
Interview answer: It is best for each MySQL table to have no more than 20 million data, right?

- 青灯夜游Original
- 2022-11-22 16:48:342978browse
How much data can each table in MySQL store? In actual situations, each table has different fields and the space occupied by the fields. The amount of data they can store under optimal performance is also different, which requires manual calculation.
The thing is like this
The following is my friend’s interview record:
Interviewer: Tell me a little bit What did you do as an intern?
Friend: During my internship, I built a function to store user operation records. It mainly obtains user operation information sent from the upstream service from MQ, and then stores this information in MySQL and provides it to the data warehouse. Used by colleagues.
Friend: Because the amount of data is relatively large, there are about 40 to 50 million entries every day, so I also performed a sub-table operation for it. Three tables are generated regularly every day, and then the data is modeled and stored in these three tables respectively to prevent excessive data in the tables from slowing down the query speed.
There seems to be nothing wrong with this statement, right? Don’t worry, let’s continue reading:
Interviewer: Then why do you divide it into three tables? Two tables won’t work. ? Wouldn't four tables work?
Friend: Because each MySQL table should not exceed 20 million pieces of data, otherwise the query speed will be reduced and performance will be affected. Our daily data is about 50 million pieces, so it is safer to divide it into three tables.
Interviewer: Any more?
Friend: No more...What are you doing, ouch
Interviewer: Then go back and wait for the notification.
Have finished speaking, did you see anything? Do you think there are any problems with my friend’s answer?
Preface
Many people say that it is best not to exceed 20 million pieces of data in each MySQL table, otherwise it will lead to performance degradation. Alibaba's Java development manual also states that it is recommended to split databases and tables only if the number of rows in a single table exceeds 5 million or the capacity of a single table exceeds 2GB.
But in fact, this 20 million or 5 million is just a rough number and does not apply to all scenarios. If you blindly think that as long as the table data does not exceed 20 million, there will be no problem. It is likely to cause a significant drop in system performance.
In actual circumstances, each table has different fields and the space occupied by the fields, so the amount of data they can store under optimal performance is also different.
So, how to calculate the appropriate amount of data for each table? Don't worry, look down slowly.
This article is suitable for readersTo read this article, you need to have a certain MySQL foundation, and it is best to have a certain understanding of InnoDB and B-trees. , you may need to have more than one year of MySQL learning experience (about one year?), and know the theoretical knowledge that "it is generally better to keep the height of the B-tree in InnoDB within three levels."
This article mainly explains the topic "How much data can be stored in a B-tree with a height of 3 in InnoDB?" Moreover, the calculation of data in this article is relatively strict (at least stricter than more than 95% of related blog posts on the Internet). If you care about these details and are not clear at the moment, please continue reading.
It will take you about 10-20 minutes to read this article. If you check the data while reading, it may take about 30 minutes.
