
Home >Java >javaTutorial >Java knowledge summary and detailed explanation of JVM
Java knowledge summary and detailed explanation of JVM

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2022-07-12 17:20:032195browse
This article brings you relevant knowledge about java, which mainly organizes JVM-related issues, including JVM memory area division, JVM class loading mechanism, VM garbage collection, etc. Let’s take a look at the content below. I hope it will be helpful to everyone.

Recommended study: "java video tutorial"
1. JVM memory area division
Why does JVM need How to divide these areas? The JVM memory is applied from the operating system, and the JVM divides these into small modules according to functional requirements. In this way, a large site can be divided into small modules, and then each The module is responsible for its own functions. Then let’s take a look at the functions of these areas!
1. Program counter
The program counter is the smallest in the memory area, where the address of the next instruction to be executed is saved. (The instruction is the bytecode. To run a general program, the JVM needs to load the bytecode into the memory, and then The program then takes out the instructions one by one from the memory and puts them on the CPU for execution, so it must remember which instruction is currently executed and where the next one is, because the CPU does not only provide services to one process, but to all All processes provide services and execute programs concurrently. And because the operating system schedules execution in units of threads, each thread must have its own execution location, that is, each thread needs to have a program. Counter to record the position!)2. Stack
The stack mainly stores
local variables and method call information. As long as it involves the call of a new method, it will There is a "push" operation. Every time a method is executed, there will be a "push" operation, and each thread has a copy of the stack.
Therefore, for recursion, it must be It is necessary to control the recursive conditions, otherwise a stack overflow (StackOverflowException) exception is likely to occur!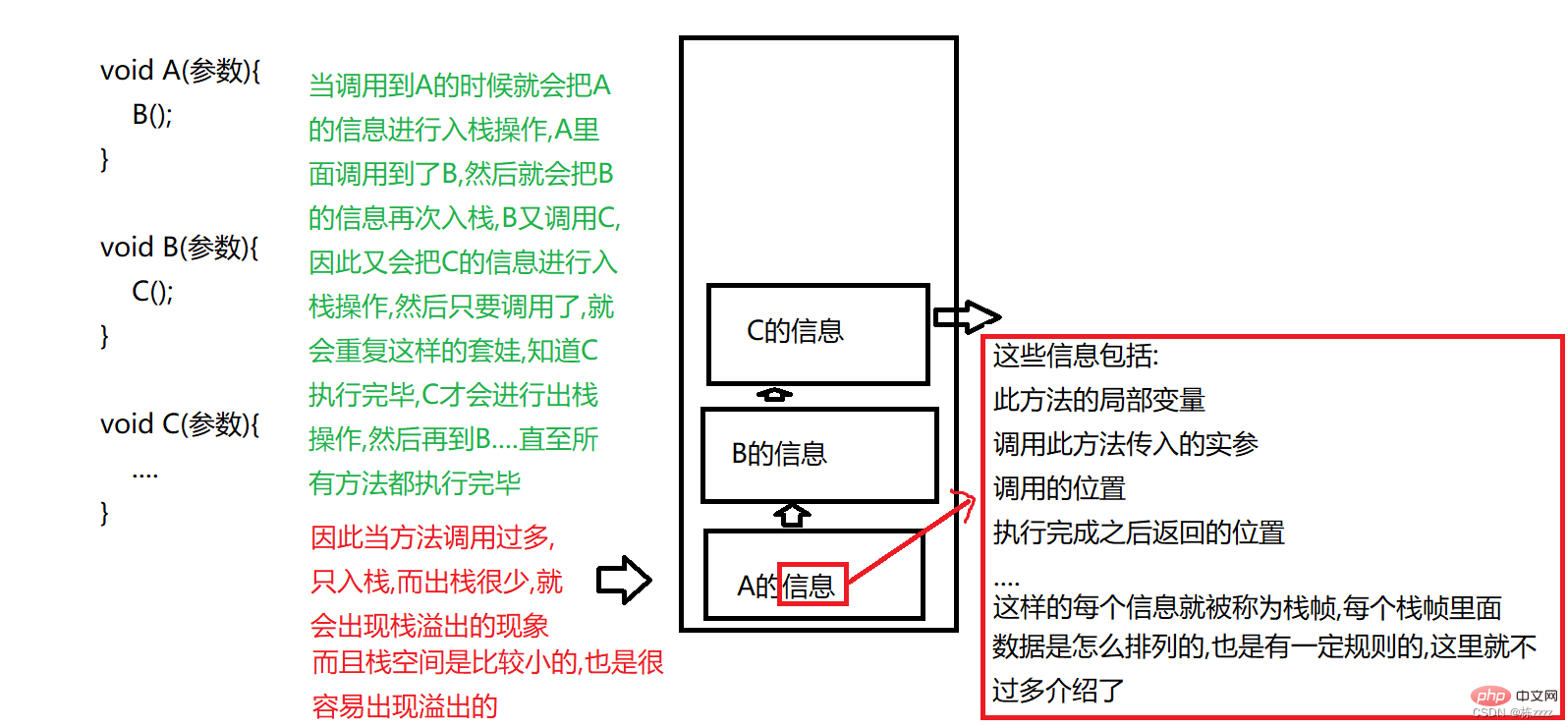
3. Heap
The heap is the largest area of space in the memory, and the heap is the largest area of space in each process. There is only one copy. Multiple threads in the process share a heap, which mainly stores new objects and member variables of the objects. For example, String s = new String() if s here is in the method That is, local variables are on the stack. If s is a member variable, it is on the heap. New String() is the ontology of the object, and the object is on the heap. This is where it is easy to confuse. In addition, the heap is also One important point is about garbage collection, which will be introduced in detail later!
