodic activation functions, or Fourier features, to encode 3D points on a ray and the associated view direction. This innovation was later extended to multi-layer networks with periodic activation functions, namely SIREN (SInusoidal- REpresentation Networks). Both articles were published in NeurIPS 2020.
It can be said that the impact of the NeRF paper lies in its brutal simplicity: just one MLP outputs density and color in 5D coordinates. There are some bells and whistles, especially the positional encoding and stratified sampling scheme, but it's surprising that such a simple architecture can produce such impressive results. Still, original NeRF leaves many opportunities for improvement: both training and rendering are slow.
- can only represent static scenes.
- Fixed lighting.
- The trained NeRF representation does not generalize to other scenarios/objectives.
- Some projects/papers aim to improve the rather slow training and rendering times of the original NeRF paper.
JaxNeRF (2020) with JAX support (
- https://
- github.com/google/jax ) Multi-device training, changing from days to hours, greatly speeding up the process. AutoInt (2020) directly learns volume integrals, greatly speeding up rendering. Learned Initialization (2020) uses meta-learning to find good weight initialization and speed up training.
- DeRF (2020) decomposes the scene into a "soft Voronoi diagram", leveraging the accelerator memory architecture.
- NERF (2020) recommends using a separate NERF to model the background and handle infinite scenarios.
- Neural Sparse Voxel Fields (2020) organizes scenes into sparse voxel octrees, increasing rendering speed by 10x.
- At least four works focus on dynamic scenes:
Nerfies (2020) and its underlying D-NeRF model deformable video, using a second MLP Apply the warp to each frame of the video.
- D-NeRF (2020) is very similar to the Nerfies paper and even uses the same abbreviations, but seems to limit the transformation of translation.
- Neural Scene Flow Fields (2020) takes a monocular video with known camera pose as input, depth prediction as a prior, and outputs scene flow for regularization for use in the loss function.
- Spatial-Temporal Neural Irradiance Field (2020) uses only time as an additional input. To successfully train this method to render arbitrary viewpoint videos (from RGB-D data!), the loss function needs to be chosen carefully.
- NeRFlow (2020) uses deformation MLP to model scene flow and integrates across time domains to obtain the final deformation.
- NR NeRF (2020) also uses deformed MLP to model non-rigid scenes. It does not rely on precomputed scene information other than camera parameters, but produces slightly less clear output than Nerfies.
- STaR (2021) takes multi-view RGB video as input and decomposes the scene into static and dynamic volumes. However, currently it only supports one moving target.
- There are also two papers that focus on headshots/portraits of people.
PortraitNeRF (2020) Creates a static NeRF style avatar (Avatar), but captures the image with only one RGB. In order to achieve this, light stage training data is required.
- DNRF (G2020) focuses on 4D Avatar, incorporates deformed facial models into the pipeline, and imposes strong inductive bias.
- Another aspect where NeRF-style approaches have been enhanced is how lighting is handled, often through latent code that can be used to relight scenes.
NeRV (2020) supports arbitrary ambient lighting and "one bounce" indirect lighting with a second "visibility" MLP.
- NeRD (2020) is another work where a local reflection model is used and, moreover, for a given scene, low-resolution spherical harmonic illumination is removed.
- Neural Reflectance Fields (2020) improves NeRF by adding local reflection models, in addition to density. It produces impressive relighting results despite coming from a single point light source.
- NeRF-W (2020) is one of the first follow-ups to NeRF, optimizing the latent appearance code to be able to learn neural scene representations from less controlled multi-view collections.
- Latent codes can also be used to encode shape priors:
pixelNeRF (2020) is closer to image-based rendering, where N images are used at test time. It is based on PIFu, creating pixel-aligned features that are then interpolated when evaluating a NeRF-style renderer.
- GRF (2020) is very close to pixelNeRF in settings, but operates in norm space instead of view space.
- GRAF (2020), or "Generative Model for Radiation Fields," is a conditional variant of NeRF that adds appearance and shape latent codes while achieving viewpoint invariance through GAN-style training.
- pi GAN (2020), similar to GRAF, but uses a SIREN-style NeRF implementation in which each layer is modulated by a different MLP output using latent codes.
- Arguably, none of this scales to large scenes consisting of many targets, so an exciting new area is how to group targets into volume-rendered scenes.
- Object-Centric Neural Scene Rendering (2020) learns an “object scattering function” in an object-centric coordinate system, allowing synthetic scenes to be rendered and realistically illuminated using Monte Carlo.
- GIRAFFE (2020) supports synthesis by outputting feature vectors instead of colors from an object-centered NeRF model, which is then synthesized by averaging and rendered at low resolution into 2D feature maps, which are then upscaled in 2D sampling.
- Neural Scene Graphs (2020) supports multiple object-centric NeRF models in scene graphs.
- iNeRF (2020) uses NeRF MLP in a pose estimation framework and is even able to improve view synthesis on standard datasets by fine-tuning poses. However, it can't handle lighting yet.
Finally, at least one paper uses NeRF rendering in the context of (known) target pose estimation.
It is far from clear whether the neural body rendering and NeRF style papers will ultimately succeed. While smoke, haze, transparency, etc. do exist in the real world, ultimately most light is scattered from surfaces into the eye. NeRF-style networks may be easy to train due to the volume-based approach, but a trend has been seen where papers attempt to discover or guess surfaces after convergence. In fact, the stratified sampling scheme in the original NeRF paper is exactly this. Therefore, when learning from NeRF, one can easily see moving back to SDF-style implicit representations or even voxels, at least at inference time.
The above is the detailed content of Neural volume rendering: NeRF and beyond. For more information, please follow other related articles on the PHP Chinese website!

