

 Backend DevelopmentPython TutorialPractical summary of using Python to quickly build interface automated test scripts
Backend DevelopmentPython TutorialPractical summary of using Python to quickly build interface automated test scripts
Introduction to test requirements
Usually, in our projects, our interface test requirements are generally to construct different request data, and then send the request to the interface. After getting the interface return, we will The fields are extracted and verified, and finally the results are stored in an excel table for easy reference. The interface is generally an http or https request, and the structure sent is generally json body or json combined with some file attachments. The return results of the request are all in json format. Our test cases can be saved in Excel or database, and the results can be saved in the database or exist directly. In Excel, the following will specifically dismantle the requirements and introduce the implementation process step by step.
Customizing the request body and sending the request
Constructing the request content sent each time and automatically sending the request to the interface is the core of constructing the automated test script. We mainly use python to implement this step requests library, let’s give a detailed introduction below.
1. Send a simple http post request
Before sending the request, we need to clarify the body of the request. Our body is json. The specific content is as follows:

We can save this as a text.json file as a template, which can be read directly to prepare for later construction of the request body. We can handle this step like this. With the help of the yaml package, we can convert json into a dictionary, or we can use the json that comes with python, and the effect is the same.

After obtaining the request body template, we get the variable request_body, which is a dictionary type data. We can parameterize it to construct what we need The request body. For example, if we want to modify the request id, user name, and text content of each request, we can do this. The left side is the field that needs to be modified, and the right side is the variable we need.

After constructing the data to be sent, you can prepare to send the request. Before sending the request, we still have some work to do, which is to set some parameters of the request interface and Some customization of request headers, here we give a simple example as follows:

# After we customize the request parameters and request headers, we can send a request similar to the following URL:

We add the previously constructed body, and then use the post method of the requests library to send the request. The data parameter in the method is used here. It receives a json, so when sending Previously, the previous dictionary variables needed to be converted before sending. Here we use the json library that comes with Python, and use the dumps method to convert the dictionary to json:

At this point, a basic http post request has been sent. Note that we have a Response object named r. We can get all the information we want from this object.
2. More complex requests
We introduced the simplest http post request earlier. On this basis, we sometimes need some more complex requests, such as bringing a file, https Request, etc. Here is a brief explanation of how to implement it:
For example, we want to send an audio file with the format pcm to the interface, and the interface is https.
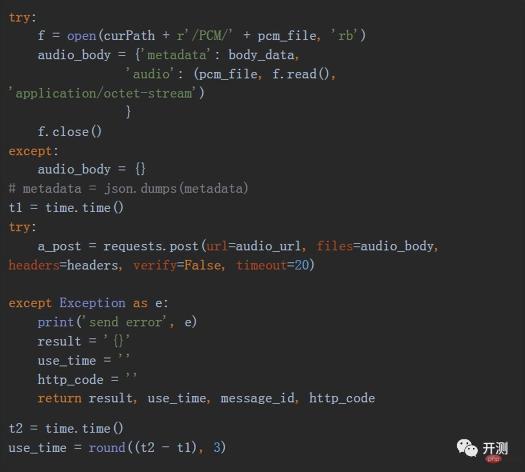
Note that sending https requests requires SSL authentication. Use the verify parameter in the method. The default value of this parameter is True. Generally, if verification is not required, you need to set this is False. Another thing to note is that we set a timeout to prevent the request process from timing out and causing the program to become unresponsive.
Capture key data from the request return data
In the step of sending the request, we have a Response object named r. We can get all the information we want from this object.
There are several methods to obtain content, which we can use according to our own needs:

The text obtained is generally in json format:
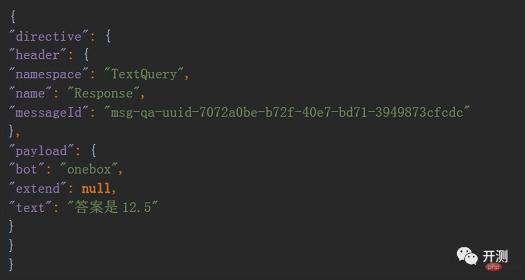
We can convert json and use the json.loads method to convert a json object into a python dictionary, so that we can easily obtain some of the fields we want. This step is very simple. , I won’t introduce it in detail.
How to execute case and store test results
First let’s take a look at our case. Our case is written using Excel, as follows:

1080×112 39.8 KB
How to read Excel and get the cases? We used the pandas library in python. This library is very powerful and has many methods for processing data. We only use the method of reading excel. The specific code is as follows:
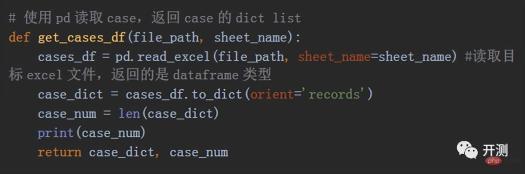
In this way we convert the table data A list is created, and each list is in a dictionary format, which is our case. The specific format is as follows:

The purpose of this is that we can combine the header and each Each case is mapped to form a dictionary, which allows for more flexible case operation and data comparison.
With the case list and the previous steps of sending requests and obtaining results, we can perform batch interface testing. Here, we can use a for loop to run in batches:
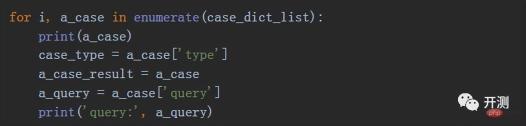
We splice the results returned each time into a dictionary according to the case format, which is our result data. We store each result dictionary into a list to get the entire result dictionary list. , we name it case_result_list. At this time, we use the pandas library again to convert this list into dataframe format:

After that we save the dataframe as an excel file:

So far, we have completed the entire process from obtaining the case to sending a request to obtain the results and saving the results.
Identify the result data
After the above operations, we have completed the process of sending requests in batches and obtaining results. If we need to do some processing on the result cells, such as marking them red Boldening and other operations can make the error information in the test results more obvious. What should be done? Here we use the openpyxl library in python. This library can also read and write Excel tables, and can insert some formulas and styles. What we use here is style operation. We highlight the results in red and bold according to the data in the cell:
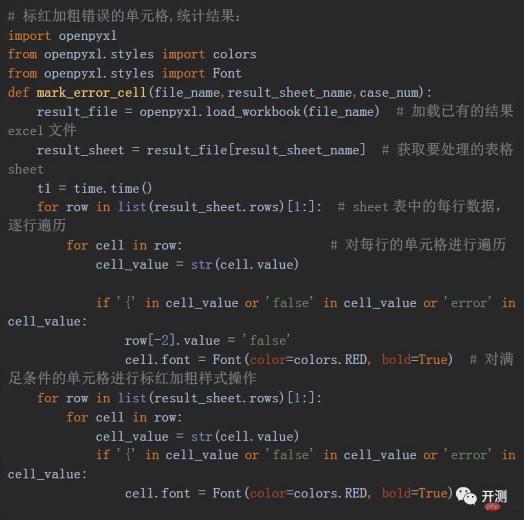
The final test results obtained are as follows, by using openpyxl , we can also append rows to the results to add some statistical information of the test results, such as the number of cases, the number of errors, the error rate and the accuracy rate, etc.
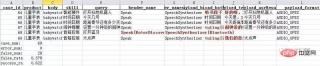
1080×224 61.6 KB
The above is a complete interface automated test script to implement automatic request, obtain results, data comparison analysis, export results to Excel, etc. Function, each step is relatively simple, you can quickly build an automated test script that meets your needs, and quickly verify the server interface.
The requests library and pandas library used are commonly used libraries in python, and their functions are very powerful. You can refer to their official documents for in-depth understanding later.
The above is the detailed content of Practical summary of using Python to quickly build interface automated test scripts. For more information, please follow other related articles on the PHP Chinese website!

