

 Technology peripheralsAIAfter the emergence of super-large models, is the AI game over? Gary Marcus: The road is narrow
Technology peripheralsAIAfter the emergence of super-large models, is the AI game over? Gary Marcus: The road is narrow
In recent times, artificial intelligence technology has made breakthroughs in large models. Imagen proposed by Google yesterday once again triggered discussions about AI capabilities. Through pre-training learning from large amounts of data, the algorithm has unprecedented capabilities in building realistic images and understanding language.
In the eyes of many people, we are close to general artificial intelligence, but Gary Marcus, a well-known scholar and professor at New York University, does not think so.

Recently, his article "The New Science of Alt Intelligence" refuted DeepMind Research Director Nando de Freitas's view of "winning at scale". Let's take a look at him. How to say it.
The following is the original text of Gary Marcus:
For decades, there has been an assumption in the field of AI that artificial intelligence should draw inspiration from natural intelligence. John McCarthy wrote a seminal paper on why AI needs common sense - "Programs with Common Sense"; Marvin Minsky wrote the famous book "Society of Mind", trying to find inspiration from human thinking; because in behavioral economics Herb Simon, who won the Nobel Prize in Economics for his contributions, wrote the famous "Models of Thought", which aimed to explain "how newly developed computer languages can express theories of psychological processes so that computers can simulate predicted human behavior."
As far as I know, a large part of current AI researchers (at least the more influential ones) don't care at all. Instead, they are focusing more on what I call “Alt Intelligence” (thanks to Naveen Rao for his contribution to the term).
Alt Intelligence does not mean constructing machines that can solve problems in the same way as human intelligence, but rather using large amounts of data obtained from human behavior to replace intelligence. Currently, Alt Intelligence's main focus is scaling. Advocates of such systems argue that the larger the system, the closer we will get to true intelligence and even consciousness.
Study Alt Intelligence itself is nothing new, but the arrogance associated with it is.
For some time, I have seen some signs that the current artificial intelligence superstars, and even most people in the entire field of artificial intelligence, are dismissive of human cognition, ignoring or even mocking linguistics and cognitive psychology. Scholars in the fields of science, anthropology and philosophy.
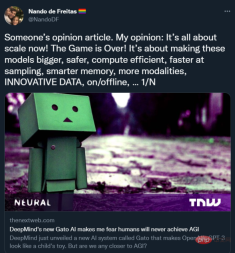
But this morning, I discovered a new tweet about Alt Intelligence. Nando de Freitas, the author of the tweet and director of research at DeepMind, declared that AI "is now all about scale." In fact, in his view (perhaps deliberately provocative with fiery rhetoric), the harder challenges in AI have already been solved. "Game over!" he said.
In essence, there is nothing wrong with pursuing Alt Intelligence.
Alt Intelligence represents an intuition (or a series of intuitions) about how to build intelligent systems. Since no one yet knows how to build systems that can match the flexibility and intelligence of human intelligence, it's fair game for people to pursue many different hypotheses about how to achieve this. Nando de Freitas defends this hypothesis as bluntly as possible, and I call it Scaling-Uber-Alles.
Of course, the name doesn't entirely do it justice. De Freitas is very clear that you can't just make the model bigger and expect success. People have been doing a lot of scaling lately and have had some great successes, but they've also encountered some obstacles. Before we dive into how De Freitas faces the status quo, let’s take a look at what the status quo looks like.
Status quo
Systems like DALL-E 2, GPT-3, Flamingo, and Gato seem confusing Exciting, but no one who has studied these models carefully would confuse them with human intelligence.
For example, DALL-E 2 can create realistic works of art based on text descriptions, such as "an astronaut riding a horse":

But It is also easy to make surprising mistakes. For example, when the text description is "a red square on a blue square", the generated result of DALL-E is as shown in the left picture, and the right picture is generated by the previous model result. Clearly, DALL-E's generation results are inferior to previous models.

When Ernest Davis, Scott Aaronson and I delved into this problem, we found many similar examples:
In addition, Flamingo, which looks amazing on the surface, also has its own bugs. As DeepMind senior research scientist Murray Shanahan pointed out in a tweet, Flamingo's lead author Jean-Baptiste Alayrac later added some examples. For example, Shanahan showed Flamingo this image:

and had the following flawed conversation surrounding the image:

It seems to be "made out of nothing".
Some time ago, DeepMind also released the multi-modal, multi-task, and multi-embodied "generalist" agent Gato, but when you look at the small print, you can still find unreliable places.

