

 Technology peripheralsAIMeta releases the first 'non-parametric' mask language model NPM: beating GPT-3 with 500 times the number of parameters
Technology peripheralsAIMeta releases the first 'non-parametric' mask language model NPM: beating GPT-3 with 500 times the number of parameters
Although the powerful performance of large language models in the NLP field is amazing, the negative costs it brings are also serious, such as training is too expensive and difficult to update. , and it is difficult to deal with long-tail knowledge.
And language models usually use a softmax layer containing a limited vocabulary in the prediction layer, which basically does not output rare words or phrases, which greatly limits the expression ability of the model.
In order to solve the long-tail problem of the model, scholars from the University of Washington, Meta AI and the Allen Institute for Artificial Intelligence recently jointly proposed the first "NonParametric Masked language model" (NonParametric Masked language model, NPM), which replaces the softmax output by referring to the non-parametric distribution of each phrase in the corpus.

Paper link: https://arxiv.org/abs/2212.01349
Code link: https://github.com/facebookresearch/NPM
NPM can be effectively trained by contrastive objective and intra-batch approximation of retrieving the complete corpus.
The researchers conducted a zero-shot evaluation on nine closed tasks and seven open tasks, including spatiotemporal transformation and word-level translation tasks that emphasize the need to predict new facts or rare phrases.
The results show that regardless of whether retrieval and generation methods are used, NPM is significantly better than larger parameter models. For example, GPT-3 with 500 times more parameters and OPT 13B with 37 times more performance are much better. , and NPM is particularly good at handling rare patterns (word meanings or facts) and predicting rare or barely seen words (such as non-Latin scripts).
The first non-parametric language model
Although this problem can be alleviated by combining some existing retrieval-and-generate related work, the final prediction part of these models A softmax layer is still needed to predict tokens, which does not fundamentally solve the long tail problem.
NPM consists of an encoder and a reference corpus. The encoder maps the text into a fixed-size vector, and then NPM retrieves a phrase from it and fills in [MASK].

As you can see, NPM chooses the non-parametric distribution obtained on the phrases instead of using a fixed output vocabulary softmax as the output.
But training non-parametric models also brings two key problems:
1. Retrieving the complete corpus during the training process is very time-consuming and labor-intensive. Researchers have used Learning to predict phrases of arbitrary length without a decoder is difficult, and researchers solve this problem by extending span masking and phrase-level comparison goals .
In short, NPM completely removes the softmax of the output vocabulary and achieves an effective unbounded output space by predicting any number of n-grams.
The resulting model can predict "extremely rare" or even "completely unseen" words (such as Korean words), and can effectively support unlimited vocabulary sizes, which existing models cannot make it happen.
NPM Method
The key idea of NPM is to use an encoder to map all phrases in the corpus into a dense vector space. At inference time, when given a query with [MASK], use the encoder to find the nearest phrase from the corpus and fill in [MASK].
Pure encoder (Encoder-only) model is a very competitive representation model, but existing pure encoding models cannot make predictions with an unknown number of tokens, making their use without fine-tuning are restricted.
NPM solves this problem by retrieving a phrase to fill any number of tokens in [MASK].
InferenceThe encoder maps each distinct phrase in the reference corpus C into a dense vector space.
At test time, the encoder maps the masked query into the same vector space and fills [MASK] with phrases retrieved from C.
Here, C does not have to be the same as the training corpus and can be replaced or extended at test time without retraining the encoder.
In practice, there are a large number of phrases in the corpus, and indexing all of them is expensive.
For example, if we consider a phrase with at most l tokens (l≈20), we need to index l×|C| number of vectors, which may be time-consuming.
 The researchers indexed each distinct token in C, thereby reducing the size of the index from l×|C| to |C|, and then when testing, The non-parametric distribution of all phrases is approximated by performing k-nearest neighbor searches separately for the beginning and the end.
The researchers indexed each distinct token in C, thereby reducing the size of the index from l×|C| to |C|, and then when testing, The non-parametric distribution of all phrases is approximated by performing k-nearest neighbor searches separately for the beginning and the end.
For example, the phrase Thessaloniki composed of 4 BPE tokens is represented by the connection of c1 and c4, which correspond to the beginning (The) and the end (iki) of the phrase respectively.
Then use two vectors q_start and q_end in the same vector space to represent a query, and then use each vector to retrieve the start and end of plausible phrases before aggregating.
The premise of doing this is that the representation of the beginning and the end is good enough, that is, the starting point of q is close enough to c1, and the end point of q is close enough to c4, and this has been ensured during the training process.
Training
NPM is trained on unlabeled text data to ensure that the encoder maps the text into a good dense vector space.
There are two main problems in training NPM: 1) Complete corpus retrieval will make training very time-consuming; 2) Filling [MASK] with phrases of arbitrary length instead of tokens.
1. Masking Masking
Span masking is to mask continuous tokens whose lengths are sampled from a geometric distribution.
The researchers expanded on this:
1) If some fragments co-occur in other sequences in the batch, they are then masked to ensure that within the batch during training Positive examples (in-batch positives).

