

 Technology peripheralsAIBarrier-free travel is safer! ByteDance's research results won the CVPR2022 AVA competition championship
Technology peripheralsAIBarrier-free travel is safer! ByteDance's research results won the CVPR2022 AVA competition championship
Recently, the results of various CVPR2022 competitions have been announced one after another. The ByteDance intelligent creation AI platform "Byte-IC-AutoML" team won the Instance Segmentation Challenge based on synthetic data (Accessibility Vision and Autonomy Challenge, hereinafter referred to as AVA). ), with the self-developed Parallel Pre-trained Transformers (PPT) framework, he stood out and became the winner of the only track in the competition.

Paper address:https:/ /www.php.cn/link/ede529dfcbb2907e9760eea0875cdd12
This AVA competition is jointly organized by Boston University and Carnegie Mellon University .
The competition derives a synthetic instance segmentation dataset via a rendering engine containing data samples of autonomous systems interacting with disabled pedestrians. The goal of the competition is to provide benchmarks and methods for target detection and instance segmentation for people and objects related to accessibility.

Dataset visualization
Analysis of competition difficulties
- Domain generalization problem: The data sets of this competition are all images synthesized by the rendering engine, and there are significant differences between the data domain and natural images;
- Long-tail/few-sample problem: The data has a long-tail distribution, such as "Crutches" and "Wheelchair" categories are fewer in the data set, and the segmentation effect is also worse;
- Segmentation robustness problem: The segmentation effect of some categories is very poor. The instance segmentation mAP is 30 lower than the target detection segmentation mAP
Detailed explanation of the technical solution
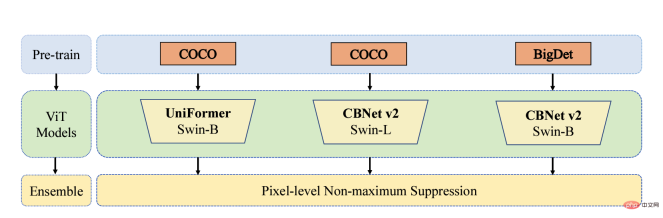
The Byte-IC-AutoML team proposed a Parallel Pre-trained Transformers (PPT) framework to accomplish this. The framework mainly consists of three modules: 1) Parallel large-scale pre-trained Transformers; 2) Balance Copy-Paste data enhancement; 3) Pixel-level non-maximum suppression and model fusion;
parallel large-scale pre-training Transformers
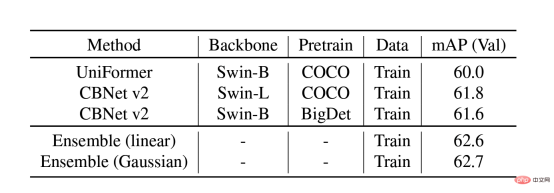
Many recent pre-training articles have shown that models pre-trained on large-scale data sets can generalize well to different downstream scenarios. Therefore, the team uses the COCO and BigDetection data sets to pre-train the model first, which can alleviate the domain deviation between natural data and synthetic data to a greater extent so that it can be used downstream Fast training with fewer samples in synthetic data scenarios. At the model level, considering that Vision Transformers do not have the inductive bias of CNN and can enjoy the benefits of pre-training, the team uses UniFormer and CBNetV2. UniFormer unifies convolution and self-attention, simultaneously solves the two major problems of local redundancy and global dependency, and achieves efficient feature learning. The CBNetV2 architecture concatenates multiple identical backbone packets through composite connections to build high-performance detectors. The backbone feature extractors of the model are all Swin Transformer. Multiple large-scale pre-trained Transformers are arranged in parallel, and the output results are integrated and learned to output the final result.

mAP of different methods on the validation data set
Balance Copy-Paste Data Enhancement
Copy-Paste technique provides impressive results for instance segmentation models by randomly pasting objects, especially for datasets under long-tail distribution. However, this method evenly increases the samples of all categories and fails to fundamentally alleviate the long-tail problem of category distribution. Therefore, the team proposed the Balance Copy-Paste data enhancement method. Balance Copy-Paste adaptively samples categories according to the effective number of categories, improves the overall sample quality, alleviates the problems of small number of samples and long-tail distribution, and ultimately greatly improves the mAP of the model in instance segmentation.

Improvements brought by Balance Copy-Paste data enhancement technology
Pixel-level non-maximum suppression and Model fusion
Model fusion ablation experiment on the validation set

