
Home >Backend Development >Python Tutorial >Let's talk about python file data analysis, management and extraction
Let's talk about python file data analysis, management and extraction

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2022-08-25 11:46:461878browse

[Related recommendations: Python3 video tutorial]
Prerequisite summary
Python2.0 cannot be read directly The problem of taking the Chinese path requires writing another function. python3.0 cannot be read directly in 2018.
When I use it now, I find that python3.0 can directly read Chinese paths.
You need to bring or create several txt files. It is best to write some data in them (name, mobile phone number, address)
Required
Writing code The best time is to set a few requirements yourself and clarify the following goals:
- Need to read all corresponding files in the corresponding directory path
- Read each corresponding file line by line txt file records
- Use regular expressions to get the mobile phone number of each row
- Save the mobile phone number into excel
Ideas
- 1) Read the file
- 2) Read the data
- 3) Data sorting
- 4) Regular expression matching
- 5) Data go Re
- 6) Data export and save
Code
import glob
import re
import xlwt
filearray=[]
data=[]
phone=[]
filelocation=glob.glob(r'课堂实训/*.txt')
print(filelocation)
for i in range(len(filelocation)):
file =open(filelocation[i])
file_data=file.readlines()
data.append(file_data)
print(data)
combine_data=sum(data,[])
print(combine_data)
for a in combine_data:
data1=re.search(r'[0-9]{11}',a)
phone.append(data1[0])
phone=list(set(phone))
print(phone)
print(len(phone))
#存到excel中
f=xlwt.Workbook('encoding=utf-8')
sheet1=f.add_sheet('sheet1',cell_overwrite_ok=True)
for i in range(len(phone)):
sheet1.write(i,0,phone[i])
f.save('phonenumber.xls')Running result

will generate an excel File

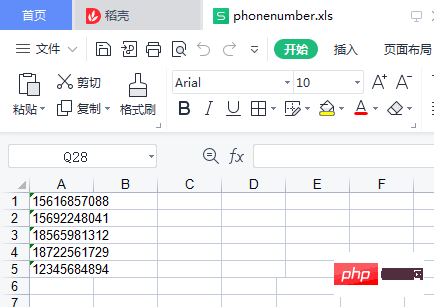
Analysis
import glob import re import xlwt
globe is used to locate the file, re regular expression, xlwt is used for excel
1) Read files
filelocation=glob.glob(r'课堂实训/*.txt')
All txt files in the specified directory
2) Read data
for i in range(len(filelocation)): file =open(filelocation[i]) file_data=file.readlines() data.append(file_data) print(data)
Read the txt files in the path in a loop , read the files sequentially by serial number
Open the file corresponding to each cycle
Read the data of the txt file for each cycle line by line
Use the append() method to add the data of each line to data
Output in the list, you can see that several txt file data exist in the same list in the form of character columns
3) Data sorting
combine_data=sum(data,[])
The lists are merged into one list
4) Regular expression matching plus data deduplication
print(combine_data)
for a in combine_data:
data1=re.search(r'[0-9]{11}',a)
phone.append(data1[0])
phone=list(set(phone))
print(phone)
print(len(phone))set() function: Unordered deduplication, create an unordered set of non-repeating elements
6) Data export and save
#存到excel中 f=xlwt.Workbook('encoding=utf-8') sheet1=f.add_sheet('sheet1',cell_overwrite_ok=True) for i in range(len(phone)): sheet1.write(i,0,phone[i]) f.save('phonenumber.xls')
- ##Workbook('encoding=utf-8'): Set the encoding of the workbook
- add_sheet(' sheet1',cell_overwrite_ok=True): Create the corresponding worksheet
- write(x,y,z):The parameters correspond to rows, columns, and values
Python3 video tutorial】
The above is the detailed content of Let's talk about python file data analysis, management and extraction. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- How Python uses contextvars to manage context variables
- Develop Python with VSCode, these 14 plug-ins are not to be missed!
- Python crawler crawls web page data and parses the data
- Briefly introduce the example of automatic downloading of emails in Python
- How Python extracts csv data and filters specified condition data