For example, the blocked clips 2010, the Seattle Seahawks, and to the all co-occur in another sequence.
But for the bigram "game," they cannot be masked together. Although they also appear in two sequences, they do not co-occur together.
2) Instead of replacing each token in the fragment with [MASK], replace the entire fragment with two special tokens [MASKs][MASKe].
For example, in the above example, regardless of the length of the masked segment, it is replaced with [MASKs][MASKe], so that the start and end vectors of each segment can be obtained, making reasoning more convenient.
2. Training target

Assuming that the masked clip is the Seattle Seahawks, during testing, the model should learn from the reference corpus The phrase the Seattle Seahawks was retrieved from other sequences of .
In the inference stage, the model obtains vectors from [MASKs] and [MASKe] and uses them to retrieve the beginning and end of the phrase from the corpus respectively.
Therefore, the training goal should encourage the vector of [MASKs] to be closer to the in the Seattle Seahawks and farther away from other tokens, and should not be the the in any phrase, such as become the in first.
We do this by training the model to approximate the full corpus to other sequences in the batch. Specifically, we train the model to retrieve the starting point of the Seattle Seahawks segment from other sequences in the same batch. and end point.
It should be noted that this mask strategy ensures that each masked span has a co-occurring segment in a batch.
Experimental part
From the results, NPM performs better than other baseline models under the zero-shot setting.

Among the parametric models, RoBERTa achieved the best performance, unexpectedly surpassing models including GPT-3, probably because of the pure encoder model The bidirectionality plays a crucial role, which also suggests that causal language models may not be a suitable choice for classification.
The kNN-LM method adds non-parametric components to the parametric model, and its performance is better than all other baselines. Nonetheless, relying solely on retrieval (kNN) performs poorly in GPT-2, indicating the limitations of using kNN only at inference time.
NPM SINGLE and NPM both significantly outperformed all baselines, achieving consistently superior performance on all datasets. This shows that non-parametric models are very competitive even for tasks that do not explicitly require external knowledge.
Qualitative analysis uses the prediction results of RoBERTa and NPM in sentiment analysis tasks. In the first example, cheap means not expensive, and in the second example, cheap means poor quality.

RoBERTa’s predictions for both examples were positive, while NPM made the correct prediction by retrieving contexts where cheap was used in the same context as the input Prediction.
It can also be found that the representation output by NPM can bring better word meaning disambiguation. For example, RoBERTa assigns a high similarity score between cheap and cheap.
On the other hand, NPM successfully assigns a low similarity score between cheap and cheap, which also shows that this non-parametric training with contrastive objectives is effective and can better improve representation learning, while kNN inference This kind of algorithm without training is completely impossible.
Reference: https://arxiv.org/abs/2212.01349
The above is the detailed content of Meta releases the first 'non-parametric' mask language model NPM: beating GPT-3 with 500 times the number of parameters. For more information, please follow other related articles on the PHP Chinese website!