Mind map of this article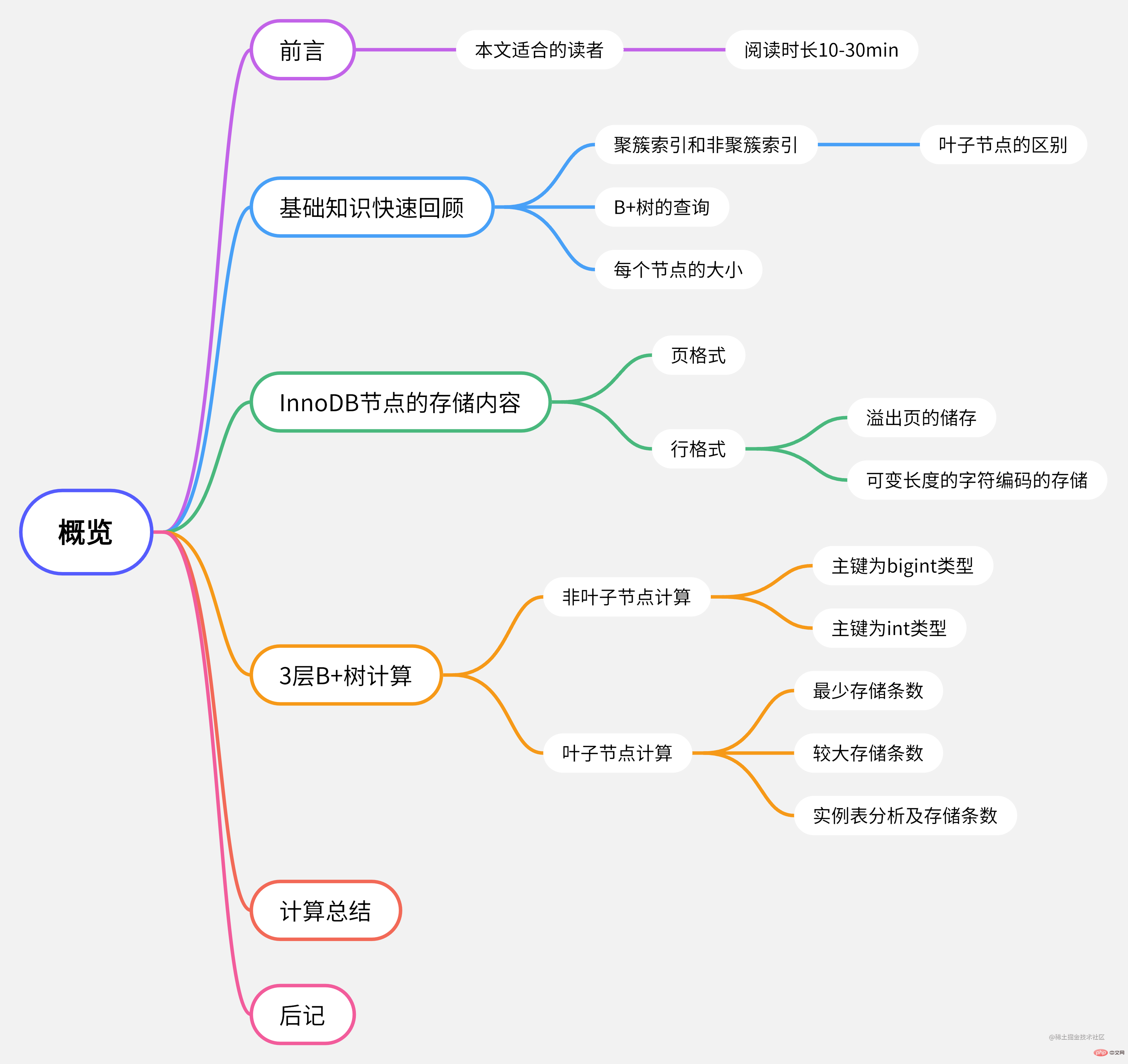
##Quick review of basic knowledge
As we all know, the storage structure of InnoDB in MySQL is a B-tree. Everyone is familiar with the B-tree, right? The features are roughly as follows, let’s quickly review them together!
Note: The following content is the essence. Students who cannot read or understand it are recommended to save this article first, and then come back to read it after having a knowledge base.
A data table generally corresponds to the storage of one or more trees. The number of trees is related to the number of indexes. Each index will have a separate tree.
- Clustered index and non-clustered index:
- The primary key index is also a clustered index, and the non-primary key index is a non-clustered index.
Except for the format information, the non-leaf nodes of both indexes only store index data
. For example, if the index is id, then the non-leaf node stores the id data.The differences between leaf nodes are as follows:
- The leaf nodes of the clustered index generally store all field information of this data. So when we
select * from table where id = 1, we always go to the leaf nodes to get the data. - The leaf nodes of the non-clustered index store the primary key and index column information corresponding to this piece of data. For example, if this non-clustered index is username, and the primary key of the table is id, then the leaf nodes of the non-clustered index store username and id, but not other fields. It is equivalent to first finding the value of the primary key from the non-clustered index, and then checking the data content based on the primary key index. Generally, it needs to be checked twice (unless the index is covered). This is also called Back to the table is a bit similar to saving a pointer, pointing to the real address where the data is stored.
- The leaf nodes of the clustered index generally store all field information of this data. So when we
-
The query of the B tree is queried layer by layer from top to bottom. Generally speaking, we think it is better to keep the height of the B tree within 3 layers. That is, the upper two layers are indexes, and the last layer stores data. In this way, when looking up the table, only three disk IOs are required (actually one less time, because the root node will be resident in memory), and the amount of data that can be stored is It’s also quite impressive.
If the amount of data is too large, causing the number of B to become 4 levels, each query will require 4 disk IOs, resulting in performance degradation. That’s why we calculate the maximum number of pieces of data that InnoDB’s 3-layer B-tree can store.
-
The default size of each MySQL node is 16KB, which means that each node can store up to 16KB of data, which can be modified, with a maximum of 64KB and a minimum of 4KB.
Extension: What if the data in a certain row is particularly large and exceeds the size of the node?
MySQL5.7 documentation explains:
For 4KB, 8KB, 16KB and 32KB settings, the maximum row length is slightly less than half the database page. For example: for the default 16KB page size, the maximum row length is slightly less than 8KB, and for the default 32KB page size, the maximum row length is slightly less than 16KB.
For a 64KB page, the maximum row length is slightly less than 16KB.
If a row exceeds the maximum row length, variable-length columns are stored in external pages until the row meets the maximum row length limit. That is to say, varchar and text with variable lengths are stored in external pages to reduce the data length of this row.