 10 Applications of LLM Agents for BusinessApr 13, 2025 am 09:34 AM
10 Applications of LLM Agents for BusinessApr 13, 2025 am 09:34 AMIntroduction Large language models or LLMs are a game-changer especially when it comes to working with content. From supporting summarization, translation, and generation, LLMs like GPT-4, Gemini, and Llama have made it simple
 How LLM Agents are Reshaping Workplace?Apr 13, 2025 am 09:33 AM
How LLM Agents are Reshaping Workplace?Apr 13, 2025 am 09:33 AMIntroduction Large language model (LLM) agents are the latest innovation boosting workplace business efficiency. They automate repetitive activities, boost collaboration, and provide useful insights across departments. Unlike
 Setup Mage AI with PostgresApr 13, 2025 am 09:31 AM
Setup Mage AI with PostgresApr 13, 2025 am 09:31 AMImagine yourself as a data professional tasked with creating an efficient data pipeline to streamline processes and generate real-time information. Sounds challenging, right? That’s where Mage AI comes in to ensure that the lende
 Is Google's Imagen 3 the Future of AI Image Creation?Apr 13, 2025 am 09:29 AM
Is Google's Imagen 3 the Future of AI Image Creation?Apr 13, 2025 am 09:29 AMIntroduction Text-to-image synthesis and image-text contrastive learning are two of the most innovative multimodal learning applications recently gaining popularity. With their innovative applications for creative image creati
 Top 10 YouTube Channels to Learn Excel - Analytics VidhyaApr 13, 2025 am 09:27 AM
Top 10 YouTube Channels to Learn Excel - Analytics VidhyaApr 13, 2025 am 09:27 AMIntroduction Excel is indispensable for boosting productivity and efficiency across all the fields. The wide range of resources on YouTube can help learners of all levels find helpful tutorials specific to their needs. This ar
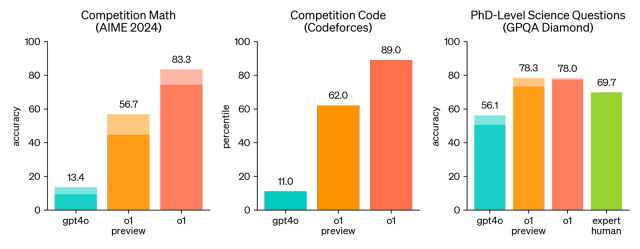 OpenAI o1: A New Model That 'Thinks' Before Answering ProblemsApr 13, 2025 am 09:26 AM
OpenAI o1: A New Model That 'Thinks' Before Answering ProblemsApr 13, 2025 am 09:26 AMHave you heard the big news? OpenAI just rolled out preview of a new series of AI models – OpenAI o1 (also known as Project Strawberry/Q*). These models are special because they spend more time “thinking” befor
 Claude vs Gemini: The Comprehensive Comparison - Analytics VidhyaApr 13, 2025 am 09:20 AM
Claude vs Gemini: The Comprehensive Comparison - Analytics VidhyaApr 13, 2025 am 09:20 AMIntroduction Within the quickly changing field of artificial intelligence, two language models, Claude and Gemini, have become prominent competitors, each providing distinct advantages and skills. Although both models can mana
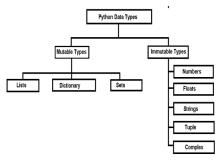 Mutable vs Immutable Objects in Python - Analytics VidhyaApr 13, 2025 am 09:15 AM
Mutable vs Immutable Objects in Python - Analytics VidhyaApr 13, 2025 am 09:15 AMIntroduction Python is an object-oriented programming language (or OOPs).In my previous article, we explored its versatile nature. Due to this, Python offers a wide variety of data types, which can be broadly classified into m


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

SublimeText3 Mac version
God-level code editing software (SublimeText3)