 顺手训了一个史上超大ViT?Google升级视觉语言模型PaLI:支持100+种语言Apr 12, 2023 am 09:31 AM
顺手训了一个史上超大ViT?Google升级视觉语言模型PaLI:支持100+种语言Apr 12, 2023 am 09:31 AM近几年自然语言处理的进展很大程度上都来自于大规模语言模型,每次发布的新模型都将参数量、训练数据量推向新高,同时也会对现有基准排行进行一次屠榜!比如今年4月,Google发布5400亿参数的语言模型PaLM(Pathways Language Model)在语言和推理类的一系列测评中成功超越人类,尤其是在few-shot小样本学习场景下的优异性能,也让PaLM被认为是下一代语言模型的发展方向。同理,视觉语言模型其实也是大力出奇迹,可以通过提升模型的规模来提升性能。当然了,如果只是多任务的视觉语言模
 大规模语言模型高效参数微调--BitFit/Prefix/Prompt 微调系列Oct 07, 2023 pm 12:13 PM
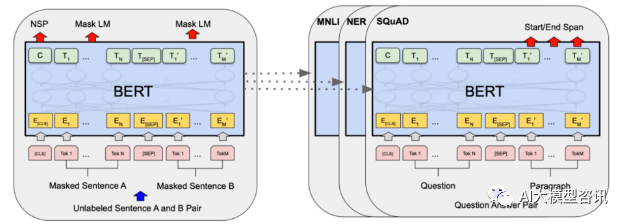
大规模语言模型高效参数微调--BitFit/Prefix/Prompt 微调系列Oct 07, 2023 pm 12:13 PM2018年谷歌发布了BERT,一经面世便一举击败11个NLP任务的State-of-the-art(Sota)结果,成为了NLP界新的里程碑;BERT的结构如下图所示,左边是BERT模型预训练过程,右边是对于具体任务的微调过程。其中,微调阶段是后续用于一些下游任务的时候进行微调,例如:文本分类,词性标注,问答系统等,BERT无需调整结构就可以在不同的任务上进行微调。通过”预训练语言模型+下游任务微调”的任务设计,带来了强大的模型效果。从此,“预训练语言模型+下游任务微调”便成为了NLP领域主流训
 RoSA: 一种高效微调大模型参数的新方法Jan 18, 2024 pm 05:27 PM
RoSA: 一种高效微调大模型参数的新方法Jan 18, 2024 pm 05:27 PM随着语言模型扩展到前所未有的规模,对下游任务进行全面微调变得十分昂贵。为了解决这个问题,研究人员开始关注并采用PEFT方法。PEFT方法的主要思想是将微调的范围限制在一小部分参数上,以降低计算成本,同时仍能实现自然语言理解任务的最先进性能。通过这种方式,研究人员能够在保持高性能的同时,节省计算资源,为自然语言处理领域带来新的研究热点。RoSA是一种新的PEFT技术,通过在一组基准测试的实验中,发现在使用相同参数预算的情况下,RoSA表现出优于先前的低秩自适应(LoRA)和纯稀疏微调方法。本文将深
 Meta 推出 AI 语言模型 LLaMA,一个有着 650 亿参数的大型语言模型Apr 14, 2023 pm 06:58 PM
Meta 推出 AI 语言模型 LLaMA,一个有着 650 亿参数的大型语言模型Apr 14, 2023 pm 06:58 PM2月25日消息,Meta在当地时间周五宣布,它将推出一种针对研究社区的基于人工智能(AI)的新型大型语言模型,与微软、谷歌等一众受到ChatGPT刺激的公司一同加入人工智能竞赛。Meta的LLaMA是“大型语言模型MetaAI”(LargeLanguageModelMetaAI)的缩写,它可以在非商业许可下提供给政府、社区和学术界的研究人员和实体工作者。该公司将提供底层代码供用户使用,因此用户可以自行调整模型,并将其用于与研究相关的用例。Meta表示,该模型对算力的要
 BLOOM可以为人工智能研究创造一种新的文化,但挑战依然存在Apr 09, 2023 pm 04:21 PM
