
 Technology peripheralsAIDatasets and driving perception in repetitive and challenging weather conditions
Technology peripheralsAIDatasets and driving perception in repetitive and challenging weather conditions
arXiv paper "Ithaca365: Dataset and Driving Perception under Repeated and Challenging Weather Conditions", uploaded on August 1, 22, work from Cornell and Ohio State universities.

In recent years, the perception capabilities of autonomous vehicles have improved due to the use of large-scale data sets, which are often collected in specific locations and under good weather conditions. However, in order to meet high safety requirements, these sensing systems must operate robustly in various weather conditions, including snow and rain conditions.
This article proposes a data set to achieve robust autonomous driving, using a new data collection process, that is, in different scenarios (cities, highways, rural areas, campuses), weather (snow, rain, sun), time Data were recorded repeatedly along a 15 km route under (day/night) and traffic conditions (pedestrians, cyclists and cars).
The dataset includes images and point clouds from cameras and lidar sensors, as well as high-precision GPS/INS to establish correspondence across routes. The dataset includes road and object annotations, local occlusions and 3-D bounding boxes captured with amodal masks.
Repeated paths open up new research directions for target discovery, continuous learning, and anomaly detection.
Ithaca365 link: A new dataset to enable robust autonomous driving via a novel data collection process
The picture shows the sensor configuration of data collection:
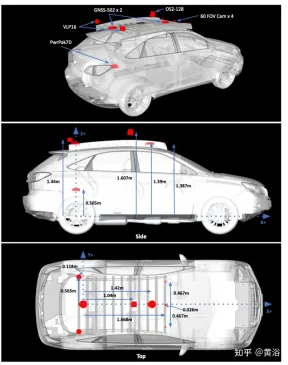
Figure a shows the route map with images captured at multiple locations. Drives were scheduled to collect data at different times of the day, including at night. Record heavy snow conditions before and after road clearing.

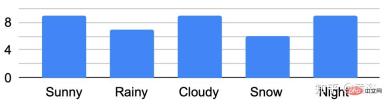
A key feature of the dataset is that the same locations can be observed under different conditions; an example is shown in Figure b.

The figure shows the traversal analysis under different conditions:
Develop a custom marking tool , used to obtain amodal masks of roads and objects. For road labels under different environmental conditions, such as snow-covered roads, use repeated traversals of the same route. Specifically, the point cloud road map constructed from GPS attitude and lidar data converts the road label of "good weather" into "bad weather".
Routes/data are divided into 76 intervals. Project the point cloud into BEV and label the road using polygon annotator. Once the road is marked in BEV (generating a 2-D road boundary), the polygon is decomposed into smaller 150 m^2 polygons, using a threshold of 1.5 m average height, and a plane fit is done to the points within the polygon boundary to determine the road height. .
Use RANSAC and a regressor to fit a plane to these points; then use the estimated ground plane to calculate the height of each point along the boundary. Project the road points into the image and create a depth mask to obtain the non-modal label of the road. Matching locations to marked maps with GPS and optimizing routes with ICP can project ground planes to specific locations on new collection routes.
A final check on the ICP solution by verifying that the average projected ground truth mask of the road label conforms to 80% mIOU with all other ground truth masks at the same location; if not, querying the location data will not be retrieved.
Non-modal targets are labeled with Scale AI for six foreground target categories: cars, buses, trucks (including cargo, fire trucks, pickup trucks, ambulances), pedestrians, cyclists, and motorcyclists.
This labeling paradigm has three main components: first identifying visible instances of an object, then inferring occluded instance segmentation masks, and finally labeling the occlusion order of each object. Marking is performed on the leftmost forward camera view. Follows the same standards as KINS ("Amodal instance segmentation with kins dataset". CVPR, 2019).
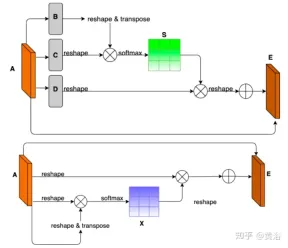
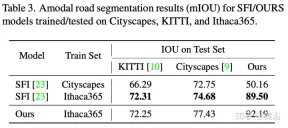
To demonstrate the environmental diversity and amodal quality of the dataset, two baseline networks were trained and tested to identify amodal roads at the pixel level, working even when the roads are covered with snow or cars. The first baseline network is Semantic Foreground Inpainting (SFI). The second baseline, as shown in the figure, adopts the following three innovations to improve SFI.