4. Method areaThe method area
stores "class objects", The .java code you usually write will become .class (binary bytecode) after being translated by the compiler. Then .class will be loaded into memory and constructed into a class object by the JVM (the loading process is called "class loading"), and these class objects will be stored in the method area, which specifically describes what the class looks like (the name of the class, the members of the class and their member names, member types, the methods of the class and their Method name, method type, and some instructions... In addition, a very important thing is stored in the class object, which is static members. Generally, members modified by static become class attributes, and ordinary methods are called instance attributes. This is There is a big difference)!
The above introduction is a common area in JVM, and the memory area division of some JVM is not necessarily in line with the actual situation. In the process of JVM implementation, the area The divisions are different. There may be differences in different versions of JVM from different manufacturers. However, for us ordinary programmers, as long as we are not implementing the JVM, we don’t need to understand it so deeply. Let’s talk about the above. Just understand a few common areas!
Class loading is actually an important core function of designing a runtime environment Function, this is very heavyweight, so I will briefly introduce it here!2. JVM class loading mechanism
The above is the specific process of class loading. The last Using and Unloading are the processes of use and will not be introduced. Let me introduce the first three big steps:
1.Loading(Loading)
In the loading phase, will first find the corresponding .class file, then open and read (according to the byte stream) the .class file, and initially generate a Class object , this is different from the completed class loading (class Loading), don’t get confused!
The specific format of the class file (if you want to implement a Java compiler, you must construct it in this format , to implement JVM, you must load it according to this format!): 
If you observe this format, you can see that the .class file expresses all the core information in the .java file, but it is organized The format has changed, so the loading link will initially fill in the read information into the class object
2. Linking
Linking is generally the establishment of multiple entities. The connection between
2.1.Verification(verification)
Verification is a verification process, mainly toverify whether the content read exactly matches the format specified in the specification, if it is found that the read data format does not comply with the specification, the class loading will fail and an exception will be thrown!
2.2.Preparation(preparation)
The Preparation phase isofficial At the stage of allocating memory for defined variables (static variables, which are variables modified by static) and setting the initial value of class variables, memory will be allocated for each static variable and set to a value of 0!
2.3.Resolution (analysis)
The resolution stage is the process in which the Java virtual machine replaces the symbol reference in the constant pool with a direct reference , which is also the process of initializing the constant. The constant in the .class file is Centrally placed, each constant will have a number, and the initial situation in the structure in the .class file is just the record number, and then the corresponding content can be found based on this number, and then filled into the class object!
3.Initialization(Initialization)
The Initialization stage is the real initialization of class objects (according to the code written), especially for static members
4. Typical interview questions
class A {
public A(){
System.out.println("A的构造方法");
}
{
System.out.println("A的构造代码块");
}
static {
System.out.println("A的静态代码块");
}}class B extends A{
public B(){
System.out.println("B的构造方法");
}
{
System.out.println("B的构造代码块");
}
static {
System.out.println("B的静态代码块");
}}public class Test extends B{
public static void main(String[] args) {
new Test();
new Test();
}}
You can try to write the output results yourself
To do such questions, you need to grasp several major principles:
The static code block will be executed during the class loading phase. If you want to create an instance, you must first perform class loading.
The static code block is only executed once during the class loading phase. , no other stages will be executed again
The construction method and construction code block will be executed every time they are instantiated, and the construction code block will be executed before the construction method~~
The parent class is executed first, and the subclass is executed last!