BLOOM可以为人工智能研究创造一种新的文化,但挑战依然存在Apr 09, 2023 pm 04:21 PM译者 | 李睿审校 | 孙淑娟BigScience研究项目日前发布了一个大型语言模型BLOOM,乍一看,它看起来像是复制OpenAI的GPT-3的又一次尝试。 但BLOOM与其他大型自然语言模型(LLM)的不同之处在于,它在研究、开发、培训和发布机器学习模型方面所做的努力。近年来,大型科技公司将大型自然语言模型(LLM)就像严守商业机密一样隐藏起来,而BigScience团队从项目一开始就把透明与开放放在了BLOOM的中心。 其结果是一个大型语言模型,可以供研究和学习,并可供所有人使用。B
 大学生用GPT-3写论文遭重罚,拒不承认!大学论文已「死」,ChatGPT或引发学术圈大地震Apr 11, 2023 pm 10:01 PM
大学生用GPT-3写论文遭重罚,拒不承认!大学论文已「死」,ChatGPT或引发学术圈大地震Apr 11, 2023 pm 10:01 PMChatGPT诞生之后,用自己强悍的文本创作能力,不断刷新着我们的认知。AI即将给大学校园带来怎样的爆炸性改变?似乎还没人做好准备。Nature已经发文,担心ChatGPT会成为学生写论文的工具。文章链接:https://www.nature.com/articles/d41586-022-04397-7无独有偶,一位加拿大作家Stephen Marche痛心疾首地呼吁:大学的论文已死!用AI写论文,太容易了假设你是一位教育学教授,你为学术布置了一篇关于学习风格的论文。一位学生提交了一篇文章,开
 她用10年日记训练GPT-3,对话童年的自己,网友:AI最治愈的应用Apr 12, 2023 pm 04:25 PM
她用10年日记训练GPT-3,对话童年的自己,网友:AI最治愈的应用Apr 12, 2023 pm 04:25 PM“这是我目前听过关于AI最好、最治愈的一个应用。”到底是什么应用,能让网友给出如此高度的评价?原来,一个脑洞大开的网友Michelle,用GPT-3造了一个栩栩如生的“童年Michelle”。然后她和童年的自己聊起了天,对方甚至还写来一封信。“童年Michelle”的“学习资料”也很有意思——是Michelle本人的日记,而且是连续十几年,几乎每天都写的那种。日记内容中有她的快乐和梦想,也有恐惧和抱怨;还有很多小秘密,包括和Crush聊天时紧张到眩晕…(不爱写日记的我真的给跪了……)厚厚一叠日记
 如何用 Python 玩转 ChatGPTApr 11, 2023 am 11:28 AM
如何用 Python 玩转 ChatGPTApr 11, 2023 am 11:28 AMChatGPT 月活过亿,作为 OpenAI 开发的一种大型自然语言处理模型,ChatGPT 可以根据用户输入生成相应的文本回复,还会关联上下文,非常智能。作为一名 Python 爱好者,我们可以通过调用 OpenAI API 来实现与 ChatGPT 的交互。本文告诉你方法。首先 ChatGPT 还没有正式公开 API,目前下面的方法也仅仅是测试,但是使用起来没有任何问题,感兴趣的可以关注官网[1]更新。1、获取 API Key首先,你需要在 OpenAI 官网注册账号并获取 API Key,


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

SublimeText3 Mac version
God-level code editing software (SublimeText3)

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

Zend Studio 13.0.1
Powerful PHP integrated development environment