MySQL :: MySQL 5.7 Reference Manual :: 14.12.2 File Space Management
- MySQL query speed mainly depends on the read and write speed of the disk, because MySQL only reads one node into the memory each time when querying, and finds the next target through the data of this node. Read the node position, and then read the data of the next node until the required data is queried or the data does not exist. Someone must be asking, don’t we need to query the data in each node? Why isn't the time taken calculated here? This is because after reading the entire node data, it will be stored in the memory. Querying the node data in the memory actually takes a very short time. Coupled with the MySQL query method, the time complexity is almost the same. For
MySQL InnoDB node storage content
In Innodb’s B-tree, the node we often refer to is called a page (page), each page stores user data, and all the pages together form a B-tree (of course it will be much more complicated in practice, but we just need to calculate how many pieces of data can be stored, so for the time being it can be like this understand?).
Page is the smallest disk unit used by the InnoDB storage engine to manage the database. We often say that each node is 16KB, which actually means that the size of each page is 16KB.
This 16KB space needs to store page format information and row format information. The row format information also contains some metadata and user data. Therefore, when we calculate, we must include all these data.
Page format
The basic format of each page, that is, some information that each page will contain, the summary table is as follows:
| Name | Space | Meaning and function, etc. |
|---|---|---|
File Header |
38 bytes | File header, used to record some header information of the page. Includes checksum, page number, two pointers to the preceding and following nodes, page type, table space, etc. |
Page Header |
56 bytes | Page header, used to record page status information. Includes the number of slots in the page directory, the address of the free space, the number of records on this page, the number of bytes occupied by deleted records, etc. |
Infimum & supremum |
26 bytes | is used to limit the boundary value of the current page record, including a minimum value and a maximum value. |
User Records |
Unfixed | User records, the data we insert is stored here. |
Free Space |
Unfixed | The free space is taken from here when user records are added. |
Page Directort |
Unfixed | Page directory is used to store the location information of user data in the page. Each slot will hold 4-8 pieces of user data, and one slot occupies 1-2 bytes. When one slot exceeds 8 pieces of data, it will be automatically divided into two slots. |
File Trailer |
8 bytes | End of file information, mainly used to verify page integrity. |
Schematic diagram:
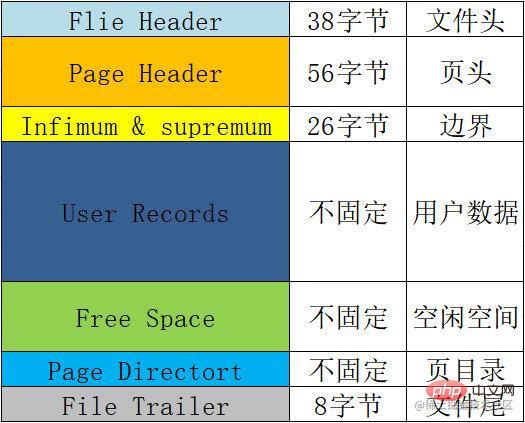
I looked through the official website for a long time and couldn’t find the content of the page format?. . . . I don’t know if it’s because I didn’t write it or because I’m blind. If anyone has found it, I hope they can help me post it in the comment area?
So the table content in the format of the above page is mainly based on learning and summary from some blogs.
In addition, when a new record is inserted into an InnoDB clustered index, InnoDB will try to leave 1/16 of the page free for future insertion and update of index records. If the index records are inserted in order (ascending or descending order), the resulting page has approximately 15/16 of the available space. If records are inserted in random order, approximately 1/2 to 15/16 of the page space is available. Reference documentation: MySQL :: MySQL 5.7 Reference Manual :: 14.6.2.2 The Physical Structure of an InnoDB Index
The memory occupied except User Records and Free Space is 16Row format
First of all, I think it is necessary to mention that the default row format of MySQL5.6 is COMPACT (compact), 5.7 The default row format in the future is DYNAMIC (dynamic). Different row formats are stored in different ways. There are two other row formats. The following content of this article is mainly explained based on DYNAMIC (dynamic). Official document link: MySQL :: MySQL 5.7 Reference Manual:: 14.11 InnoDB row format
(most of the following row format content can be found in it)Each row of records contains the following information, most of which can be found in official documents. What I wrote here is not very detailed. I only wrote some knowledge that can help us calculate space. For more detailed information, you can search for "MySQL row format" online.
