



This article brings you relevant knowledge about SQL, which mainly organizes issues related to SQL statement knowledge, including some basic syntax of SQL statements, SQL statement improvements, etc. Let’s take a look at it together, I hope it will be helpful to everyone.
SQL Tutorial"
1. Introduction to SQLSQL (Structured Query Language: Structured Query Language)
is used to manage relational database management systems (RDBMS). The scope of SQL includes data insertion, query, update and deletion, database schema creation and modification, and data access control. 1. What is a databaseDatabase (DB database) Concept: Data warehouse software installed on the operating system can store a large amount of data 500wFunction: Store data management data2. Database classificationRelational database (SQL)MySQL Oracle SqlServer DB2 SQLite Through tables and rows between tables and the relationship between columns to store data student information table attendance table...
Non-relational database (noSQL) Not Only
Non-relational database objects are stored through the object's own Properties to determine
- SQL refers to Structured Query Language, the full name is Structured Query Language.
- SQL allows you to access and manipulate databases, including inserting, querying, updating, and deleting data.
- SQL became an ANSI (American National Standards Institute) standard in 1986 and an International Organization for Standardization (ISO) standard in 1987.
- SQL executes queries against the database
- SQL can retrieve data from the database
- SQL can insert new records in the database
- SQL can Update data in the database
- SQL can delete records from the database
- SQL can create a new database
- SQL can create a new table in the database
- SQL can Create stored procedures in the database
- SQL can create views in the database
- SQL can set permissions on tables, stored procedures and views
Create a new table based on an existing table:
**A: **create table tab_new like tab_old (use the old table to create a new table) **B: **create table tab_new as select col1,col2… from tab_old definition only
Note: The column cannot be deleted after it is added. In DB2, the data type cannot be changed after the column is added. The only thing that can be changed is to increase the length of the varchar type.
6. Add primary keyAlter table tabname add primary key(col) Description:
create [unique] index idxname on tabname(col….)
Delete index: drop index idxnameNote: The index cannot be changed. If you want to change it, you must delete it and rebuild it.
8. Create viewcreate view viewname as select statement
Delete view:drop view viewname
9. Several simple sql statements for table operationsSelect:
select * from table1 where rangeInsert:
insert into table1(field1,field2) values(value1,value2)Delete:
delete from table1 whereRange update:
update table1 set field1=value1 whereRange lookup
select * from table1 where field1 like '%value1%' —like's syntax is very subtle, check the information!sort:
select * from table1 order by field1,field2 [ desc]total:
select count as totalcount from table1sum:
select sum(field1) as sumvalue from table1average:
select avg(field1) as avgvalue from table1maximum :
select max(field1) as maxvalue from table1MINIMUM:
select min(field1) as minvalue from table110. Several advanced query operators
UNION operator
The UNION operator combines other two result tables (such as TABLE1 and TABLE2) and eliminates A resulting table is derived for any duplicate rows in the table. When ALL is used with UNION (that is, UNION ALL), duplicate rows are not eliminated. In both cases, every row in the derived table comes from either TABLE1 or TABLE2.
EXCEPT Operator
EXCEPTOperator derives a result table by including all rows that are in TABLE1 but not in TABLE2 and eliminating all duplicate rows. When ALL is used with EXCEPT (EXCEPT ALL), duplicate rows are not eliminated.
INTERSECT Operator
INTERSECTThe operator derives a result table by including only the rows that are in both TABLE1 and TABLE2 and eliminating any duplicate rows. When ALL is used with INTERSECT (INTERSECT ALL), duplicate rows are not eliminated.
**Note:** Several query result rows using operator words must be consistent.
11.Use outer join
11.1.left join
left (outer) join: left outer join (left join): The result set includes matching rows from the join table and all rows from the left join table.
select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUT JOIN b ON a.a = b.c
11.2.right join
right (outer) join: right outer join (right join): the result set includes both matching join rows of the joined table and all rows of the right joined table .
11.3.full/cross join
full/cross (outer) join: full outer join: not only includes matching rows of the symbolic connection table, but also includes all records in the two connected tables.