The program is executed from main, main’s Test method, so to execute main You need to load the Test class first
Only when this class is involved, the things in the class will be loaded
输出结果: A的静态代码块 B的静态代码块 A的构造代码块 A的构造方法 B的构造代码块 B的构造方法 A的构造代码块 A的构造方法 B的构造代码块 B的构造方法
5. Parental delegation model
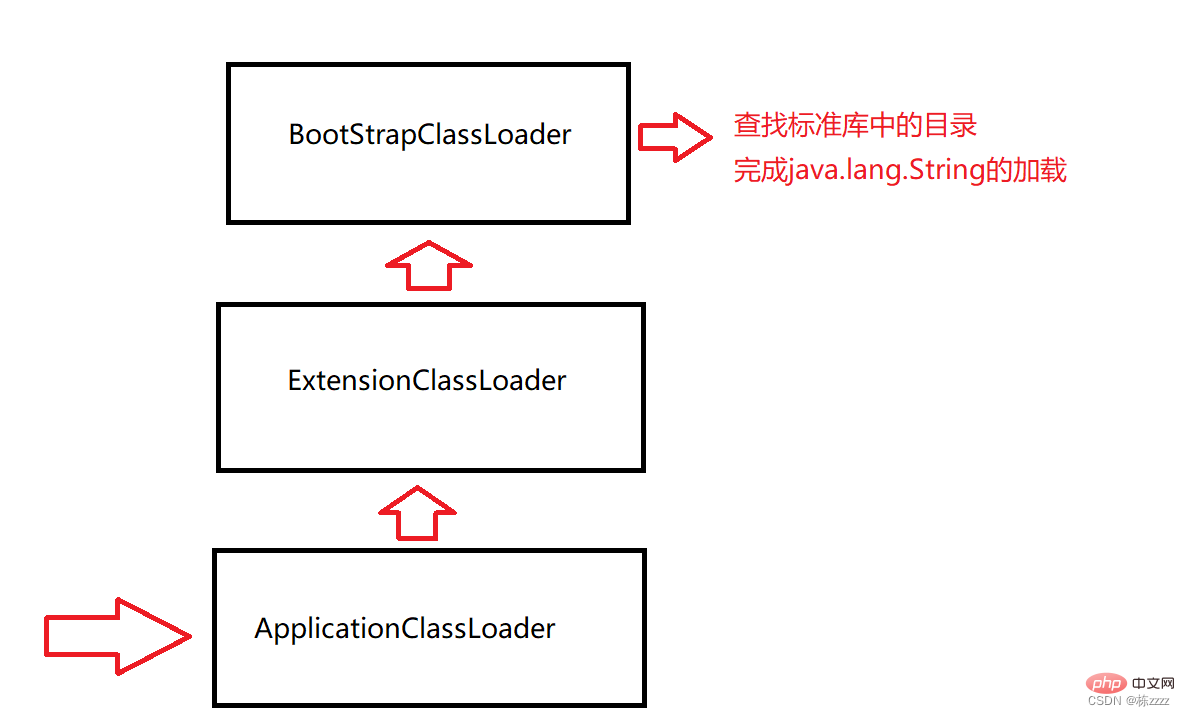
This thing is a link in class loading. It is in the Loading stage (the earlier part). The parent delegation model describes the class loader in the JVM. How to use the fully qualified name of the class (java.lang.String)The process of finding the .class file. The class loader here is an object specially provided by the JVM. It is mainly responsible for class loading, so the process of finding files is also responsible for the class loader. There are many places where .class files may be placed, and some of them must be placed in the JDK directory. , some are placed in the project directory, and some are in other specific locations, so the JVM provides multiple class loaders, each class loader is responsible for a slice, and there are mainly 3 default class loaders:
BootStrapClassLoader: Responsible for loading classes in the standard library (String, ArrayList, Random, Scanner...)
ExtensionClassLoader: Responsible for loading JDK extension classes (Rarely used now)
ApplicationClassLoader: Responsible for loading classes in the current project directory
In addition, programmers can also customize class loading To load classes in other directories, Tomcat has customized a class loader to specifically load .classes in webapps
The parent delegation model describes this The process of finding the directory is how the above class loader cooperates.
Consider looking for java.lang.String:
When the program starts, it will first enter the ApplicationClassLoader Class loader
ApplicationClassLoader class loader will check whether its parent loader has been loaded. If not, call the parent class loader ExtensionClassLoader
The ExtensionClassLoader class loader will check whether its parent loader has been loaded. If not, call the parent class loader BootStrapClassLoader
BootStrapClassLoader The class loader will also check whether its parent loader has been loaded, and then finds that there is no parent, so it scans the directory it is responsible for
Then the java.lang.String class can be found in the standard library, and then the BootStrapClassLoader loader is responsible for the subsequent loading process, and the search process is over!