Of course, defenders of deep learning will point out that humans make mistakes.
But any honest person will realize that these errors indicate that something is currently defective. It's no exaggeration to say that if my kids were making mistakes like this on a regular basis, I would drop everything I'm doing and take them to a neurologist right away.
So, let’s be honest: Scaling isn’t working yet, but it’s possible, or so de Freitas’ theory—a clear expression of the zeitgeist—is.
Scaling-Uber-Alles
So how does de Freitas reconcile reality with ambition? In fact, billions of dollars have now been invested in Transformer and many other related areas, training data sets have expanded from megabytes to gigabytes, and parameter sizes have expanded from millions to trillions. However, puzzling errors that have been documented in detail in numerous works since 1988 remain.
For some (like myself), the existence of these problems may mean that we need to undergo fundamental rethinking, such as those pointed out by Davis and me in "Rebooting AI". But for de Freitas, this is not the case (many other people may also hold the same idea as him, I am not trying to single him out, I just think his remarks are more representative).
In the tweet, he elaborated on his views on reconciling reality with current problems, "(We need to) make models larger, safer, more computationally efficient, faster to sample, and more efficient to store. There are more intelligence and modes, and we also need to study data innovation, online/offline, etc.” The point is, none of the words come from cognitive psychology, linguistics or philosophy (maybe smarter memory can barely count).
In a follow-up post, de Freitas also said:
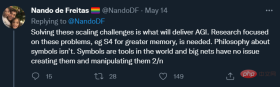
This once again confirms his statement that "scale is greater than all else" and shows that One goal: Its ambition is not just better AI, but AGI.
AGI stands for Artificial General Intelligence, which is at least as good, as resourceful and broadly applicable as human intelligence. The narrow sense of artificial intelligence we currently realize is actually alternative intelligence (alt intelligence), and its iconic successes are games such as chess (Deep Blue has nothing to do with human intelligence) and Go (AlphaGo has little to do with human intelligence). De Freitas has more ambitious goals, and to his credit, he's been very candid about them. So, how does he achieve his goal? To reiterate here, de Freitas focuses on technical tools for accommodating larger data sets. Other ideas, such as those from philosophy or cognitive science, may be important but are excluded.
He said, "The philosophy of symbols is not necessary." Perhaps this is a rebuttal to my long-standing movement to integrate symbolic manipulation into cognitive science and artificial intelligence. The idea resurfaced recently in Nautilus magazine, although it was not fully elaborated. Here is my brief response: What he said "[neural] nets have no issue creating [symbols] and manipulating them" ignores both history and reality. What he ignores is the history that many neural network enthusiasts have resisted symbols for decades; he ignores the reality that symbolic descriptions like the aforementioned "red cube on a blue cube" can still stump the minds of 2022 SOTA model.
At the end of the tweet, De Freitas expressed his approval of Rich Sutton's famous article "Bitter Lessons":
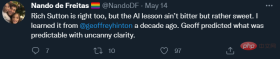
Sutton’s argument is that the only thing that will lead to progress in artificial intelligence is more data, more efficient computation. In my opinion, Sutton is only half right, his description of the past is almost correct, but his inductive predictions of the future are unconvincing.
So far, big data has (temporarily) defeated well-designed knowledge engineering in most fields (certainly not all fields).
But nearly all the software in the world, from web browsers to spreadsheets to word processors, still relies on knowledge engineering, and Sutton ignored this. For example, Sumit Gulwani's excellent Flash Fill feature is a very useful one-time learning system that is not built on the premise of big data at all, but on classic programming techniques.
I don’t think any pure deep learning/big data system can match this.
In fact, the key problems with artificial intelligence that cognitive scientists like Steve Pinker, Judea Pearl, Jerry Fodor, and myself have been pointing out for decades have actually not yet been solved. Yes, machines can play games very well, and deep learning has made huge contributions in areas such as speech recognition. But no artificial intelligence currently has enough understanding to recognize any text and build a model that can speak normally and complete tasks, nor can it reason and produce a cohesive response like the computers in the "Star Trek" movies.
We are still in the early stages of artificial intelligence.
Success on some problems using specific strategies does not guarantee that we will solve all problems in a similar way. It would be simply foolish not to realize this, especially when some of the failure modes (unreliability, strange bugs, combinatorial failures, and incomprehension) remain unchanged since Fodor and Pinker pointed them out in 1988. Conclusion
It’s nice to see that Scaling-Über-Alles is not yet fully agreed upon, even at DeepMind:

I Completely agree with Murray Shanahan: "I see very little in Gato to suggest scaling alone will get us to human-level generalization."
Let's encourage a field that's open-minded enough that people can take their own work in many directions without prematurely discarding ideas that happen to not be fully developed yet. After all, the best path to (general) artificial intelligence may not be Alt Intelligence.
As mentioned earlier, I'd love to think of Gato as an "alternative intelligence" - an interesting exploration of alternative ways to build intelligence, but we need to put it in perspective: it won't work like a brain, it will It doesn’t learn like a child, it doesn’t understand language, it doesn’t align with human values, and it can’t be trusted to complete critical tasks.
It might be better than anything else we have right now, but it still doesn't really work, and even after investing heavily in it, it's time to give it a pause.
It should take us back to the era of artificial intelligence startups. Artificial intelligence certainly shouldn’t be a blind copy of human intelligence. After all, it has its own flaws, saddled with poor memory and cognitive biases. But it should look to human and animal cognition for clues. The Wright brothers didn't imitate birds, but they learned something about their flight control. Knowing what we can learn from and what we cannot learn from may be more than half of our success.
I think the bottom line is, what AI once valued but no longer pursues: If we are going to build AGI, we are going to need to learn something from humans - how they reason and understand the physical world, and How they represent and acquire language and complex concepts.
It would be too arrogant to deny this idea.
The above is the detailed content of After the emergence of super-large models, is the AI game over? Gary Marcus: The road is narrow. For more information, please follow other related articles on the PHP Chinese website!