Test Model fusion ablation experiment on the set
Currently, urban and traffic data sets are more general scenes, including only normal transportation and pedestrians. The data set lacks information about disabled people and their actions. Inconvenient people and the types of their assistive devices cannot be detected by detection models using currently existing data sets.
This technical solution of ByteDance’s Byte-IC-AutoML team is widely used in current autonomous driving and street scene understanding: the model obtained through these synthetic data can identify “ Rare categories such as "wheelchair", "person in wheelchair", "person on crutches", etc. can not only classify people/objects more precisely, but also avoid misjudgment and misjudgment leading to misunderstanding of the scene. In addition, through this method of synthesizing data, data of relatively rare categories in the real world can be constructed, thereby training a more versatile and complete target detection model.
Intelligent Creation is ByteDance’s multimedia innovation technology research institute and comprehensive service provider. Covering computer vision, graphics, voice, shooting and editing, special effects, clients, AI platforms, server engineering and other technical fields, a closed loop of cutting-edge algorithms-engineering systems-products has been implemented within the department, aiming to use multiple In this way, we provide the company's internal business lines and external cooperative customers with the industry's most cutting-edge content understanding, content creation, interactive experience and consumption capabilities and industry solutions. The team's technical capabilities are being opened to the outside world through Volcano Engine.
Volcano Engine is a cloud service platform owned by Bytedance. It opens the growth methods, technical capabilities and tools accumulated during the rapid development of Bytedance to external enterprises, providing cloud foundation, Services such as video and content distribution, big data, artificial intelligence, development and operation and maintenance help enterprises achieve sustained growth during digital upgrades.
The above is the detailed content of Barrier-free travel is safer! ByteDance's research results won the CVPR2022 AVA competition championship. For more information, please follow other related articles on the PHP Chinese website!