- Position and Channel Note: Because amodal segmentation mainly infers what is invisible, context is a very important clue. DAN ("Dual attention network for scene segmentation", CVPR’2019) introduces two innovations to capture two different backgrounds. The Position Attention Module (PAM) uses pixel features to focus on other pixels of the image, actually capturing context from other parts of the image. The Channel Attention Module (CAM) uses a similar attention mechanism to efficiently aggregate channel information. Here these two modules are applied on the backbone feature extractor. Combining CAM and PAM for better localization of fine mask boundaries. The final foreground instance mask is obtained through an upsampling layer.
- Hybrid pooling as inpainting: Maximum pooling is used as a patching operation to replace overlapping foreground features with nearby background features to help restore non-modal road features. However, since background features are usually smoothly distributed, the max pooling operation is very sensitive to any added noise. In contrast, average pooling operations naturally mitigate noise. To this end, average pooling and maximum pooling are combined for patching, which is called Mixture Pooling.
- Sum operation: Before the final upsampling layer, the features from the hybrid pooling module are not passed directly, but the residual links from the output of the PAM module are included. By jointly optimizing two feature maps in the road segmentation branch, the PAM module can also learn background features of occluded areas. This can lead to more accurate recovery of background features.
The picture shows the architecture diagram of PAM and CAM:
The pseudo code of the hybrid pooling patching algorithm is as follows:

The training and testing codes for non-modal road segmentation are as follows: https://github.com/coolgrasshopper/amodal_road_segmentation
The experimental results are as follows:
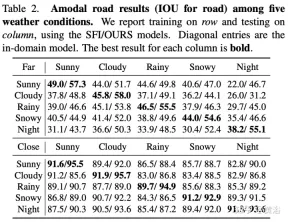
##
The above is the detailed content of Datasets and driving perception in repetitive and challenging weather conditions. For more information, please follow other related articles on the PHP Chinese website!