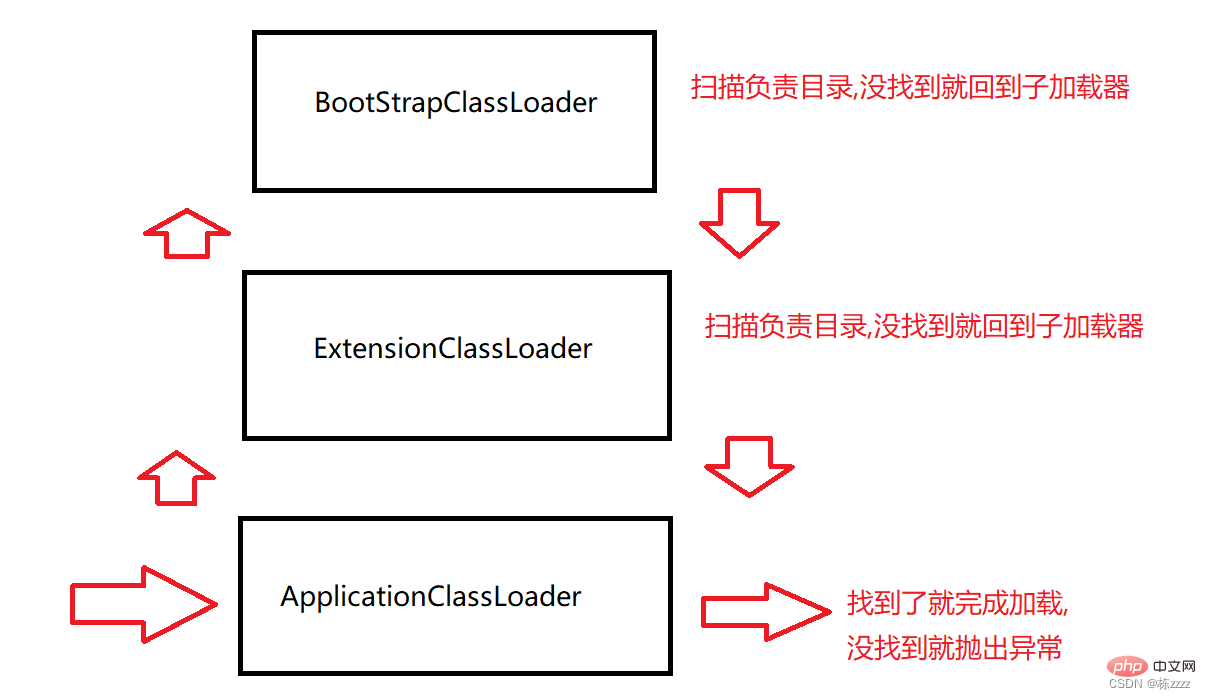
Consider looking for the Test class you wrote:
When the program starts, it will first enter the ApplicationClassLoader class loader
ApplicationClassLoader class loader will check whether its parent loader has been loaded. If not, call the parent class loader ExtensionClassLoader
ExtensionClassLoader class The loader will check whether its parent loader has been loaded. If not, it will call the parent class loader BootStrapClassLoader
BootStrapClassLoader class loader will also check it. Has the parent loader been loaded, and then found that there is no father, so it scans the directory it is responsible for. If it is not scanned, it will return to the child loader to continue scanning
ExtensionClassLoader Scan the directory you are responsible for, but it is not scanned, and then go back to the sub-loader to continue scanning
ApplicationClassLoader also scans the directory you are responsible for, and the classes you write are in your own project directory Download, so it can be found, and then subsequent class loading is completed by ApplicationClassLoad. At this time, the link of searching the directory is over~~ (In addition, if ApplicationClassLoader does not find them, it will throw a ClassNotFoundException exception)
This set of search rules is called the parent delegation model. So why is the JVM designed like this? The reason is that Once the class written by the programmer has the same fully qualified class name, Now, you can also successfully load classes in the standard library instead of classes written by yourself!!!
In addition, if it is a custom class loader, do you need to comply with this parent delegation model?
Answer It can be complied with or not, it mainly depends on the requirements. For example, if Tomcat loads a class in a webapp, it will not be complied with, because it is impossible to find the class loader if it complies with the above!
3. JVM garbage collection
Garbage collection mechanism (GC) in JVM Generally, when writing code, it often involves applying for memory, such as creating a variable, new an object, and calling a method. Loading classes... The timing of applying for memory is generally clear (you need to apply for memory if you need to save certain data), but the timing of releasing memory is not so clear, and it will not work if you release it too early (if you still need to used, the result has been released, which means that there is no memory available, and the data has "nowhere to go"), it will not work if it is released late (released late, a large amount of hoarding is likely to gradually make the available memory gradually If it becomes less, it is very likely that there will be a memory leak problem (that is, there is no memory to use), so the release of memory must be just right!
And the job of garbage collection is additionally done by the runtime environment A lot of work is required to complete the memory release operation, which greatly reduces the mental burden on programmers. However, garbage collection also has disadvantages: ① It consumes additional overhead (more resources are consumed); ② It may affect the smooth running of the program (garbage collection often introduces STW problems (Stop The World))
Of course not Well, let’s use the four areas above to explain:Program counter: This memory is of fixed size and does not involve release, so there is no need for GC;
Let’s take a closer look at how to recycle:
- Stack: When the function call is completed, the corresponding stack frame is automatically released, and GC is not required;
- Heap: This is the memory that requires GC the most. A large amount of memory in general code is on the heap. ;
Which of these three areas need to be released? For such
will not be released. Only when the object is no longer used is it truly released, so there will be no half-object situation in the GC. Therefore, the basic unit of garbage collection is the object, not bytes!Method area: Class object, class loading, and only when the class is unloaded, the memory needs to be released, and the unloading operation is very low-frequency, so it almost does not involve GC!