 解读CRISP-ML(Q):机器学习生命周期流程Apr 08, 2023 pm 01:21 PM
解读CRISP-ML(Q):机器学习生命周期流程Apr 08, 2023 pm 01:21 PM译者 | 布加迪审校 | 孙淑娟目前,没有用于构建和管理机器学习(ML)应用程序的标准实践。机器学习项目组织得不好,缺乏可重复性,而且从长远来看容易彻底失败。因此,我们需要一套流程来帮助自己在整个机器学习生命周期中保持质量、可持续性、稳健性和成本管理。图1. 机器学习开发生命周期流程使用质量保证方法开发机器学习应用程序的跨行业标准流程(CRISP-ML(Q))是CRISP-DM的升级版,以确保机器学习产品的质量。CRISP-ML(Q)有六个单独的阶段:1. 业务和数据理解2. 数据准备3. 模型
 人工智能的环境成本和承诺Apr 08, 2023 pm 04:31 PM
人工智能的环境成本和承诺Apr 08, 2023 pm 04:31 PM人工智能(AI)在流行文化和政治分析中经常以两种极端的形式出现。它要么代表着人类智慧与科技实力相结合的未来主义乌托邦的关键,要么是迈向反乌托邦式机器崛起的第一步。学者、企业家、甚至活动家在应用人工智能应对气候变化时都采用了同样的二元思维。科技行业对人工智能在创建一个新的技术乌托邦中所扮演的角色的单一关注,掩盖了人工智能可能加剧环境退化的方式,通常是直接伤害边缘人群的方式。为了在应对气候变化的过程中充分利用人工智能技术,同时承认其大量消耗能源,引领人工智能潮流的科技公司需要探索人工智能对环境影响的
 找不到中文语音预训练模型?中文版 Wav2vec 2.0和HuBERT来了Apr 08, 2023 pm 06:21 PM
找不到中文语音预训练模型?中文版 Wav2vec 2.0和HuBERT来了Apr 08, 2023 pm 06:21 PMWav2vec 2.0 [1],HuBERT [2] 和 WavLM [3] 等语音预训练模型,通过在多达上万小时的无标注语音数据(如 Libri-light )上的自监督学习,显著提升了自动语音识别(Automatic Speech Recognition, ASR),语音合成(Text-to-speech, TTS)和语音转换(Voice Conversation,VC)等语音下游任务的性能。然而这些模型都没有公开的中文版本,不便于应用在中文语音研究场景。 WenetSpeech [4] 是
 条形统计图用什么呈现数据Jan 20, 2021 pm 03:31 PM
条形统计图用什么呈现数据Jan 20, 2021 pm 03:31 PM条形统计图用“直条”呈现数据。条形统计图是用一个单位长度表示一定的数量,根据数量的多少画成长短不同的直条,然后把这些直条按一定的顺序排列起来;从条形统计图中很容易看出各种数量的多少。条形统计图分为:单式条形统计图和复式条形统计图,前者只表示1个项目的数据,后者可以同时表示多个项目的数据。
 自动驾驶车道线检测分类的虚拟-真实域适应方法Apr 08, 2023 pm 02:31 PM
自动驾驶车道线检测分类的虚拟-真实域适应方法Apr 08, 2023 pm 02:31 PMarXiv论文“Sim-to-Real Domain Adaptation for Lane Detection and Classification in Autonomous Driving“,2022年5月,加拿大滑铁卢大学的工作。虽然自主驾驶的监督检测和分类框架需要大型标注数据集,但光照真实模拟环境生成的合成数据推动的无监督域适应(UDA,Unsupervised Domain Adaptation)方法则是低成本、耗时更少的解决方案。本文提出对抗性鉴别和生成(adversarial d
 数据通信中的信道传输速率单位是bps,它表示什么Jan 18, 2021 pm 02:58 PM
数据通信中的信道传输速率单位是bps,它表示什么Jan 18, 2021 pm 02:58 PM数据通信中的信道传输速率单位是bps,它表示“位/秒”或“比特/秒”,即数据传输速率在数值上等于每秒钟传输构成数据代码的二进制比特数,也称“比特率”。比特率表示单位时间内传送比特的数目,用于衡量数字信息的传送速度;根据每帧图像存储时所占的比特数和传输比特率,可以计算数字图像信息传输的速度。
 数据分析方法有哪几种Dec 15, 2020 am 09:48 AM
数据分析方法有哪几种Dec 15, 2020 am 09:48 AM数据分析方法有4种,分别是:1、趋势分析,趋势分析一般用于核心指标的长期跟踪;2、象限分析,可依据数据的不同,将各个比较主体划分到四个象限中;3、对比分析,分为横向对比和纵向对比;4、交叉分析,主要作用就是从多个维度细分数据。
 15年软件架构师经验总结:在ML领域,初学者踩过的五个坑Apr 11, 2023 pm 07:31 PM
15年软件架构师经验总结:在ML领域,初学者踩过的五个坑Apr 11, 2023 pm 07:31 PM数据科学和机器学习正变得越来越流行,这个领域的人数每天都在增长。这意味着有很多数据科学家在构建他们的第一个机器学习模型时没有丰富的经验,而这也是错误可能会发生的地方。近日,软件架构师、数据科学家、Kaggle 大师 Agnis Liukis 撰写了一篇文章,他在文中谈了谈在机器学习中最常见的一些初学者错误的解决方案,以确保初学者了解并避免它们。Agnis Liukis 拥有超过 15 年的软件架构和开发经验,他熟练掌握 Java、JavaScript、Spring Boot、React.JS


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

Dreamweaver Mac version
Visual web development tools

Notepad++7.3.1
Easy-to-use and free code editor

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