 字节跳动豆包大模型发布,火山引擎全栈 AI 服务助力企业智能化转型Jun 05, 2024 pm 07:59 PM
字节跳动豆包大模型发布,火山引擎全栈 AI 服务助力企业智能化转型Jun 05, 2024 pm 07:59 PM火山引擎总裁谭待企业要做好大模型落地,面临模型效果、推理成本、落地难度的三大关键挑战:既要有好的基础大模型做支撑,解决复杂难题,也要有低成本的推理服务让大模型被广泛应用,还要更多工具、平台和应用帮助企业做好场景落地。——谭待火山引擎总裁01.豆包大模型首次亮相大使用量打磨好模型模型效果是AI落地最关键的挑战。谭待指出,只有大的使用量,才能打磨出好模型。目前,豆包大模型日均处理1,200亿tokens文本、生成3,000万张图片。为助力企业做好大模型场景落地,字节跳动自主研发的豆包大模型将通过火山
 营销效果大幅提升,AIGC视频创作就该这么用Jun 25, 2024 am 12:01 AM
营销效果大幅提升,AIGC视频创作就该这么用Jun 25, 2024 am 12:01 AM经过一年多的发展,AIGC已经从文字对话、图片生成逐步向视频生成迈进。回想四个月前,Sora的诞生让视频生成赛道经历了一场洗牌,大力推动了AIGC在视频创作领域的应用范围和深度。在人人都在谈论大模型的时代,我们一方面惊讶于视频生成带来的视觉震撼,另一方面又面临着落地难问题。诚然,大模型从技术研发到应用实践还处于一个磨合期,仍需结合实际业务场景进行调优,但理想与现实的距离正在被逐步缩小。营销作为人工智能技术的重要落地场景,成为了很多企业及从业者想要突破的方向。掌握了恰当方法,营销视频的创作过程就会
 如何探索和可视化用于图像中物体检测的 ML 数据Feb 16, 2024 am 11:33 AM
如何探索和可视化用于图像中物体检测的 ML 数据Feb 16, 2024 am 11:33 AM近年来,人们对深入理解机器学习数据(ML-data)的重要性有了更深刻的认识。然而,由于检测大型数据集通常需要大量的人力和物力投入,因此在计算机视觉领域的广泛应用仍然需要进一步的开发。通常,在物体检测(ObjectDetection,属于计算机视觉的一个子集)中,通过定义边界框,来定位图像中的物体,不仅可以识别物体,还能够了解物体的上下文、大小、以及与场景中其他元素的关系。同时,针对类的分布、物体大小的多样性、以及类出现的常见环境进行全面了解,也有助于在评估和调试中发现训练模型中的错误模式,从而
 Python中的深度学习预训练模型详解Jun 11, 2023 am 08:12 AM
Python中的深度学习预训练模型详解Jun 11, 2023 am 08:12 AM随着人工智能和深度学习的发展,预训练模型已经成为了自然语言处理(NLP)、计算机视觉(CV)、语音识别等领域的热门技术。Python作为目前最流行的编程语言之一,自然也在预训练模型的应用中扮演了重要角色。本文将重点介绍Python中的深度学习预训练模型,包括其定义、种类、应用以及如何使用预训练模型。什么是预训练模型?深度学习模型的主要难点在于对大量高质量
 火山语音TTS技术实力获国检中心认证 MOS评分高达4.64Apr 12, 2023 am 10:40 AM
火山语音TTS技术实力获国检中心认证 MOS评分高达4.64Apr 12, 2023 am 10:40 AM日前,火山引擎语音合成产品获得国家语音及图像识别产品质量检验检测中心(以下简称“AI国检中心”)颁发的语音合成增强级检验检测证书,在语音合成的基本要求以及扩展要求上已达AI国检中心的最高等级标准。本次评测从中文普通话、多方言、多语种、混合语种、多音色、个性化等维度进行评测,产品的技术支持团队-火山语音团队提供了丰富的音库,经评测其音色MOS评分最高可达4.64分,处行业领先水平。作为我国质检系统在人工智能领域的首家、也是唯一的国家级语音及图像产品质量检验检测机构,AI 国检中心一直致力于推动智能
 主打个性化体验,留住用户全靠AIGC?Jul 15, 2024 pm 06:48 PM
主打个性化体验,留住用户全靠AIGC?Jul 15, 2024 pm 06:48 PM1.购买商品前,消费者会在社交媒体上搜索并浏览商品评价。因此,企业在社交平台上针对产品进行营销变得越来越重要。营销的目的是为了:促进产品的销售树立品牌形象提高品牌认知度吸引并留住客户最终提高企业的盈利能力大模型具备出色的理解和生成能力,可以通过浏览和分析用户数据为用户提供个性化内容推荐。《AIGC体验派》第四期中,两位嘉宾将深入探讨AIGC技术在提升「营销转化率」方面发挥的作用。直播时间:7月10日19:00-19:45直播主题:留住用户,AIGC如何通过个性化提升转化率?第四期节目邀请到两位重
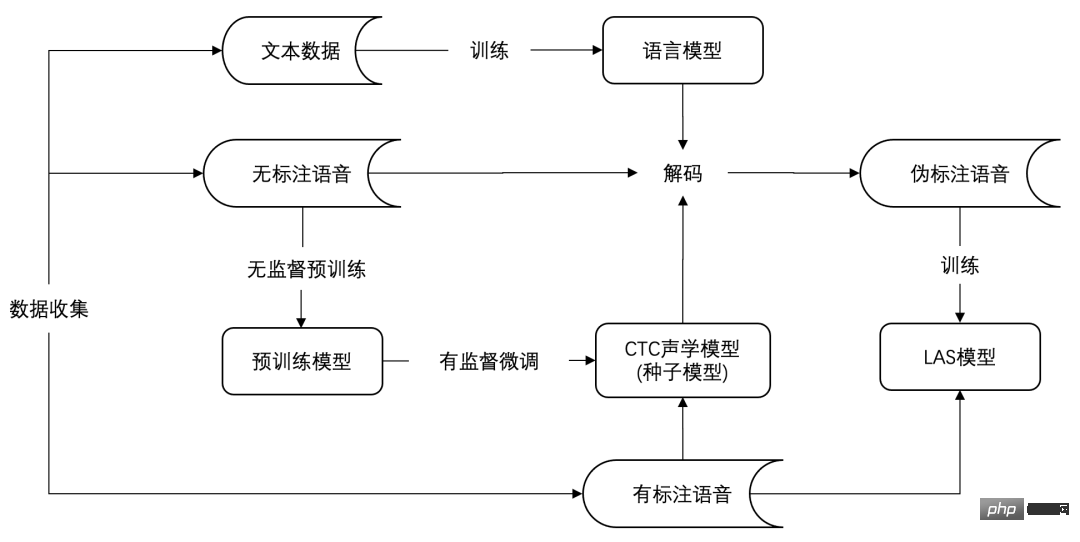 深探无监督预训练技术落地 火山语音“算法优化+工程革新”并举Apr 08, 2023 pm 12:44 PM
深探无监督预训练技术落地 火山语音“算法优化+工程革新”并举Apr 08, 2023 pm 12:44 PM长期以来,火山引擎为时下风靡的视频平台提供基于语音识别技术的智能视频字幕解决方案。简单来说,就是通过AI技术自动将视频中的语音和歌词转化成文字,辅助视频创作的功能。但伴随平台用户的快速增长以及对语言种类更加丰富多样的要求,传统采用的有监督学习技术日渐触及瓶颈,这让团队着实犯了难。众所周知,传统的有监督学习会对人工标注的有监督数据产生严重依赖,尤其在大语种的持续优化以及小语种的冷启动方面。以中文普通话和英语这样的大语种为例,尽管视频平台提供了充足的业务场景语音数据,但有监督数据达到一定规模之后,继
 全抖音都在说家乡话,两项关键技术助你“听懂”各地方言Oct 12, 2023 pm 08:13 PM
全抖音都在说家乡话,两项关键技术助你“听懂”各地方言Oct 12, 2023 pm 08:13 PM国庆期间,抖音上“一句方言证明你是地道家乡人”的活动在吸引了全国各地的网友热情参与,话题最高登上抖音挑战榜第一位,播放量已超过5000万。这场“各地方言大赏”能够在网络上迅速走红,离不开抖音新推出的地方方言自动翻译功能的功劳。创作者们在录制家乡话的短视频时,使用了“自动字幕”功能,并选择了“转为普通话字幕”,这样就能够自动识别视频中的方言语音,并将方言内容转化为普通话字幕,让其他地区的网友也能轻松听懂各种“加密型国语”。福建的网友亲自测试后表示,就连“十里不同音”的闽南地区是中国福建省的一个地域


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SublimeText3 English version
Recommended: Win version, supports code prompts!

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

WebStorm Mac version
Useful JavaScript development tools

SublimeText3 Linux new version
SublimeText3 Linux latest version

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