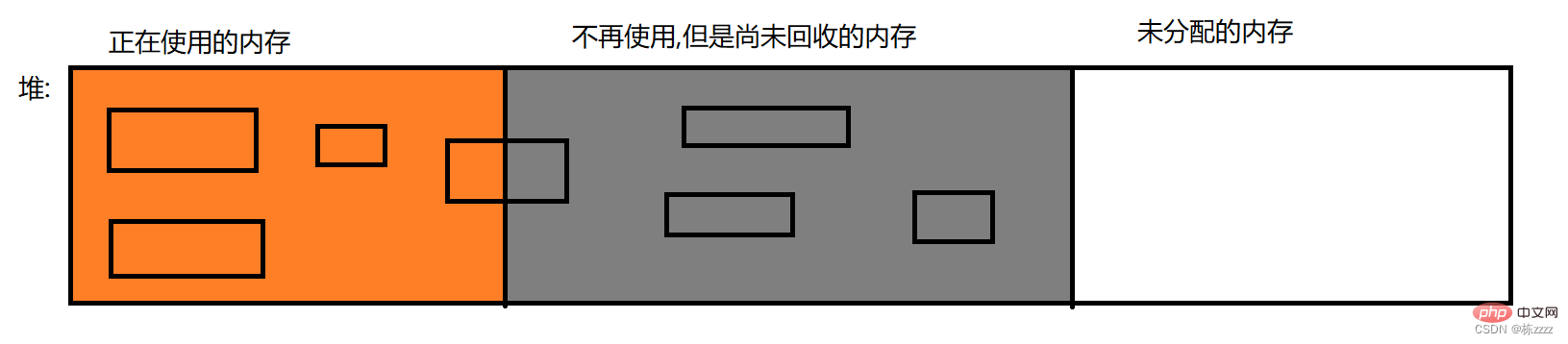 objects that are partly in use and partly no longer used, the overall
objects that are partly in use and partly no longer used, the overall 1. Find garbage/determine garbage
There are currently two mainstream solutions:
1.1. Based on reference counting
This is not the solution adopted in Java, it is the solution of Python and other languages, so I will briefly introduce it here without going into too much~
And the reference counting The specific idea is that for each object, an additional small piece of memory will be introduced to save how many references this object has pointing to it
And such a reference count has two flaws:
- Space utilization is relatively low!!!, each new object needs to be equipped with a counter, assuming a counter of 4 bytes, if the object itself is relatively large (hundreds of words section), then this counter does not matter, and once the object itself is relatively small (4 bytes), then 4 more bytes will be equivalent to doubling the space utilization, so the space utilization will Relatively low~
-
There is a problem of circular references
Therefore, there will be a lot of problems when using reference counting, and think about Python, PHP and the like The language does not only use reference counters to complete GC, but also cooperates with some other mechanisms to complete it!
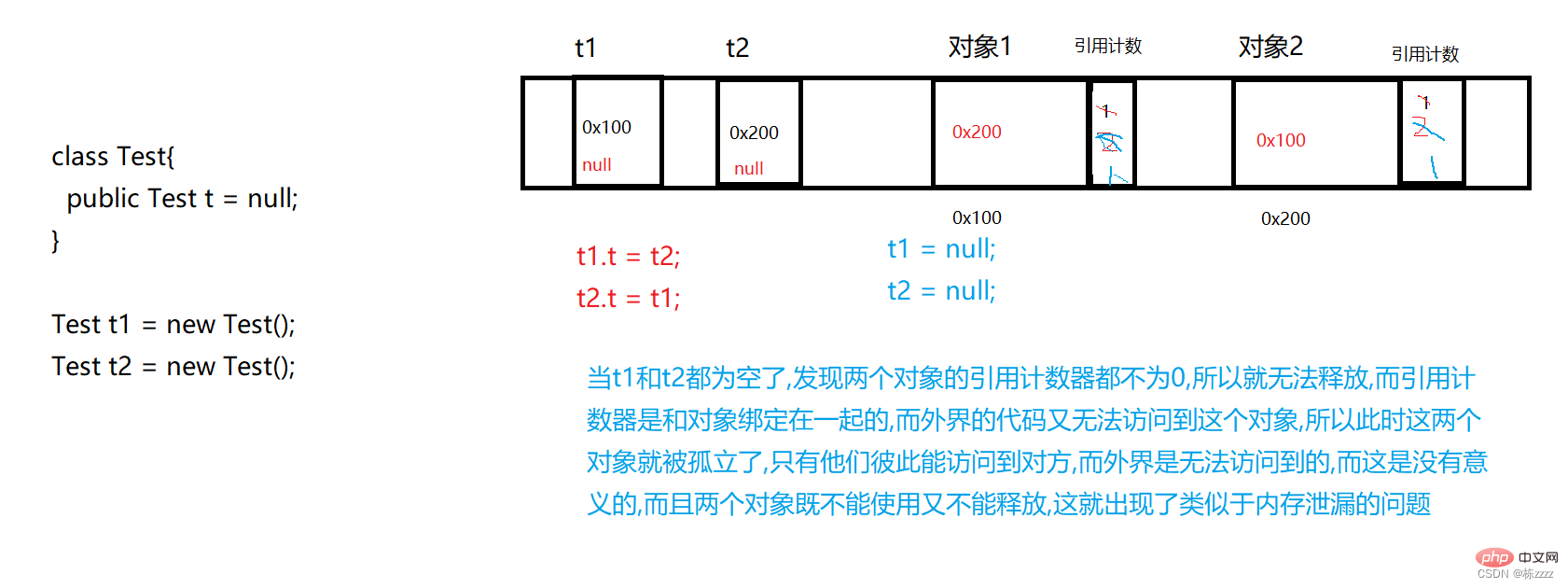
1.2. Based on reachability analysis
Reachability analysis is The solution adopted by Java, reachability analysis is through some additional threads, periodically scanning objects in the entire memory space , with some starting positions (GCRoots), and then it is similar to depth-first traversal (can be imagined as a tree), mark all accessible objects (marked objects are reachable objects), and objects that are not marked are unreachable objects, that is, garbage, and should Released!
