
Let's briefly talk about two solutions for Redis to handle interface idempotence.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2022-08-18 17:57:112807browse

Recommended learning: Redis video tutorial
Foreword: Interface idempotenceProblem, for developers It is a public issue that has nothing to do with language. For some user requests, they may be sent repeatedly in some cases. If it is a query operation, it is not a big deal, but some of them involve write operations. Once repeated, it may lead to serious consequences, such as transactions. If the interface is requested repeatedly, repeated orders may be placed. Interface idempotence means that the results of one request or multiple requests initiated by the user for the same operation are consistent, and there will be no side effects caused by multiple clicks.
1. Interface idempotence
1.1. What is interface idempotence
In HTTP/1.1, idempotence has been definition. It describes that one and multiple requests for a resource should have the same result for the resource itself, that is, the first request has side effects on the resource, but subsequent requests will not have side effects on the resource. The side effects here do not damage the results or produce unpredictable results. In other words, any multiple executions have the same impact on the resource itself as one execution.
This type of problem often occurs in the interface:
-
insertoperation. In this case, multiple requests may produce duplicate data. -
updateoperation, if you just update data, for example:update user set status=1 where id=1, there is no problem. If there is still calculation, for example:update user set status=status 1 where id=1, multiple requests in this case may cause data errors.
1.2. Why is it necessary to achieve idempotence
When the interface is called, the information can be returned normally and will not be submitted repeatedly. However, when encountering the following Problems may arise when the situation arises, such as:
- Repeated submission of forms on the front end: When filling in some forms, the user completes the submission and often fails to respond to the user in time due to network fluctuations. , causing the user to think that the submission has not been successful, and then keeps clicking the submit button. At this time, repeated submission of form requests will occur.
- Users maliciously commit fraud: For example, when implementing the function of user voting, if the user repeatedly submits votes for a user, this will cause the interface to receive the voting information repeatedly submitted by the user, which will affect the voting results. Seriously inconsistent with the facts.
- Interface timeout and repeated submission: Many HTTP client tools enable the timeout retry mechanism by default, especially when a third party calls the interface. In order to prevent request failures caused by network fluctuations, timeouts, etc., a retry mechanism will be added. , causing a request to be submitted multiple times.
- Repeated consumption of messages: When using MQ message middleware, if an error occurs in the message middleware and consumption information is not submitted in time, repeated consumption will occur.
This article discusses how to elegantly and uniformly handle this interface idempotence situation on the server side. How to prohibit users from repeatedly clicking and other client-side operations is outside the scope of this discussion.
1.3. Impact on the system after introducing idempotence
Idempotence is to simplify client logic processing and can place operations such as repeated submissions, but it increases This reduces the logical complexity and cost of the server. The main reasons are:
- Change the parallel execution function to serial execution, which reduces the execution efficiency.
- Adds additional business logic to control idempotence, complicating business functions;
Therefore, you need to consider whether to introduce idempotence when using it, according to the actual business scenario Specific analysis shows that, except for special business requirements, generally there is no need to introduce interface idempotence.
2. How to design idempotence
Impotence means the uniqueness of a request. No matter which solution you choose to design idempotent, you need a globally unique ID to mark this request as unique.
- If you use a unique index to control idempotence, then the unique index is unique
- If you use a database primary key to control idempotence, then the primary key is unique
- If you use pessimistic locking, the underlying tag is still a globally unique ID
2.1. Global unique ID
Global unique ID, How do we generate it? You can think about it, how is the database primary key Id generated?
Yes, we can use UUID, but the disadvantages of UUID are obvious. Its string takes up a lot of space, the generated ID is too random, has poor readability, and does not increment.
We can also use Snowflake algorithm (Snowflake) to generate unique IDs.
Snowflake algorithm is an algorithm that generates distributed globally unique IDs. The generated IDs are called Snowflake IDs. This algorithm was created by Twitter and is used for tweet IDs.