Case
For example, data with the following relationship:
1, inner join
2.1, full outer join is equal to full join
2.2, full outer join but a.Key is null or b.Key is null
3.1, left outer join is equal to left join
3.2, left outer join but b.Key is null
Cartesian Product
12.如何修改数据库的名称
sp_renamedb 'old_name', 'new_name'
13.临时表
13.1.临时表的概念
在我们操作的表数据量庞大而且又要关联其他表进行查询的时候或者我们操作的数据是临时性数据且在短期内会有很多DML操作(比如购物车)的时候或者我们做查询时需要连接很多个表的时候,如果直接操作数据库的业务表可能效率很低,这个时候我们就可以借助临时表来提升效率。
临时表顾名思义,是一个临时的表,数据库不会将其序列化到磁盘上(有些也会序列化到磁盘上)而是存在于数据库服务器的内存中(因此会增加数据库服务器内存的消耗),在使用完之后就会销毁。临时表分为两种:会话临时表和全局临时表,区别在于可用的作用域和销毁的时机不同。会话临时表只在当前会话(连接)内可用,且在当前会话结束(断开数据库连接)后就会销毁;全局临时表创建后在销毁之前所有用户都可以访问,销毁的时机是在创建该临时表的连接断开且没有其他会话访问时才销毁,实际上在创建全局临时表的会话断开后,其他用户就已经不能在访问该临时表了,但此时该临时表并不会立即销毁,而是等所有正在使用该全局临时表的会话(或者说连接)断开之后才会销毁。当然有时考虑到内存占用的问题,我们也可以手动销毁(DROP)临时表。
目前大多数数据库厂商(Oracle、Sql Server、Mysql)都支持临时表,但不同的数据库创建和使用临时表的语法稍有不同。
13.2.临时表的创建、使用和删除
13.2.1.SQL Server
创建:
方式一:
#会话临时表 CREATE TABLE #临时表名( 字段1 约束条件1, 字段2 约束条件2, ... ); #全局临时表 CREATE TABLE ##临时表名( 字段1 约束条件, 字段2 约束条件, ... );
方式二:
#会话临时表 SELECT 字段列表 INTO #临时表名 FROM 业务表; #全局临时表 SELECT 字段列表 INTO ##临时表名 FROM 业务表;
使用:
#查询临时表 SELECT * FROM #临时表名; SELECT * FROM ##临时表名;
删除:
#删除临时表 DROP TABLE #临时表名; DROP TABLE ##临时表名;
13.2.2.Mysql
创建:
Mysql中没有全局临时表,创建的时候没有#
CREATE TEMPORARY TABLE [IF NOT EXISTS] 临时表名( 字段1 约束条件, 字段2 约束条件, ... ); #根据现有表创建临时表 CREATE TEMPORARY TABLE [IF NOT EXISTS] 临时表名 [AS] SELECT 查询字段 FROM 业务表 [WHERE 条件];
使用:
创建的临时表可以和业务表同名,若临时表和业务表同名时在该会话中会使用临时表
SELECT * FROM 临时表名;
删除:
为避免临时表名和业务表名相同时导致误删除,可以加上TEMPORARY关键字
DROP [TEMPORARY] TABLE 临时表名;
13.2.3.Oracle
Oracle的临时表也只有会话级的,但同时又细化出了一个事务级别的临时表,事务级别的临时表只在当前事务中有效。
创建:
#会话级别 CREATE GLOBAL TEMPORARY TABLE 临时表名( 字段1 约束条件, 字段2 约束条件, ... ) ON COMMIT PRESERVE ROWS; #事务级别 CREATE GLOBAL TEMPORARY TABLE 临时表名( 字段1 约束条件, 字段2 约束条件, ... ) ON COMMIT DELETE ROWS;
使用:
SELECT * FROM 临时表名;
删除:
DROP TABLE 临时表名;
注意:一个SQL中不能同时出现两次临时表
13.3.临时表的应用
企业开发中大多都是使用Spring进行事务管理的,很少自己开启事务、提交事务。我们大多都会将事务加在service层,这样在调用service层的每一个方法之前Spring都会为我们开启事务,在方法调用结束之后Spring会为我们提交事务,问题是数据库事务需要的数据库连接是在什么时候获取和释放的呢?这个是会影响我们对临时表的使用的。
一般来说,数据库连接是在事务开启之前获取的,也就是在我们调用事务方法之前,肯定要先获取数据库连接,然后才能开启事务,提交或回滚事务,然后关闭数据库连接,这种情况下貌似如果我们在该方法中创建了临时表,则在此之后直至方法结束之前我们都可以使用这个创建的临时表,这么说基本上是正确的。但有一种情况除外那就是如果我们在事务方法A中调用了另一个事务方法B,而事务方法B的事务传播机制是PROPAGATION_REQUIRES_NEW(将原事务挂起,并新开一个事务)时,如果临时表是在B方法中创建的,则A在调用完B之后(B的事务已经提交了)也不可以使用B中创建的事务级别的临时表,但是可以使用会话级别的临时表以及全局临时表。
三.SQL语句提升
1.复制表
(只复制结构,源表名:a 新表名:b) (Access可用)
法一:select * into b from a where 11(仅用于SQlServer) 法二:select top 0 * into b from a
2.拷贝表
(拷贝数据,源表名:a 目标表名:b) (Access可用)
insert into b(a, b, c) select d,e,f from a; --insert into b select * from a //从表a中获取数据,并将其插入到b中,只拷贝表的数据,不拷贝表的结构(前提:表b存在) --select * into b from a //将a中的数据拷贝到 b中,拷贝表的数据以及表的结构(前提:表b不存在) --select * into b from a where 1=0// 将a的表结构拷贝到b,不拷贝数据(前提:表b不存在)
3.跨数据库之间表的拷贝
(具体数据使用绝对路径) (Access可用)
insert into b(a, b, c) select d,e,f from b in ‘具体数据库’ where 条件
例子:..from b in '"&Server.MapPath(".")&"data.mdb" &"' where..
4.子查询
(表名1:a 表名2:b)
select a,b,c from a where a IN (select d from b ) 或者: select a,b,c from a where a IN (1,2,3)