The GCRoots here (start traversing from these locations):
- Local variables on the stack;
- Objects pointed to by references in the constant pool;
- The object pointed to by the static members in the method area;
So the advantage of reachability analysis is that it solves the shortcomings of reference counting: low space utilization and circular references;The shortcomings of reachability analysis are also obvious: The system overhead is large, and traversing it once may be slow~
So finding garbage is also very simple. The core is to confirm whether this object will be used in the future. It will still be used, see if there are any references pointing to it, and should it be released?
2. Release garbage
Now that we have clarified what garbage is, the next step is to recycle the garbage. There are three basic strategies for recycling garbage. Let’s take a look!
2.1. Mark - Please remove

The mark here is the reachability The process of analysis, and clearing is to release memory. Assume that the above is a piece of memory, and the checked area represents garbage. If you release it directly at this time, although the memory is returned to the system, the released memory is discrete. , are not continuous, and the problem caused by this is "memory fragmentation". There may be a lot of free memory. Assume that the total is 1G. If you want to apply for 500MB of space at this time, you can apply for it, but It is possible that the application fails here (because the 500MB to be applied for is continuous memory, and the memory applied for each time is continuous memory space, and the 1G here may be the sum of multiple fragments), so this problem is actually It greatly affects the running of the program
2.2. Copy algorithm
Since the above mark-clear strategy may cause memory fragmentation problem, introduced the copy algorithm to solve this problem Question 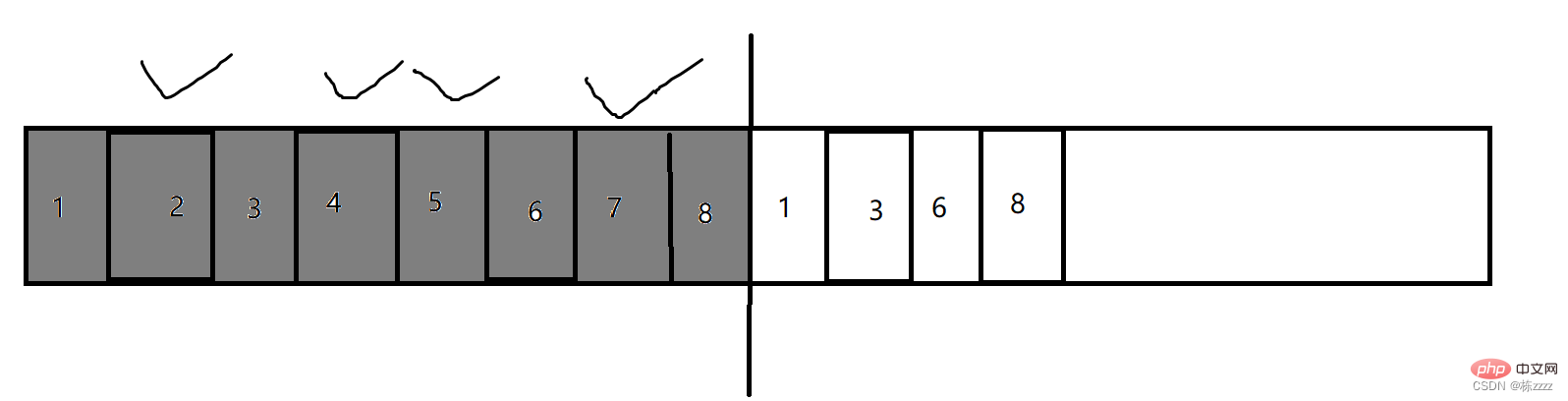
The above is a piece of memory. The strategy of the copy algorithm is to use half of the memory, throw away half, and not use all of it. In the normal use, copy the non-junk parts to the other half (this copy It is processed internally by the JVM, no need to worry), and then all the previously used memory is released, so that the problem of memory fragmentation is easily solved!