 Steam 未检测到 Windows 11/10 中已安装的游戏,如何修复Jun 27, 2023 pm 11:47 PM
Steam 未检测到 Windows 11/10 中已安装的游戏,如何修复Jun 27, 2023 pm 11:47 PMSteam客户端无法识别您计算机上的任何游戏吗?当您从计算机上卸载Steam客户端时,会发生这种情况。但是,当您重新安装Steam应用程序时,它会自动识别已安装文件夹中的游戏。但是,别担心。不,您不必重新下载计算机上的所有游戏。有一些基本和一些高级解决方案可用。修复1–尝试在同一位置安装游戏这是解决这个问题的最简单方法。只需打开Steam应用程序并尝试在同一位置安装游戏即可。步骤1–在您的系统上打开Steam客户端。步骤2–直接进入“库”以查找您拥有的所有游戏。第3步–选择游戏。它将列在“未分类
 欢乐追逃游戏即将开始!亚瑟和安琪拉520限定皮肤震撼登场!May 19, 2023 pm 08:23 PM
欢乐追逃游戏即将开始!亚瑟和安琪拉520限定皮肤震撼登场!May 19, 2023 pm 08:23 PM5月18日消息,为了庆祝即将到来的520节日,《王者荣耀》推出了令人期待的活动和全新限定皮肤。这次的活动将带来一场名为"追逃游戏"的欢乐庆典,而亚瑟和安琪拉将成为主角,以传说品质的520限定皮肤惊艳登场。据ITBEAR科技资讯了解,亚瑟和安琪拉是《王者荣耀》中备受喜爱的英雄角色,他们以各自独特的魅力和技能征服了众多玩家。而这次的520限定皮肤让他们焕发出全新的魅力,给玩家们带来不一样的游戏体验。安琪拉520限定皮肤以马戏团为主题,她身穿充满节日氛围的撞色裙子,伴随着皮皮精灵的
 电脑游戏下载到d盘还是c盘Mar 16, 2023 pm 03:02 PM
电脑游戏下载到d盘还是c盘Mar 16, 2023 pm 03:02 PM电脑游戏下载到d盘。C盘是系统盘,是专门为安装系统而设置的磁盘空间,里面安装的东西越少越好;C盘安装的东西多,电脑就会很卡。C盘系统运行会产生很多缓存与磁盘碎片,这些都会影响系统的运行及速度;如果再安装游戏或者软件,会更加加速缓存与碎片产生的数量与速度。
 用Python写游戏脚本原来这么简单Apr 13, 2023 am 10:04 AM
用Python写游戏脚本原来这么简单Apr 13, 2023 am 10:04 AM前言最近在玩儿公主连结,之前也玩儿过阴阳师这样的游戏,这样的游戏都会有个初始号这样的东西,或者说是可以肝的东西。当然,作为一名程序员,肝这种东西完全可以用写代码的方式帮我们自动完成。游戏脚本其实并不高深,最简单的体验方法就是下载一个Airtest了,直接截几个图片,写几层代码,就可以按照自己的逻辑玩儿游戏了。当然,本篇文章不是要讲Airtest这个怎么用,而是用原始的python+opencv来实现上面的操作。这两天我写了一个公主连结刷初始号的程序,也不能算写游戏脚本的老手,这篇文章主要是分享一
 Win11玩游戏卡顿怎么解决Jun 29, 2023 pm 01:20 PM
Win11玩游戏卡顿怎么解决Jun 29, 2023 pm 01:20 PMWin11玩游戏卡顿怎么解决?近期有用户给自己的电脑升级了Win11系统,但是在后续在使用电脑玩游戏时,游戏却出现了卡顿掉帧的情况,这是这怎么回事呢?出现这一情况的原因有很多,下面小编为大家带来了几种方法解决,我们一起来看看吧。 Win11玩游戏卡顿掉帧的解决方法 一、散热 1、有些设备在温度过高时,会通过降频的方法来降低温度。 2、这时候可以先打开系统设置,在左上角搜索电源,点击显示所有结果。 3、然后在下拉列表中打开选择电源计划。 4、再勾选开启高性能模式即可。 5、如果高
 win7玩游戏怎么优化可以让游戏更加流畅Jul 02, 2023 pm 01:53 PM
win7玩游戏怎么优化可以让游戏更加流畅Jul 02, 2023 pm 01:53 PMwin7玩游戏怎么优化可以让游戏更加流畅?如果你喜欢使用电脑来玩一些比较大型的游戏,那么就可以对你的电脑进行系统的优化。优化之后可以更好的发挥出电脑硬件的性能,获得更高的流畅性,玩游戏时获得更好的游戏体验。win7玩游戏优化可以让游戏更加流畅方法 1、在桌面上找到计算机,右键选中它并点击属性。 2、在系统属性面板中找到高级系统设置。 3、找到性能设置。 4、勾选让windows选择计算机的数值设置。以上就是【win7玩游戏怎么优化可以让游戏更加流畅-win7玩游戏优化可以让游戏更加流
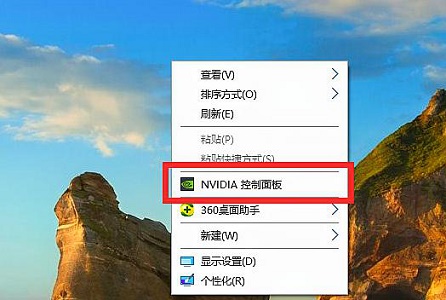 Win7游戏帧数优化方法Jul 15, 2023 am 08:05 AM
Win7游戏帧数优化方法Jul 15, 2023 am 08:05 AM针对游戏游戏玩家来讲,游戏的帧率针对游戏的流畅性、可操作性感受全是十分核心的。客户不仅仅可以根据更新配备来提升游戏帧数,变更显卡设置还可以保证相同的实际效果。下边咱们就一起来看看详细的方式吧。游戏帧数优化技术:1、鼠标右键桌面上空白,开启“NVIDIA操作面板”。2、挑选“配备Surround、PhysX”。3、启用图例部位,随后将下边滚轮拉到特性部位。4、还能够点一下“管理方法3D设定”5、将垂直同步关掉,如下图所示。6、再将三重缓冲关掉。7、通过以上的提升,大家就可以在玩游戏时得到更高的帧率
 golang能不能做游戏Jul 10, 2023 pm 01:15 PM
golang能不能做游戏Jul 10, 2023 pm 01:15 PMgolang能做游戏,但是不适合做游戏。golang适合处理日志、数据打包、虚拟机处理、文件系统、分布式系统、数据库代理等;网络编程方面,golang广泛应用于Web应用、API应用、下载应用等。


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

Dreamweaver CS6
Visual web development tools

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