5.显示文章、提交人和最后回复时间
select a.title,a.username,b.adddate from table a,(select max(adddate) adddate from table where table.title=a.title) b
6.外连接查询
(表名1:a 表名2:b)
select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUT JOIN b ON a.a = b.c
7.在线视图查询
(表名1:a )
select * from (SELECT a,b,c FROM a) T where t.a > 1;
8.between的用法
between限制查询数据范围时包括了边界值,not between不包括
select * from table1 where time between time1 and time2select a,b,c, from table1 where a not between 数值1 and 数值2
9.in 的使用方法
select * from table1 where a [not] in (‘值1’,’值2’,’值4’,’值6’)
10.两张关联表,删除主表中已经在副表中没有的信息
delete from table1 where not exists ( select * from table2 where table1.field1=table2.field1 )
11.四表联查问题
select * from a left inner join b on a.a=b.b right inner join c on a.a=c.c inner join d on a.a=d.d where .....
12.日程安排提前五分钟提醒
SQL: select * from 日程安排 where datediff('minute',f开始时间,getdate())>5
13.一条sql 语句搞定数据库分页
select top 10 b.* from (select top 20 主键字段,排序字段 from 表名 order by 排序字段 desc) a,表名 b where b.主键字段 = a.主键字段 order by a.排序字段
具体实现:
关于数据库分页:
declare @start int,@end int @sql nvarchar(600) set @sql=’select top’+str(@end-@start+1)+’+from T where rid not in(select top’+str(@str-1)+’Rid from T where Rid>-1)’ exec sp_executesql @sql
**注意:**在top后不能直接跟一个变量,所以在实际应用中只有这样的进行特殊的处理。Rid为一个标识列,如果top后还有具体的字段,这样做是非常有好处的。因为这样可以避免 top的字段如果是逻辑索引的,查询的结果后实际表中的不一致(逻辑索引中的数据有可能和数据表中的不一致,而查询时如果处在索引则首先查询索引)
14.前10条记录
select top 10 * form table1 where 范围
15.随机取出10条数据
select top 10 * from tablename order by newid()
16.随机选择记录
select newid()
17.删除重复记录
1),delete from tablename where id not in (select max(id) from tablename group by col1,col2,...) 2),select distinct * into temp from tablename delete from tablename insert into tablename select * from temp
评价: 这种操作牵连大量的数据的移动,这种做法不适合大容量的数据操作
**例如:**在一个外部表中导入数据,由于某些原因第一次只导入了一部分,但很难判断具体位置,这样只有在下一次全部导入,这样也就产生好多重复的字段,怎样删除重复字段
alter table tablename--添加一个自增列 add column_b int identity(1,1) delete from tablename where column_b not in(select max(column_b) from tablename group by column1,column2,...) alter table tablename drop column column_b
18.列出数据库里所有的表名
select name from sysobjects where type='U' // U代表用户
19.列出表里的所有的列名
select name from syscolumns where id=object_id('TableName')
20.初始化表table1
TRUNCATE TABLE table1
21.选择从10到15的记录
select top 5 * from (select top 15 * from table order by id asc) table_别名 order by id des
四、开发技巧
1、where 1=1是表示选择全部,where 1=2全部不选
if @strWhere !='' begin set @strSQL = 'select count(*) as Total from [' + @tblName + '] where ' + @strWhere end else begin set @strSQL = 'select count(*) as Total from [' + @tblName + ']' end
我们可以直接写成
set @strSQL = 'select count(*) as Total from [' + @tblName + '] where 1=1 '+ @strWhere
2、收缩数据库
--重建索引 DBCC REINDEX DBCC INDEXDEFRAG --收缩数据和日志 DBCC SHRINKDB DBCC SHRINKFILE
3、压缩数据库
dbcc shrinkdatabase(dbname)
4、转移数据库给新用户以已存在用户权限
exec sp_change_users_login 'update_one','newname','oldname' go
5、检查备份集
RESTORE VERIFYONLY from disk='E:dvbbs.bak'
6、修复数据库
ALTER DATABASE [dvbbs] SET SINGLE_USER
GO
DBCC CHECKDB('dvbbs',repair_allow_data_loss) WITH TABLOCK
GO
ALTER DATABASE [dvbbs] SET MULTI_USER