So the copy algorithm has two big problems:
- The memory space utilization is low (only general memory is used);
- If there are many objects to be retained and few objects to be released, then the cost of copying will be very high;
2.3. Marking and sorting
This is another further improvement for the copy algorithm!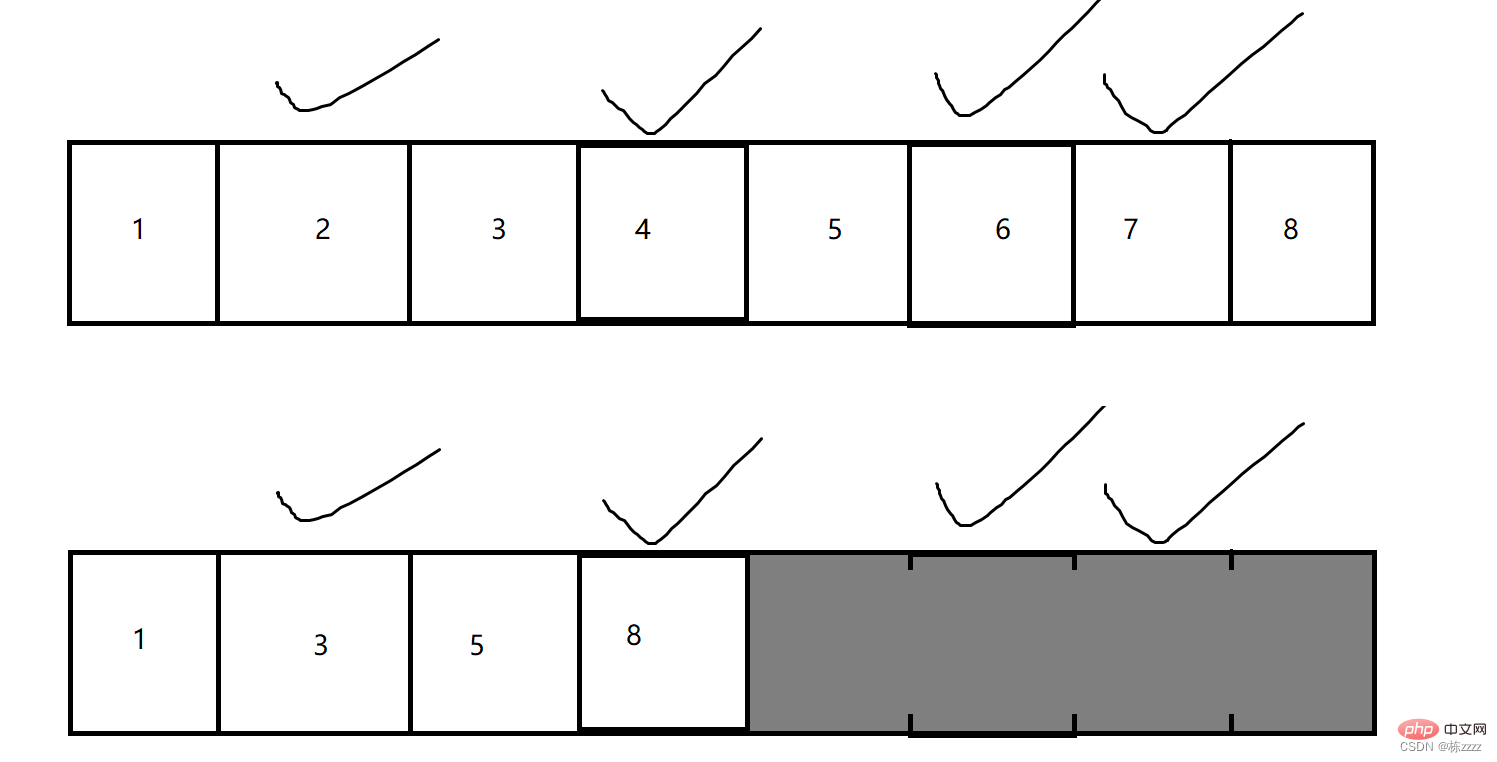
The strategy of marking and sorting isGather the memory that is not garbage together, and then release all the subsequent memory, similar to the operation of deleting middle elements in a sequence table, there is a moving process!
This solution has high space utilization , but there is still no way to solve the problem of high overhead of copying/moving elements!
Although the above three solutions can solve the problem, they all have their own shortcomings, so in fact, the implementation in the JVM will The combination of multiple solutions is called "generational recycling"!!!