 Windows 11 上的智能应用控制:如何打开或关闭它Jun 06, 2023 pm 11:10 PM
Windows 11 上的智能应用控制:如何打开或关闭它Jun 06, 2023 pm 11:10 PM智能应用控制是Windows11中非常有用的工具,可帮助保护你的电脑免受可能损害数据的未经授权的应用(如勒索软件或间谍软件)的侵害。本文将解释什么是智能应用控制、它是如何工作的,以及如何在Windows11中打开或关闭它。什么是Windows11中的智能应用控制?智能应用控制(SAC)是Windows1122H2更新中引入的一项新安全功能。它与MicrosoftDefender或第三方防病毒软件一起运行,以阻止可能不必要的应用,这些应用可能会减慢设备速度、显示意外广告或执行其他意外操作。智能应用
 一文聊聊SLAM技术在自动驾驶的应用Apr 09, 2023 pm 01:11 PM
一文聊聊SLAM技术在自动驾驶的应用Apr 09, 2023 pm 01:11 PM定位在自动驾驶中占据着不可替代的地位,而且未来有着可期的发展。目前自动驾驶中的定位都是依赖RTK配合高精地图,这给自动驾驶的落地增加了不少成本与难度。试想一下人类开车,并非需要知道自己的全局高精定位及周围的详细环境,有一条全局导航路径并配合车辆在该路径上的位置,也就足够了,而这里牵涉到的,便是SLAM领域的关键技术。什么是SLAMSLAM (Simultaneous Localization and Mapping),也称为CML (Concurrent Mapping and Localiza
 一文读懂智能汽车滑板底盘May 24, 2023 pm 12:01 PM
一文读懂智能汽车滑板底盘May 24, 2023 pm 12:01 PM01什么是滑板底盘所谓滑板式底盘,即将电池、电动传动系统、悬架、刹车等部件提前整合在底盘上,实现车身和底盘的分离,设计解耦。基于这类平台,车企可以大幅降低前期研发和测试成本,同时快速响应市场需求打造不同的车型。尤其是无人驾驶时代,车内的布局不再是以驾驶为中心,而是会注重空间属性,有了滑板式底盘,可以为上部车舱的开发提供更多的可能。如上图,当然我们看滑板底盘,不要上来就被「噢,就是非承载车身啊」的第一印象框住。当年没有电动车,所以没有几百公斤的电池包,没有能取消转向柱的线传转向系统,没有线传制动系
 智能网联汽车线控底盘技术深度解析May 02, 2023 am 11:28 AM
智能网联汽车线控底盘技术深度解析May 02, 2023 am 11:28 AM01线控技术认知线控技术(XbyWire),是将驾驶员的操作动作经过传感器转变成电信号来实现传递控制,替代传统机械系统或者液压系统,并由电信号直接控制执行机构以实现控制目的,基本原理如图1所示。该技术源于美国国家航空航天局(NationalAeronauticsandSpaceAdministration,NASA)1972年推出的线控飞行技术(FlybyWire)的飞机。其中,“X”就像数学方程中的未知数,代表汽车中传统上由机械或液压控制的各个部件及相关的操作。图1线控技术的基本原理
 智能汽车规划控制常用控制方法详解Apr 11, 2023 pm 11:16 PM
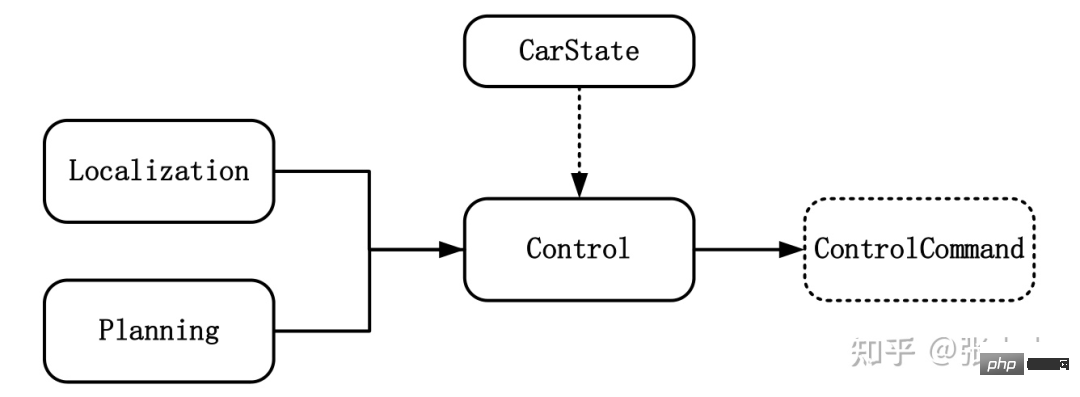