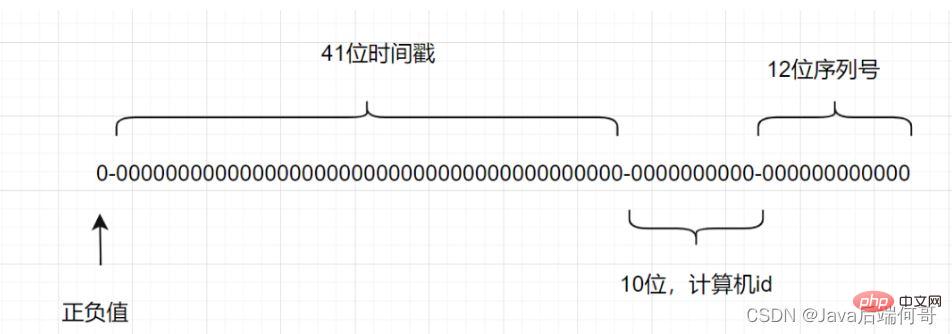
A Snowflake ID has 64 bits.
- Bit 1: The highest bit of long in Java is the sign bit, which represents positive and negative. The positive number is 0 and the negative number is 1. Generally, the generated ID is a positive number, so the default is 0.
- The next 41 bits are the timestamp, representing the number of milliseconds since the selected epoch.
- The next 10 digits represent the computer ID to prevent conflicts.
- The remaining 12 bits represent the serial number of the ID generated on each machine, which allows multiple Snowflake IDs to be created in the same millisecond.
Of course, for globally unique IDs, you can also use Baidu’s Uidgenerator or Meituan’s Leaf .
2.2. Basic process of idempotent design
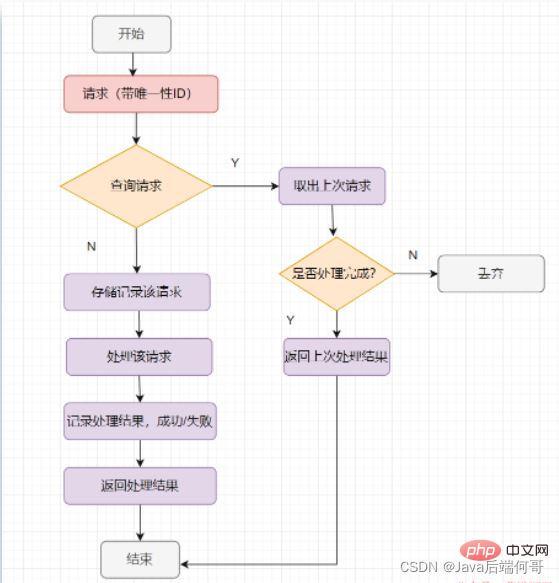
The process of idempotent processing, in the final analysis, is to filter the requests that have been received. Of course, the requests must have A globally unique ID tag ha. Then, how to determine whether the request has been received before? Store the request. When receiving the request, first check the storage record. If the record exists, the last result will be returned. If the record does not exist, the request will be processed.
The general idempotence processing is like this, as follows:
3. Common solutions for interface idempotence
3.1 , Passing the unique request number downstream
What you may think of is that as long as the request has a unique request number, you can use Redis to do this deduplication - as long as the unique request number exists in Redis, it is proved If processed, it is considered to be a duplicate.
Program description:
The so-called unique request sequence number actually means that every time a request is made to the server, it is accompanied by a unique and non-repeating sequence number in a short period of time. The sequence number can be an ordered sequence number. The ID can also be an order number, which is generally generated by the downstream. When calling the upstream server interface, the serial number and the ID used for authentication are appended.
When the upstream server receives the request information, it combines the serial number and the downstream authentication ID to form a Key for operating Redis, and then queries Redis to see if there is a key-value pair for the corresponding Key. According to The result:
- If it exists, it means that the downstream request for the sequence number has been processed. At this time, you can directly respond to the error message of the repeated request.
- If it does not exist, use the Key as the key of Redis, use the downstream key information as the stored value (such as some business logic information passed by the downstream provider), store the key-value pair in Redis, and then Then execute the corresponding business logic normally.