| Name | Space | Meaning and function, etc. |
|---|---|---|
| Line record Header information | 5 bytes | Header information of row records Contains some flag bits, data types and other information Such as: deletion flag, minimum record flag, sorting record , data type, The position of the next record in the page, etc. |
| Variable length field list | is not fixed | to save those that can The number of bytes occupied by variable-length fields, such as varchar, text, blob, etc. If the length of the variable-length field is less than 255 bytes, it is represented by 1 byte; If it is greater than 255 bytes, it is represented by 2 bytes. If there are several variable-length fields in the table field, there will be several values in the list. If there are none, they will not be stored. |
| null value list | Unfixed | Used to store whether a field that can be null is null. Each nullable field occupies one bit here, which is the idea of bitmap. The space occupied by this list grows in bytes. For example, if there are 9 to 16 columns that can be null, two bytes are used instead of 1.5 bytes. |
| Transaction ID and pointer field | 6 7 bytes | Friends who know MVCC should know that the data row contains a 6-byte The transaction ID and a 7-byte pointer field. If the primary key is not defined, there will be an additional 6-byte row ID field Of course we all have a primary key, so we do not calculate this row ID. |
| Actual data | Not fixed | This part is our real data. |
Schematic diagram:

There are also a few points to note:
Storage of overflow pages (external pages)
Note: This is a feature of DYNAMIC.
When using DYNAMIC to create a table, InnoDB will strip out the values of longer variable-length columns (such as VARCHAR, VARBINARY, BLOB and TEXT types) and store them in an overflow page , only a 20-byte pointer pointing to the overflow page is reserved on this column.
The COMPACT row format (MySQL5.6 default format) stores the first 768 bytes and the 20-byte pointer in the record of the B-tree node, and the rest is stored on the overflow page .
Whether a column is stored off-page depends on the page size and the total size of the rows. When a row is too long, the longest column is selected for off-page storage until the clustered index record fits on the B-tree page (the document does not say how many?). TEXT and BLOBs less than or equal to 40 bytes are stored directly within the row and are not paged.
Advantages
The DYNAMIC row format avoids the problem of filling B-tree nodes with large amounts of data, resulting in long columns.
The idea behind the DYNAMIC row format is that if part of a long data value is stored off-page, it is usually most efficient to store the entire value off-page.
With DYNAMIC format, shorter columns are kept in B-tree nodes whenever possible, minimizing the number of overflow pages required for a given row.
Storage under different character encodings
Char, varchar, text, etc. need to set the character encoding type. When calculating the occupied space, different encodings need to be considered. occupied space.
varchar, text and other types will have a length field list to record the length they occupy, but char is a fixed-length type, which is a special situation. Assume that the type of field name is char(10), then there are the following Situation:
For fixed-length character encoding (such as ASCII code), the field name will be stored in a fixed-length format. Each character of the ASCII code occupies one byte, so name takes up 10 bytes.
-
For variable-length character encodings (such as utf8mb4), at least 10 bytes will be reserved for name. If possible, InnoDB will save it to 10 bytes by trimming trailing whitespace.
If the spaces cannot be saved after trimming, the trailing spaces will be trimmed to the minimum value of the column value byte length (usually 1 byte).
The maximum length of the column is: Char columns greater than or equal to 768 bytes are treated as variable-length fields (just like varchar) and can be stored across pages. For example, the maximum byte length of the utf8mb4 character set is 4, so a char(255) column may exceed 768 bytes for cross-page storage.
To be honest, I don’t quite understand the design of char. Although I have read it for a long time, including official documents and some blogs, I hope students who understand can clarify their doubts in the comment area:
Regarding character encoding with variable length, is char a bit like a variable-length type? The commonly used utf8mb4 occupies 1 ~ 4 bytes, so the space occupied by char(10) is 10 ~ 40 bytes. This change is quite big, but it does not leave enough space for it, nor does it Is it special to use a variable-length field list to record the space usage of char fields?
Start calculating
Okay, we already know what is stored in each page, and now we have the computing power.
Since I have already calculated the remaining space of the page in the page format above, there will be 15232 bytes available for each page. Let’s calculate the rows directly below.
Non-leaf node calculation
Single node calculation
The index page is the node where the index is stored , that is, non-leaf nodes.
Each index record contains the value of the current index, a 6-byte pointer information,a 5-byte row header , used to point to the pointer to the next layer of data page.
I didn’t find the space occupied by the pointer in the index record in the official document? I refer to other blog posts for this 6 bytes. They said that it is 6 bytes in the source code, but specifically in I don’t know which piece of source code?.
I hope students who know more can clarify their doubts in the comment area.
Assuming that our primary key id is of bigint type, which is 8 bytes, then the space occupied by each row of data in the index page is equal to bytes. Each page can save
Related articles
See more- MySQL detailed explanation of transaction isolation mechanism and implementation principles
- How to increase the number of records in mysql
- An article explaining Node+mysql's SQL injection
- Detailed explanation of MySQL addition, deletion, modification and common pitfalls
- How to solve the garbled problem when php exports mysql csv