智能汽车规划控制常用控制方法详解Apr 11, 2023 pm 11:16 PM控制是驱使车辆前行的策略。控制的目标是使用可行的控制量,最大限度地降低与目标轨迹的偏差、最大限度地提供乘客的舒适度等。如上图所示,与控制模块输入相关联的模块有规划模块、定位模块和车辆信息等。其中定位模块提供车辆的位置信息,规划模块提供目标轨迹信息,车辆信息则包括档位、速度、加速度等。控制输出量则为转向、加速和制动量。控制模块主要分为横向控制和纵向控制,根据耦合形式的不同可以分为独立和一体化两种方法。1 控制方法1.1 解耦控制所谓解耦控制,就是将横向和纵向控制方法独立分开进行控制。1.2 耦合控
 一文读懂智能汽车驾驶员监控系统Apr 11, 2023 pm 08:07 PM
一文读懂智能汽车驾驶员监控系统Apr 11, 2023 pm 08:07 PM驾驶员监控系统,缩写DMS,是英文Driver Monitor System的缩写,即驾驶员监控系统。主要是实现对驾驶员的身份识别、驾驶员疲劳驾驶以及危险行为的检测功能。福特DMS系统01 法规加持,DMS进入发展快车道在现阶段开始量产的L2-L3级自动驾驶中,其实都只有在特定条件下才可以实行,很多状况下需要驾驶员能及时接管车辆进行处置。因此,在驾驶员太信任自动驾驶而放弃或减弱对驾驶过程的掌控时可能会导致某些事故的发生。而DMS-驾驶员监控系统的引入可以有效减轻这一问题的出现。麦格纳DMS系统,
 李飞飞两位高徒联合指导:能看懂「多模态提示」的机器人,zero-shot性能提升2.9倍Apr 12, 2023 pm 08:37 PM
李飞飞两位高徒联合指导:能看懂「多模态提示」的机器人,zero-shot性能提升2.9倍Apr 12, 2023 pm 08:37 PM人工智能领域的下一个发展机会,有可能是给AI模型装上一个「身体」,与真实世界进行互动来学习。相比现有的自然语言处理、计算机视觉等在特定环境下执行的任务来说,开放领域的机器人技术显然更难。比如prompt-based学习可以让单个语言模型执行任意的自然语言处理任务,比如写代码、做文摘、问答,只需要修改prompt即可。但机器人技术中的任务规范种类更多,比如模仿单样本演示、遵照语言指示或者实现某一视觉目标,这些通常都被视为不同的任务,由专门训练后的模型来处理。最近来自英伟达、斯坦福大学、玛卡莱斯特学
 AutoGPT star量破10万,这是首篇系统介绍自主智能体的文章Apr 28, 2023 pm 04:10 PM
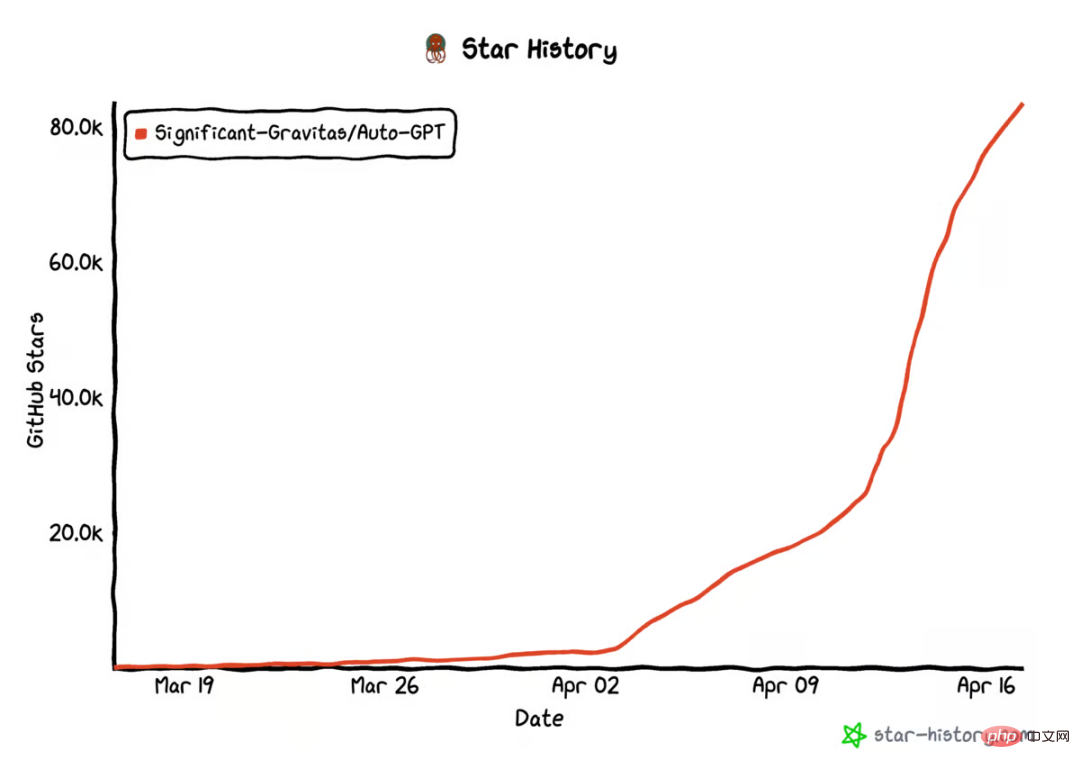
AutoGPT star量破10万,这是首篇系统介绍自主智能体的文章Apr 28, 2023 pm 04:10 PM在GitHub上,AutoGPT的star量已经破10万。这是一种新型人机交互方式:你不用告诉AI先做什么,再做什么,而是给它制定一个目标就好,哪怕像「创造世界上最好的冰淇淋」这样简单。类似的项目还有BabyAGI等等。这股自主智能体浪潮意味着什么?它们是怎么运行的?它们在未来会是什么样子?现阶段如何尝试这项新技术?在这篇文章中,OctaneAI首席执行官、联合创始人MattSchlicht进行了详细介绍。人工智能可以用来完成非常具体的任务,比如推荐内容、撰写文案、回答问题,甚至生成与现实生活无


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

WebStorm Mac version
Useful JavaScript development tools

Atom editor mac version download
The most popular open source editor

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