GO
7、日志清除
SET NOCOUNT ONDECLARE @LogicalFileName sysname, @MaxMinutes INT, @NewSize INT USE tablename -- 要操作的数据库名 SELECT @LogicalFileName = 'tablename_log', -- 日志文件名 @MaxMinutes = 10, -- Limit on time allowed to wrap log. @NewSize = 1 -- 你想设定的日志文件的大小(M) Setup / initialize DECLARE @OriginalSize int SELECT @OriginalSize = size FROM sysfiles WHERE name = @LogicalFileName SELECT 'Original Size of ' + db_name() + ' LOG is ' + CONVERT(VARCHAR(30),@OriginalSize) + ' 8K pages or ' + CONVERT(VARCHAR(30),(@OriginalSize*8/1024)) + 'MB' FROM sysfiles WHERE name = @LogicalFileName CREATE TABLE DummyTrans (DummyColumn char (8000) not null) DECLARE @Counter INT, @StartTime DATETIME, @TruncLog VARCHAR(255) SELECT @StartTime = GETDATE(), @TruncLog = 'BACKUP LOG ' + db_name() + ' WITH TRUNCATE_ONLY' DBCC SHRINKFILE (@LogicalFileName, @NewSize) EXEC (@TruncLog) -- Wrap the log if necessary. WHILE @MaxMinutes > DATEDIFF (mi, @StartTime, GETDATE()) -- time has not expired AND @OriginalSize = (SELECT size FROM sysfiles WHERE name = @LogicalFileName) AND (@OriginalSize * 8 /1024) > @NewSize BEGIN -- Outer loop. SELECT @Counter = 0 WHILE ((@Counter <p><strong>8、更改某个表</strong></p><pre class="brush:php;toolbar:false">exec sp_changeobjectowner 'tablename','dbo'
9、存储更改全部表
CREATE PROCEDURE dbo.User_ChangeObjectOwnerBatch @OldOwner as NVARCHAR(128), @NewOwner as NVARCHAR(128) AS DECLARE @Name as NVARCHAR(128) DECLARE @Owner as NVARCHAR(128) DECLARE @OwnerName as NVARCHAR(128) DECLARE curObject CURSOR FOR select 'Name' = name, 'Owner' = user_name(uid) from sysobjects where user_name(uid)=@OldOwner order by name OPEN curObject FETCH NEXT FROM curObject INTO @Name, @Owner WHILE(@@FETCH_STATUS=0) BEGIN if @Owner=@OldOwner begin set @OwnerName = @OldOwner + '.' + rtrim(@Name) exec sp_changeobjectowner @OwnerName, @NewOwner end -- select @name,@NewOwner,@OldOwner FETCH NEXT FROM curObject INTO @Name, @Owner END close curObject deallocate curObject GO
10、SQL SERVER中直接循环写入数据
declare @i int set @i=1 while @i<p>案例:有如下表,要求就裱中所有沒有及格的成績,在每次增長0.1的基礎上,使他們剛好及格:</p><p>Name score</p><p>Zhangshan 80</p><p>Lishi 59</p><p>Wangwu 50</p><p>Songquan 69</p><pre class="brush:php;toolbar:false">while((select min(score) from tb_table)60 break else continue end
五、数据开发-经典
1.按姓氏笔画排序:
Select * From TableName Order By CustomerName Collate Chinese_PRC_Stroke_ci_as //从少到多
2.数据库加密:
select encrypt('原始密码')
select pwdencrypt('原始密码')
select pwdcompare('原始密码','加密后密码') = 1--相同;否则不相同 encrypt('原始密码')
select pwdencrypt('原始密码')
select pwdcompare('原始密码','加密后密码') = 1--相同;否则不相同3.取回表中字段:
declare @list varchar(1000), @sql nvarchar(1000) select @list=@list+','+b.name from sysobjects a,syscolumns b where a.id=b.id and a.name='表A' set @sql='select '+right(@list,len(@list)-1)+' from 表A' exec (@sql)
4.查看硬盘分区:
EXEC master..xp_fixeddrives
5.比较A,B表是否相等:
if (select checksum_agg(binary_checksum(*)) from A) = (select checksum_agg(binary_checksum(*)) from B) print '相等' else print '不相等'
6.杀掉所有的事件探察器进程:
DECLARE hcforeach CURSOR GLOBAL FOR SELECT 'kill '+RTRIM(spid) FROM master.dbo.sysprocesses