Applicable operations:
- Insert operation
- Update operation
- Delete operation
Usage restrictions :
- Requires third party to pass unique serial number;
- Needs to use third-party component Redis for data verification;
Main process:
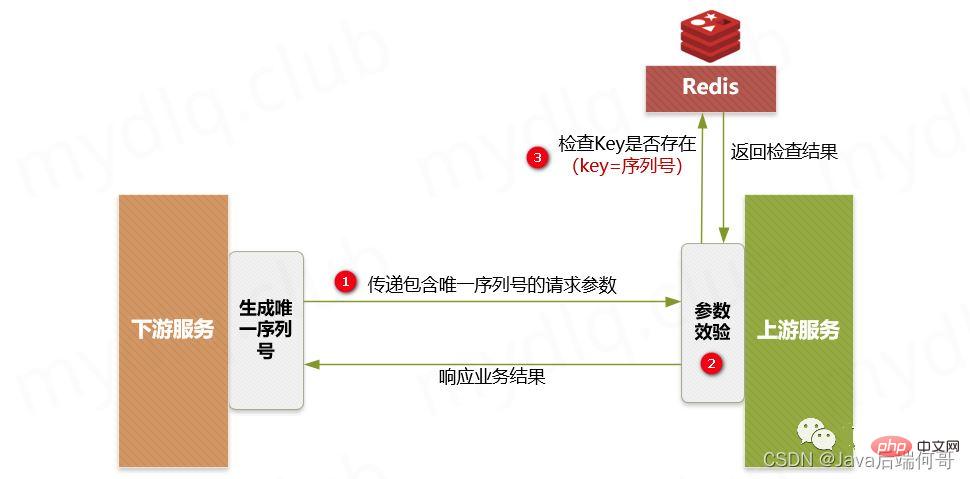
Main steps:
- The downstream service generates a distributed ID as a serial number, and then executes the request to call the upstream interface, along with the "unique serial number" and the requested "Authentication Credential ID".
- The upstream service performs security verification and detects whether there is a "serial number" and "credential ID" in the parameters passed downstream.
- The upstream service detects whether there is a Key composed of the corresponding "serial number" and "authentication ID" in Redis. If it exists, it will throw a repeated execution exception message and then respond to the corresponding downstream error message. If it does not exist, the combination of "serial number" and "authentication ID" will be used as the Key, and the downstream key information will be used as the Value, and then stored in Redis, and then the subsequent business logic will be executed normally.
In the above steps, when inserting data into Redis, the expiration time must be set. This ensures that within this time range, if the interface is called repeatedly, judgment and identification can be made. If the expiration time is not set, it is likely that an unlimited amount of data will be stored in Redis, causing Redis to not work properly.
3.2. Anti-duplication Token
Program description:
In response to the client’s continuous clicks or the caller’s timeout retry, for example Submitting an order can use the Token mechanism to prevent repeated submissions. To put it simply, the caller first requests a global ID (Token) from the backend when calling the interface, and carries this global ID with the request (it is best to put the Token in Headers). The backend needs to use this Token. As Key, the user information is sent to Redis as Value for key value content verification. If the Key exists and the Value matches, the delete command is executed, and then the subsequent business logic is executed normally. If there is no corresponding Key or Value does not match, a repeated error message will be returned to ensure idempotent operations.
Usage restrictions:
- Need to generate a globally unique Token string;
- Need to use the third-party component Redis for data validation;
Main process:
The server provides an interface for obtaining Token. The Token can be a serial number, a distributed ID or a UUID string.
The client calls the interface to obtain the Token. At this time, the server will generate a Token string.
Then store the string in the Redis database, using the Token as the Redis key (note the expiration time).
Return the Token to the client. After the client obtains it, it should be stored in the hidden field of the form.
When the client executes and submits the form, it stores the Token in the Headers and carries the Headers with it when executing the business request.
After receiving the request, the server gets the Token from the Headers, and then uses the Token to find whether the key exists in Redis.
The server determines whether the key exists in Redis. If it exists, it deletes the key and then executes the business logic normally. If it does not exist, an exception will be thrown and an error message for repeated submissions will be returned.
Note that under concurrent conditions, atomicity needs to be ensured when executing Redis data search and deletion, otherwise idempotence may not be guaranteed under concurrency. Its implementation can use distributed locks or use Lua expressions to log out query and delete operations.
Recommended learning: Redis video tutorial
The above is the detailed content of Let's briefly talk about two solutions for Redis to handle interface idempotence.. For more information, please follow other related articles on the PHP Chinese website!