2.4 Generational recycling
The generation here is to classify objects (according to the "age" of the object) Classify, and the age here means that an object has survived a round of GC scans, which is called "one year older"), and for objects of different ages, different plans are adopted!!!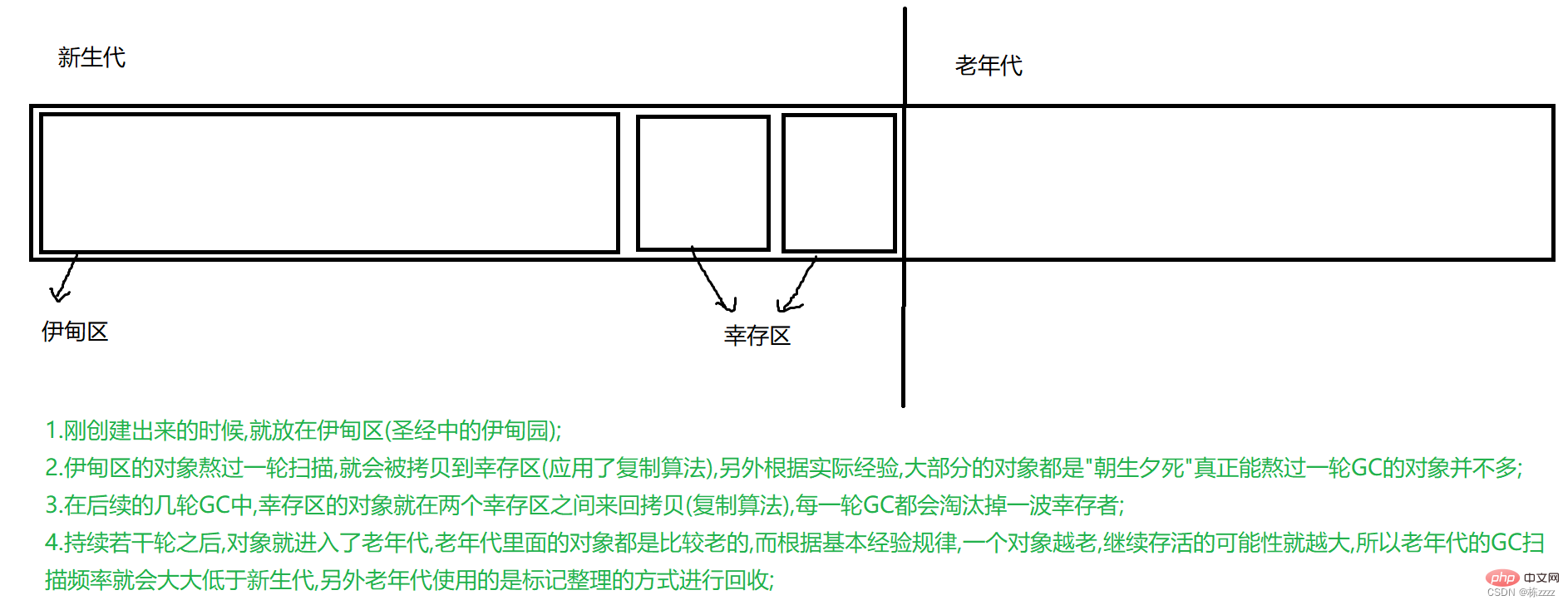
This is the entire generational recycling process!
3. Garbage Collector
The above search for garbage and release of garbage are just algorithmic ideas, not a real implementation process. The real implementation of the above algorithm module is the "garbage collector". Here are some specific garbage collectors:
3.1. Serial collector and Serial Old collector
The Serial collector is a garbage collector provided for the new generation, and the Serial Old collector is The garbage collector provided for the old generation. These two collectors collect serially, and when scanning and releasing garbage, the business thread has to stop working, so in this way, the scan is full and the release is slow. And it can also produce serious STW!
3.2.ParNew collector, Parallel Scavenge collector and Parallel Old collector
ParNew collector, Parallel Scavenge collector are all provided to the new generation , Parallel Scavenge collector adds some parameters compared to ParNew collector, which can control the STW time, but has some more powerful functions. Parallel Old collector is provided for the old generation. These three collectors are all parallel collections. Yes, it introduces a multi-threaded approach to solve the functions of scanning garbage and releasing garbage!
The above collectors are left over from history, which are older garbage collection methods. In addition, Introducing two updated garbage collectors!
3.3.CMS collector
CMS collector is designed more cleverly, and its original intention is to shorten the STW time as much as possible, Java8 uses the CMS collector. Here is a brief introduction to the process of the CMS collector:
- Initial mark: very fast, will cause a short STW (just find GCRoots);
- Concurrent marking: It is very fast, but can be executed concurrently with the business thread, and will not generate STW;
- Remarking: 2 business codes may affect the results of concurrent marking (the business thread is executing, It is possible to generate new garbage), so this step is to fine-tune the results of 2. Although it will cause STW, it is only fine-tuning and the speed is very fast;
- The above three steps are all based on reachability analysis!
Recycling memory: It is also executed concurrently with the business thread, and STW will not be generated. This is based on marking and sorting;
The only full-region garbage collector. The G1 collector has been used since Java11. This collector divides the entire memory into many small regions, and marks these regions differently. Some Regions store new generation objects, and some Regions store old generation objects. Then, when scanning, several Regions are scanned at once (it is not necessary to complete the scan in one round of GC, and it needs to be scanned multiple times). This will have an impact on the business code. It is also the smallest.
The core idea of these two new collectors is to break them into parts. G1 can currently be optimized to make the STW pause time less than 1ms, which is completely acceptable! The above is about the JVM After some study, the main thing about the collector here is to understand it, mainly because the above garbage collection ideas are very important!!!Recommended study: "java video tutorial"
The above is the detailed content of Java knowledge summary and detailed explanation of JVM. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Is float a JavaScript keyword?
- Four ways to implement multithreading in Java
- Detailed explanation of JavaScript prototype and prototype chain knowledge points
- [Hematemesis compilation] 2023 Java basic high-frequency interview questions and answers (Collection)
- What is a closure? Let's talk about closures in JavaScript and see what functions they have?