WHERE program_name IN('SQL profiler',N'SQL 事件探查器')
EXEC sp_msforeach_worker '?'7.记录搜索:
开头到N条记录
Select Top N * From 表-------------------------------
N到M条记录(要有主索引ID)
Select Top M-N * From 表 Where ID in (Select Top M ID From 表) Order by ID Desc
----------------------------------
N到结尾记录
Select Top N * From 表 Order by ID Desc
案例:
例如1:一张表有一万多条记录,表的第一个字段 RecID 是自增长字段, 写一个SQL语句, 找出表的第31到第40个记录。
select top 10 recid from A where recid not in(select top 30 recid from A)
分析:如果这样写会产生某些问题,如果recid在表中存在逻辑索引。
select top 10 recid from A where……是从索引中查找,而后面的select top 30 recid from A则在数据表中查找,这样由于索引中的顺序有可能和数据表中的不一致,这样就导致查询到的不是本来的欲得到的数据。
解决方案
1,用order by select top 30 recid from A order by ricid 如果该字段不是自增长,就会出现问题
**2,**在那个子查询中也加条件:select top 30 recid from A where recid>-1
**例2:查询表中的最后以条记录,并不知道这个表共有多少数据,以及表结构。
set @s = 'select top 1 * from T where pid not in (select top ' + str(@count-1) + ' pid from T)' print @s exec sp_executesql @s
9:获取当前数据库中的所有用户表
select Name from sysobjects where xtype=‘u’ and status>=0
10:获取某一个表的所有字段
select name from syscolumns where id=object_id(‘表名’)
select name from syscolumns where id in (select id from sysobjects where type = ‘u’ and name = ‘表名’)
两种方式的效果相同
11:查看与某一个表相关的视图、存储过程、函数
select a.* from sysobjects a, syscomments b where a.id = b.id and b.text like ‘%表名%’
12:查看当前数据库中所有存储过程
select name as 存储过程名称 from sysobjects where xtype='P’
13: Query all databases created by the user
select * from master…sysdatabases D where sid not in(select sid from master…syslogins where name='sa')
or
select dbid, name AS DB_NAME from master…sysdatabases where sid 0x01
14: Query the fields and data of a certain table Type
select column_name,data_type from information_schema.columns
where table_name = 'table name'
15: Between different server databases Data operations
–Create a linked server
exec sp_addlinkedserver 'ITSV ', ' ', 'SQLOLEDB ', 'Remote server name or ip address'
exec sp_addlinkedsrvlogin 'ITSV ', 'false ',null, 'username', 'password'
–Query example
select * from ITSV.Database name.dbo.Table name
–Import example
select * into Table from ITSV.Database name.dbo.Table name
–Delete the linked server when no longer in use
exec sp_dropserver 'ITSV ', 'droplogins '
–Connect remote/LAN data(openrowset/openquery/opendatasource)
–1, openrowset
–Query example
select * from openrowset( 'SQLOLEDB ', 'sql server name'; 'user name'; 'password', database name.dbo. Table name)
–Generate local table
select * into table from openrowset( 'SQLOLEDB ', 'sql server name'; 'User name'; 'Password', database name.dbo.table name)
--Insert the local table into the remote table
insert openrowset( ' SQLOLEDB ', 'sql server name'; 'user name'; 'password', database name.dbo.table name)
select *from local table
–Update local table
update b
set b.Column A=a.Column A
from openrowset( 'SQLOLEDB ', 'sql server name'; 'user name'; 'password', database name.dbo.table name) as a inner join local table b
on a.column1=b.column1
**
**
–2. Openquery usage requires creating a connection
–First create a connection to create a linked server
exec sp_addlinkedserver 'ITSV ', ' ', 'SQLOLEDB ', 'Remote server name or ip address'
–Query
select *
##FROM openquery(ITSV, 'SELECT * FROM database.dbo .Table name')
– Import the local table into the remote table
insert openquery(ITSV, 'SELECT * FROM database.dbo.table Name')
select * from local table
–Update local table
update b
set b.Column B=a.Column B
FROM openquery(ITSV, 'SELECT * FROM database.dbo.Table name') as a
inner join local table b on a.Column A=b.Column A
–3, opendatasource/openrowset
SELECT *
##FROM opendatasource( 'SQLOLEDB ', 'Data Source=ip/ServerName;User ID=Login Name;Password=Password' ).test.dbo .roy_ta– Import the local table into the remote table
insert opendatasource( 'SQLOLEDB ', 'Data Source=ip/ServerName;User ID =Login name;Password=Password').Database.dbo.Table name
select * from local table
SQL Server basic functions
6. SQL Server Basic Functions
1. String function length and analysis use
1,datalength(Char_expr) returns the string containing the number of characters, but not Including the following spaces
2, substring(expression,start,length) takes the substring, the **** subscript of the string is from "1", and start is the starting position , length is the length of the string. In actual applications, len(expression) is used to obtain the length
3,right(char_expr,int_expr) returns the int_expr character on the right side of the string, and also uses left On the contrary
4,isnull(check_ex*****pression*, *replacement_value*)If check_expression is empty, the value of replacement_value is returned. If it is not empty, check_expression is returned. Character operation class
5,Sp_addtypeCustomized data type For example: EXEC sp_addtype birthday, datetime, 'NULL'
Causes the returned results to exclude information about the number of rows affected by the Transact-SQL statement. If the stored procedure contains statements that do not return much actual data, this setting can significantly improve performance by significantly reducing network traffic. The SET NOCOUNT setting is set at execution or run time, not at parse time. When SET NOCOUNT is ON, no count (indicating the number of rows affected by the Transact-SQL statement) is returned. When SET NOCOUNT is OFF, common sense of counting is returned Common sense Recommended study: "SQL Tutorial"
In SQL query: the maximum number of tables or views that can be followed by from: 256
When Order by appears in the SQL statement, when querying, first Sort, then take
In SQL, the maximum capacity of a field is 8000, and for nvarchar (4000), since nvarchar is a Unicode code.
In SQL query: the maximum number of tables or views that can be followed by from: 256
When Order by appears in the SQL statement, when querying, sort first, Take
after that. In SQL, the maximum capacity of a field is 8000, and for nvarchar(4000), since nvarchar is a Unicode code
The above is the detailed content of Summarize SQL statement knowledge points. For more information, please follow other related articles on the PHP Chinese website!

 SQL Server使用CROSS APPLY与OUTER APPLY实现连接查询Aug 26, 2022 pm 02:07 PM
SQL Server使用CROSS APPLY与OUTER APPLY实现连接查询Aug 26, 2022 pm 02:07 PM本篇文章给大家带来了关于SQL的相关知识,其中主要介绍了SQL Server使用CROSS APPLY与OUTER APPLY实现连接查询的方法,文中通过示例代码介绍的非常详细,下面一起来看一下,希望对大家有帮助。
 SQL Server解析/操作Json格式字段数据的方法实例Aug 29, 2022 pm 12:00 PM
SQL Server解析/操作Json格式字段数据的方法实例Aug 29, 2022 pm 12:00 PM本篇文章给大家带来了关于SQL server的相关知识,其中主要介绍了SQL SERVER没有自带的解析json函数,需要自建一个函数(表值函数),下面介绍关于SQL Server解析/操作Json格式字段数据的相关资料,希望对大家有帮助。
 聊聊优化sql中order By语句的方法Sep 27, 2022 pm 01:45 PM
聊聊优化sql中order By语句的方法Sep 27, 2022 pm 01:45 PM如何优化sql中的orderBy语句?下面本篇文章给大家介绍一下优化sql中orderBy语句的方法,具有很好的参考价值,希望对大家有所帮助。
 Monaco Editor如何实现SQL和Java代码提示?May 07, 2023 pm 10:13 PM
Monaco Editor如何实现SQL和Java代码提示?May 07, 2023 pm 10:13 PMmonacoeditor创建//创建和设置值if(!this.monacoEditor){this.monacoEditor=monaco.editor.create(this._node,{value:value||code,language:language,...options});this.monacoEditor.onDidChangeModelContent(e=>{constvalue=this.monacoEditor.getValue();//使value和其值保持一致i
 一文搞懂SQL中的开窗函数Sep 02, 2022 pm 04:55 PM
一文搞懂SQL中的开窗函数Sep 02, 2022 pm 04:55 PM本篇文章给大家带来了关于SQL server的相关知识,开窗函数也叫分析函数有两类,一类是聚合开窗函数,一类是排序开窗函数,下面这篇文章主要给大家介绍了关于SQL中开窗函数的相关资料,文中通过实例代码介绍的非常详细,需要的朋友可以参考下。
 如何使用exp进行SQL报错注入May 12, 2023 am 10:16 AM
如何使用exp进行SQL报错注入May 12, 2023 am 10:16 AM0x01前言概述小编又在MySQL中发现了一个Double型数据溢出。当我们拿到MySQL里的函数时,小编比较感兴趣的是其中的数学函数,它们也应该包含一些数据类型来保存数值。所以小编就跑去测试看哪些函数会出现溢出错误。然后小编发现,当传递一个大于709的值时,函数exp()就会引起一个溢出错误。mysql>selectexp(709);+-----------------------+|exp(709)|+-----------------------+|8.218407461554972
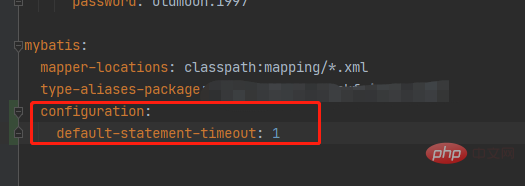 springboot配置mybatis的sql执行超时时间怎么解决May 15, 2023 pm 06:10 PM
springboot配置mybatis的sql执行超时时间怎么解决May 15, 2023 pm 06:10 PM当某些sql因为不知名原因堵塞时,为了不影响后台服务运行,想要给sql增加执行时间限制,超时后就抛异常,保证后台线程不会因为sql堵塞而堵塞。一、yml全局配置单数据源可以,多数据源时会失效二、java配置类配置成功抛出超时异常。importcom.alibaba.druid.pool.DruidDataSource;importcom.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceBuilder;importorg.apache.
 Monaco Editor怎么实现SQL和Java代码提示May 11, 2023 pm 05:31 PM
Monaco Editor怎么实现SQL和Java代码提示May 11, 2023 pm 05:31 PMmonacoeditor创建//创建和设置值if(!this.monacoEditor){this.monacoEditor=monaco.editor.create(this._node,{value:value||code,language:language,...options});this.monacoEditor.onDidChangeModelContent(e=>{constvalue=this.monacoEditor.getValue();//使value和其值保持一致i


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SublimeText3 Linux new version
SublimeText3 Linux latest version

WebStorm Mac version
Useful JavaScript development tools

Dreamweaver CS6
Visual web development tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

SublimeText3 Chinese version
Chinese version, very easy to use

